

When little Googlebot is tucked into bed at night and thinks about what he will do when he is all grown up, he only has one wish: he wants to be super smart. He wants to understand what elements make up a website, what use all these numbers and letters have and in which context they stand to each other. But sadly, and here we have to be totally honest with the little Googlebot, he has only made limited progress over the past ten years.
Luckily, there are learning aides for the struggling crawler: the structured markup of specific data-types in the HTML source code. Ever since Sergey Brin and Larry Page, Googlebot’s loving parents, started displaying structured data in Google’s results and subtly spread the rumour that websites with this markup will rank better, it has become more common for Googlebot to be able to find and process data with this markup.
What we wanted to know is how widespread structured data already is on the web. For that we have the SISTRIX Crawler. It has looked at roughly 65 billion URLs of late (65.650.465.110 to be exact) and also checked whether the pages had any structured data on them, according to the schema.org-markup. That is the data basis for the following evaluation. Here it is:
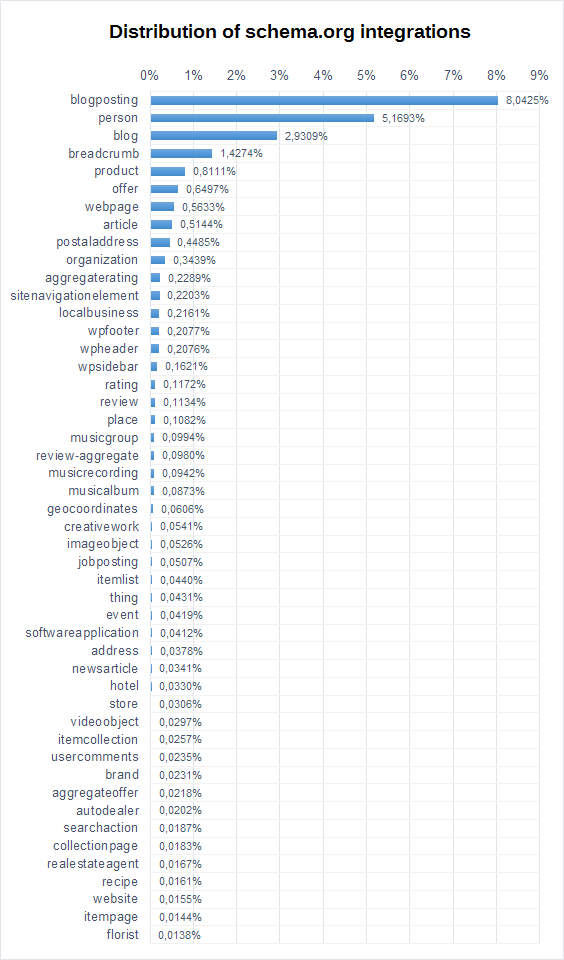
There are four types that show up for more than 1 percent of all crawled URLs. Both blogposting and blogs are so well represented because the big bloghosting services like blogger.com & blogspot.com (both owned by Google) already support this markup. Person, as a schema.org-type is in close relation to the former: Google also uses this markup intensively, for example on all GooglePlus sites. We can likely expect the popularity of breadcrumb to be a result of Google using this markup to show a nice click-path within the search results. Having numerous free and simple plugins for free Content Management Systems (CMS), like WordPress, is surely not hurting either.
In summary, it can be said that the structured data markup is surprisingly well evolved. Numerous standard software solutions already integrate the necessary markup from the get-go. That this may not always be an advantage (for an industry) apparently still has not made the rounds. Lucky for Googlebot.