
The main reason to avoid dates within your directory structure is explained on page number 8 of the Google’s Search Engine Optimization Starter Guide:
Simple-to-understand URLs will convey content information easily
Creating descriptive categories and filenames for the documents on your website can not only help you keep your site better organized, but it could also lead to better crawling of your documents by search engines. Also, it can create easier, “friendlier” URLs for those that want to link to your content. Visitors may be intimidated by extremely long and cryptic URLs that contain few recognizable words.
If the dates constitute a really relevant piece of information for the user, I would keep them. For all other cases I would advice against them, as in doing so, you are likely going to kill your content on Google.
What would work better for search engines and their users? /2013/dec/05/ or just /Nelson_Mandela
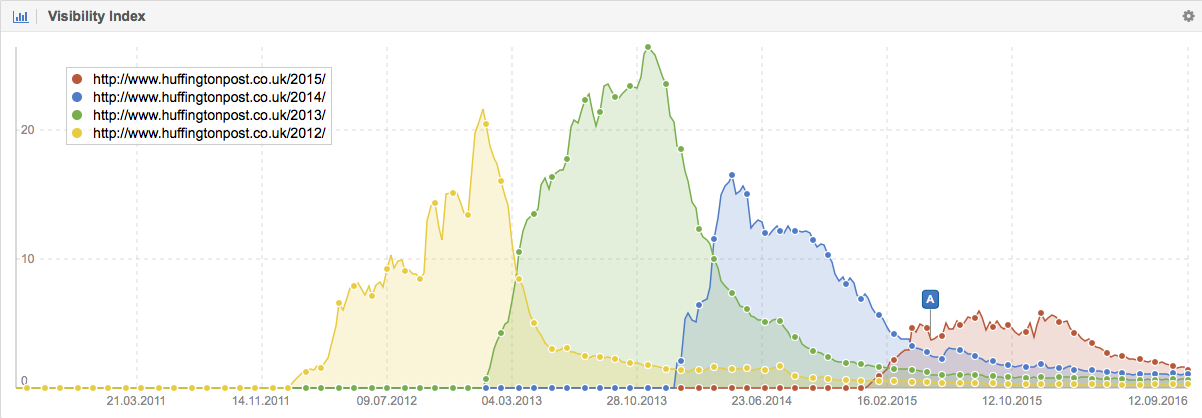
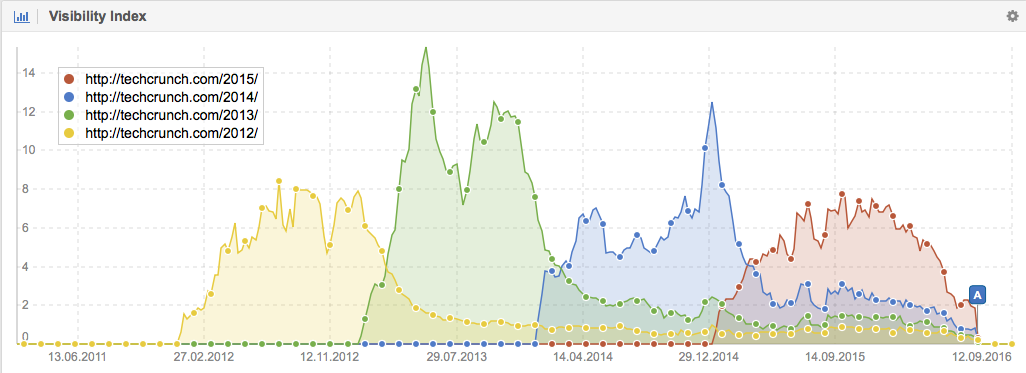
The Huffingtonpost.co.uk has created much more content about Nelson Mandela than the Wikipedia. For example, I was able to find 29 individual news articles for the Huffingtonpost.co.uk that use Nelson Mandela within the URL. Interestingly enough none of them rank on the first page of Google’s search results.
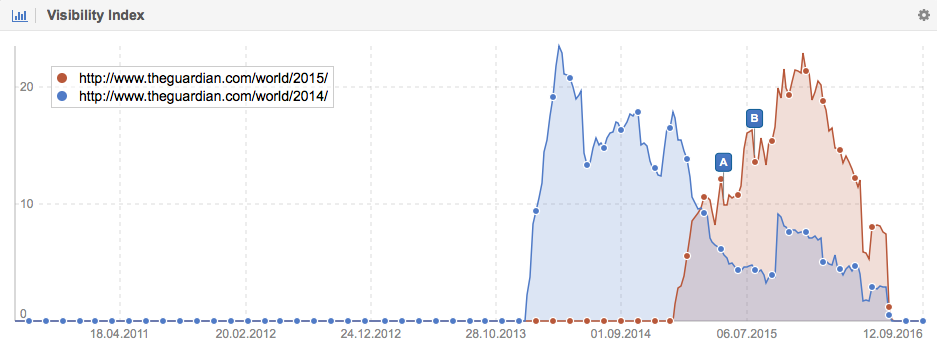
For Theguardian.com I even found 443 individual news items that use Nelson Mandela in their URL. Here, only 27 URLs rank in the top 10 and all of them are long tail keywords, which usually have a very low traffic volume. The content on Theguardian.com might very well be more reliable and verified than that on the Wikipedia, but that will not help you if you cannot find it on Google because every piece of content on /world/2014/ and /world/2015/ does not rank well anymore:
If you search for Nelson Mandela on Google.co.uk we quickly notice that nine of the results use user-friendly URLs. You have the Wikipedia at position number 2, a piece of archived content by the BBC at position number 4 and Theguardian.com at position Number 10 (actually 11), within the “related news box” – which is not the same as Google’s “In the news” vertical:
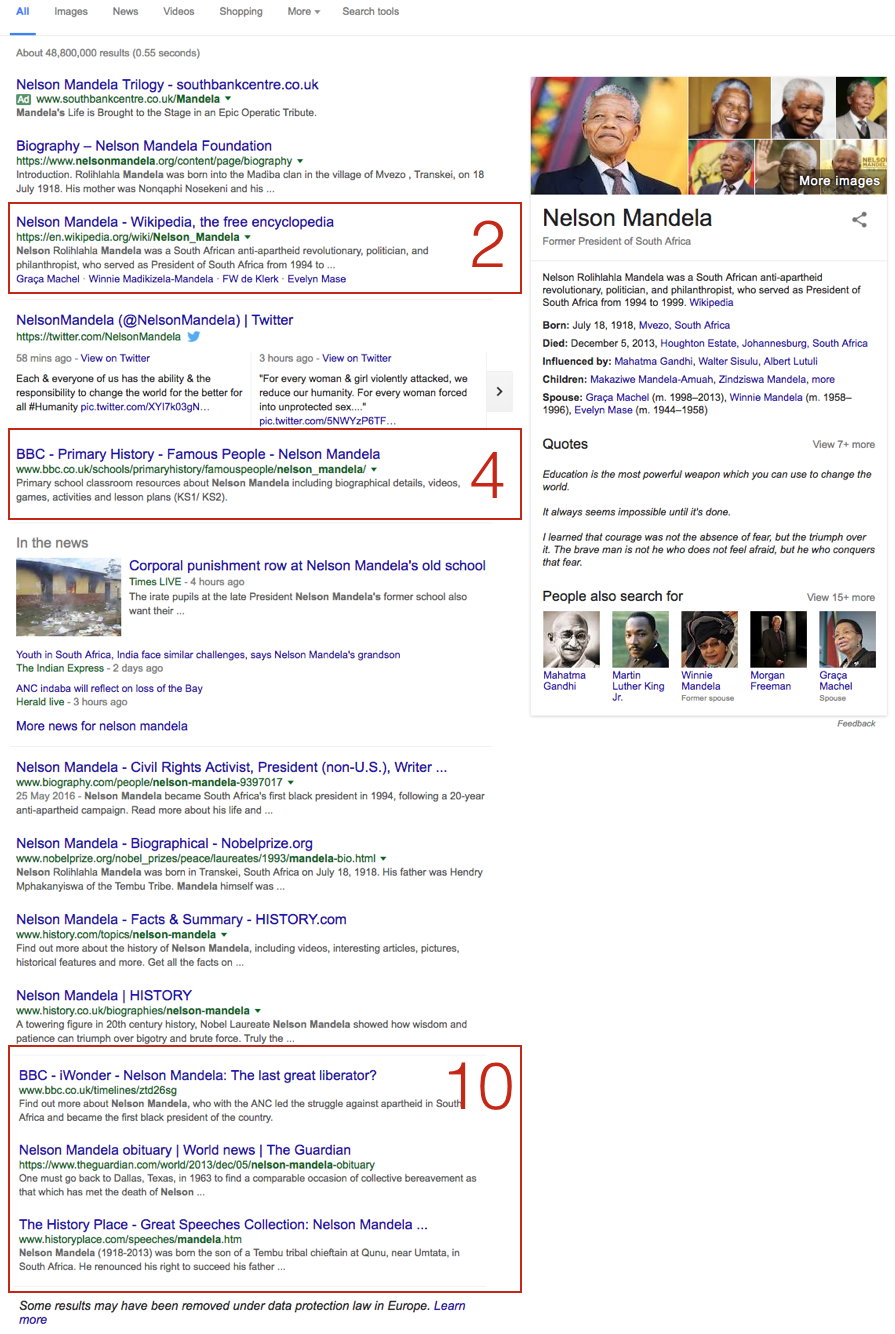
Having the Date in the URL is not the cause for the losses but a symptom of a weak information architecture. Both the Wikipedia and the BBC articles rank better than TheGuardian, not only because the URL suggest what the content is about but because the content is useful and timeless.
Don’t benchmark within your industry
One of the patterns of the news and information industry is that they all tend to do things similarily. Even the way they handle their information is almost identical, just like a printed journal. All the resources invested in research and editorial work disappear on Google after one year. Content that you have already paid for must not necessary be lost on Google after such a short time.
It is natural that fast lived news tend to fade but the same could be said of fashion trends – and online shops can deal with those very well. The number of topics that a journal will use, like Nelson Mandela, James Cameron, Hillary Clinton, Brexit, etc., are quantifiable because they are almost always the same, just like general product categories for e-commerce sites.
Wikipedia has 5 million articles for their English version (not topics!) and can deal with the above problem well. When we look at e-commerce sites it gets even crazier. Amazon, for example, has to deal with 60 million different accessories just within their Electronics and Photo category. This should give you a good idea that, if you really want to, you can indeed deal with a very large amount of topics/products.
The Search Result number 10
I asked John Muller in a German Hangout on February 25, 2016, why the search result number 10 is composed by 3 different snippets. He told us, it is just a sort of “Related News Box“.
The Theguardian’s search result for the keyword “Nelson Mandela“ is their obituary. We really are talking about a very good, high quality obituary here, which, in my opinion, is much better than the corresponding part on the Wikipedia. I have another very good example for amazing content: Just search for “greenland“ on Google US and you will probably find this:
Journals are able to create great content. Just click on the search results for the Nytimes.com and Rollingstone.com. Next let us take a look at the history of the keyword “melting glaciers” for the Nytimes.com:
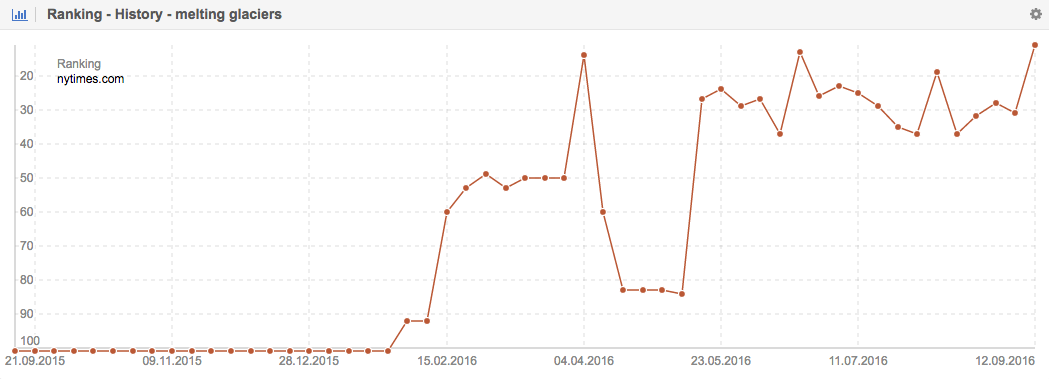
Compared to the general downward Visibility trend for news items, we can see that this article has had its ups and downs but now ranks within the Top10 – actually for a total of 36 keywords related to “greenland” and “melting glaciers”. All 3 snippets for this keyword, within the “related news box”, are very good alternatives to the Wikipedia. It is not healthy for information seekers to get the Wikipedia as the only source of information.
Lastly, would you have ever imagined that Rollingstone.com would compete with the Nytimes.com and Nature.com on a topic such as melting glaciers? This Rollingstone’s article has a simple-to-understand URL, as well as timeless and and great content.
I hope you like it!
