
A source cited in an AI response today may well have disappeared by next week. Our analysis of 82,619 prompts over 17 weeks shows that Google replaces 56% of sources in AI-generated responses every week, whilst ChatGPT replaces as much as 74%. In this article, we will explain who stays, who disappears, and why it is problematic that the three major platforms actually have very little in common.
- The 5 key findings
- Three platforms, three citation architectures
- Google AI Overviews: the closed circle
- Google AI Mode: few stay, many switch out
- ChatGPT Search: total fluctuation
- The brand domain remains, the rest rotates
- Which domain types survive the Citation Drift?
- Google AI Mode: a clear hierarchy
- ChatGPT: no clear hierarchy
- What will survive? URL classification
- Every platform cites different sources
- Domain-Level vs. URL-Level: our numbers are conservative
- Citation Drift is global
- What does this mean for GEO?
- Data basis
Since mid-2025, the term ‘AI Citation Drift’ has been used to discuss just how stable AI citations actually are. This debate was sparked by a Profound study focusing on monthly shifts in the US market. We took a closer look at the issue using SISTRIX data, covering three platforms, six countries and 17 weeks.
The 5 key findings
- Every AI Mode response has a fixed core and a carousel. For 86% of all prompts, there is a stable core comprising a few domains; the rest rotates at a rate of 89% per week. So the question with GEO is not “am I in the response?”, but “am I in the core or in the carousel?”.
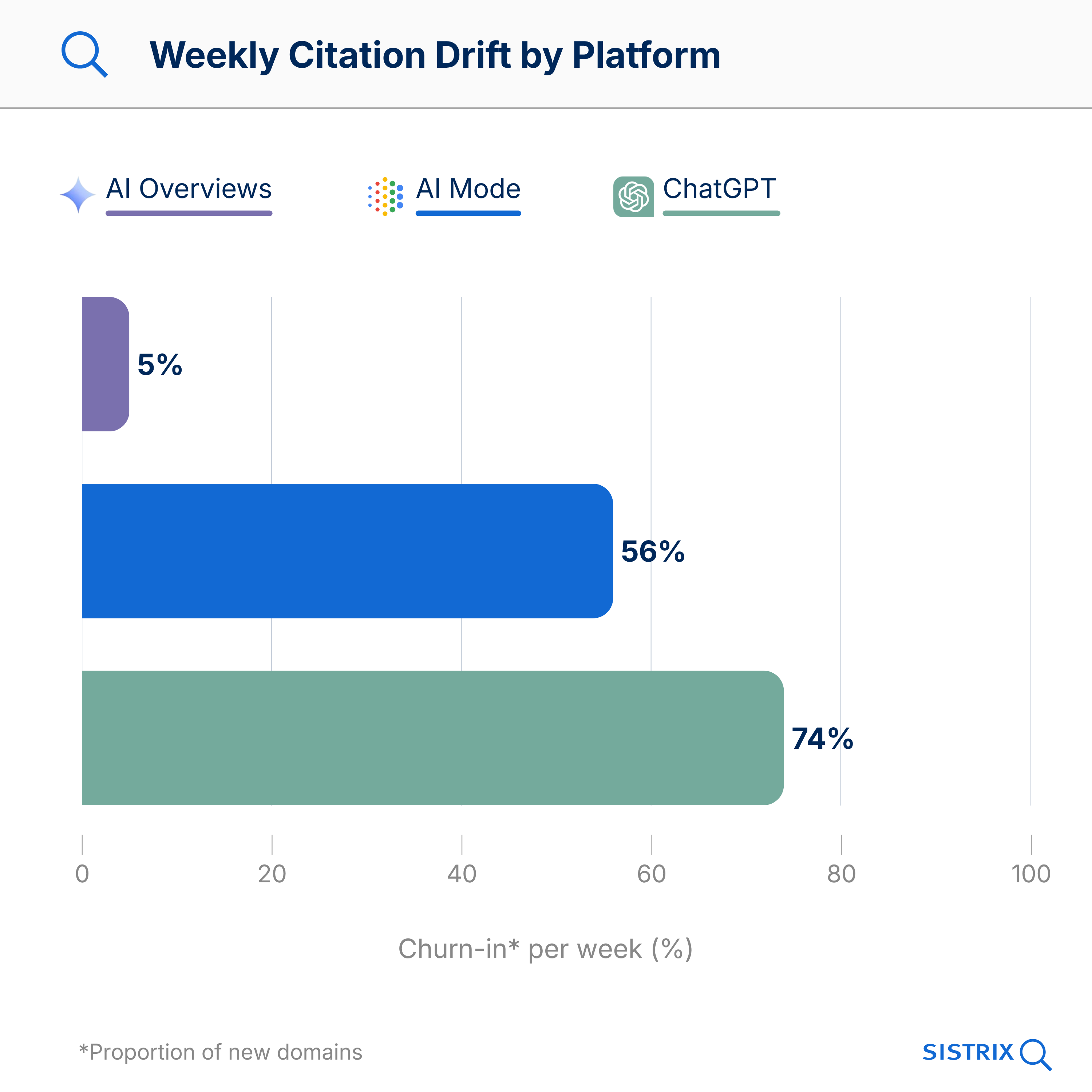
- Three platforms, three architectures. AI Overviews are completely stable for just over half of queries; AI Mode responses rotate by 56% per week, and ChatGPT by 74%. Lumping the platforms together obscures more than it reveals.
- Brand domains are anchored. For 43% of brand queries, the brand’s own domain is present in all 17 weeks, whilst the co-citations alongside it rotate at a rate of 70% per week. Brands remain cited. Those standing alongside the brand will be replaced by another site next week.
- News is a one-way ticket. Only 1.4% of news articles cited as sources remain permanently in the citation set. Anyone planning their citation strategy around editorial news content is planning wrongly. Evergreen content systematically survives better.
- Citation drift is global and persistent. Drift rates remain consistently at 54–59% across six countries, showing no sign of levelling off over the 17-week period. This is not a temporary introductory effect that will fade away, but a structural feature of the platforms.
Three platforms, three citation architectures
The drift figures published so far for AI platforms are aggregated: one figure per platform, usually on a monthly basis. This is fine as a first approximation, but it hides more than it reveals. Google AI Overviews, Google AI Mode and ChatGPT Search operate in fundamentally different ways when it comes to citation selection, and an average figure lumps three different things together as one.
Terms:
- Churn-in describes how many of the domains cited in a given week are new, i.e. did not appear in the previous week.
- Retention describes how many of the domains from the previous week have carried over into the following week.
- Peripheral/Carousel refers to all domains in an AI response that do not belong to the stable core. They appear, disappear again and are replaced by others on a weekly basis.
- Core refers to the few domains in an AI response that remain permanently present. Their churn-in is virtually 0%: they are cited week after week, regardless of which other sources come and go.
Google AI Overviews: the closed circle
AI Overviews are the most stable of the three platforms. On average, 11 domains are cited, 8 of which remain consistently present. Whilst this may sound reassuring at first, the stability is unevenly distributed.
In 53% of all prompts, not a single source changes over 17 weeks. In 28%, there are isolated changes. And in 19%, the sources drift just as much as in AI Mode, with 46% churn-in. AI Overviews are therefore not uniformly stable, but split into a majority where nothing changes at all, and a minority where everything rotates.
We have verified that this is not a measurement artefact: for 87% of the stable prompts, the generated response text changes from week to week; only the cited domains remain identical. AI Overviews therefore write new sentences every week, but draw on the same eight sources. Once you’re in, you stay in. If you’re not in, you don’t get in either.
Example: For “019 agm battery start stop”, the AI Overviews cite exactly the same 11 domains over 12 weeks: advancedbatterysupplies.co.uk, batterycharged.co.uk, batterygroup.co.uk, batterystore.co.uk, as well as seven others. Zero movement. For “city break over Christmas”, on the other hand, the picture looks different every week. Presumably because the answer to “019 agm battery start stop” is less seasonal than the question “where to go at Christmas”.
Google AI Mode: few stay, many switch out
In the AI Mode, the picture is quite different. Each response cites 14–16 domains, 56% of which change every week. That sounds dramatic, and it is. But it’s worth taking a closer look: not all domains drift at the same rate.
86.5% of the prompts analysed have a stable core of 1–5 domains that remain present over weeks and months. By contrast, 89% of the remaining domains rotate on a weekly basis.
Example: For “1960s comics”, wikipedia.org remains in the core throughout the entire period. This comes as little surprise. Alongside Wikipedia, week 1 features blackgate.com, comicsalliance.com and journalofantiques.com. In week 2, all three are gone, replaced by ebsco.com, kirbymuseum.org, nsk.hr and qualitycomix.com. Wikipedia remains, whilst the others rotate.
Who forms the core? YouTube and Amazon are frequently represented, which comes as no surprise to anyone. More notably, in 83% of the prompts, at least one specialist domain is also part of the stable core. So it is not just the major platforms that come out on top.
And the whole thing is remarkably independent of the country:
| country | churn-in / week | retention / week | domains / answer |
|---|---|---|---|
| DE | 56% | 46% | 13.5 |
| US | 54% | 49% | 16.1 |
| UK | 54% | 49% | 15.7 |
| IT | 59% | 43% | 13.7 |
| ES | 56% | 44% | 11.8 |
| FR | 57% | 43% | 12.3 |
Churn-in and retention do not add up to 100% because they are based on different metrics. Churn-in asks: How many of today’s sources are new? Retention asks: How many of last week’s sources are still there? If, for example, a response had eight sources in one week and twelve in the next, the two figures have a different relationship to the total number.
ChatGPT Search: total fluctuation
ChatGPT Search takes things to the extreme. 74% of domains are new every week. Stable core structures are rare: the median prompt does not contain a single domain that appears in all 17 weeks. By comparison, in AI Mode, the median is around two stable core domains per prompt. There are certainly prompts in ChatGPT with stable sources, but they are the exception, not the rule.
What’s more, ChatGPT cites significantly fewer sources. On average, just 3-4 domains per response, compared to 14-16 in AI Mode. And here’s where it gets interesting: even for German search queries, 68% of ChatGPT Core’s sources are in English. Anyone in Germany who asks ChatGPT a question is, for the most part, served answers drawn from English-language sources.
Example: For the query ‘Are there free bible colleges?’, ChatGPT lists a total of 18 domains in Week 1, including bible.org, bibleproject.com, coursera.org, edx.org and ucumberlands.edu. In Week 2: five completely different ones (christianleadersinstitute.org, icscanada.edu, sbts.edu, tku.edu, youversion.com). In Week 3: another four different ones (liberty.edu, moody.edu, tku.edu, uofn.edu). Not a single overlap between Week 1 and the other two. The answer may sound plausible each week, but this has nothing to do with consistent use of sources.
The brand domain remains, the rest rotates
It comes as little surprise that a search for “bbc newsreaders female” ultimately leads to bbc.co.uk. What is more interesting is how consistently this happens, and what happens to the co-citations alongside it.
In Google AI Mode, the brand’s own domain appears in only 43% of brand queries across all 17 weeks. In the majority of cases, therefore, even the most obvious source eventually drops out of the citation set. For 66%, however, it remains in the set for at least 80% of the weeks. Brand queries drift 20% less than the average (45% vs. 56% churn-in), making them noticeably more stable, but not dramatically different.
The real pattern is revealed by the co-citations alongside it. Of the 12-15 other domains cited alongside the brand, 70% change each week. Strong brands therefore remain constant, whilst the space alongside them is reallocated on a weekly basis.
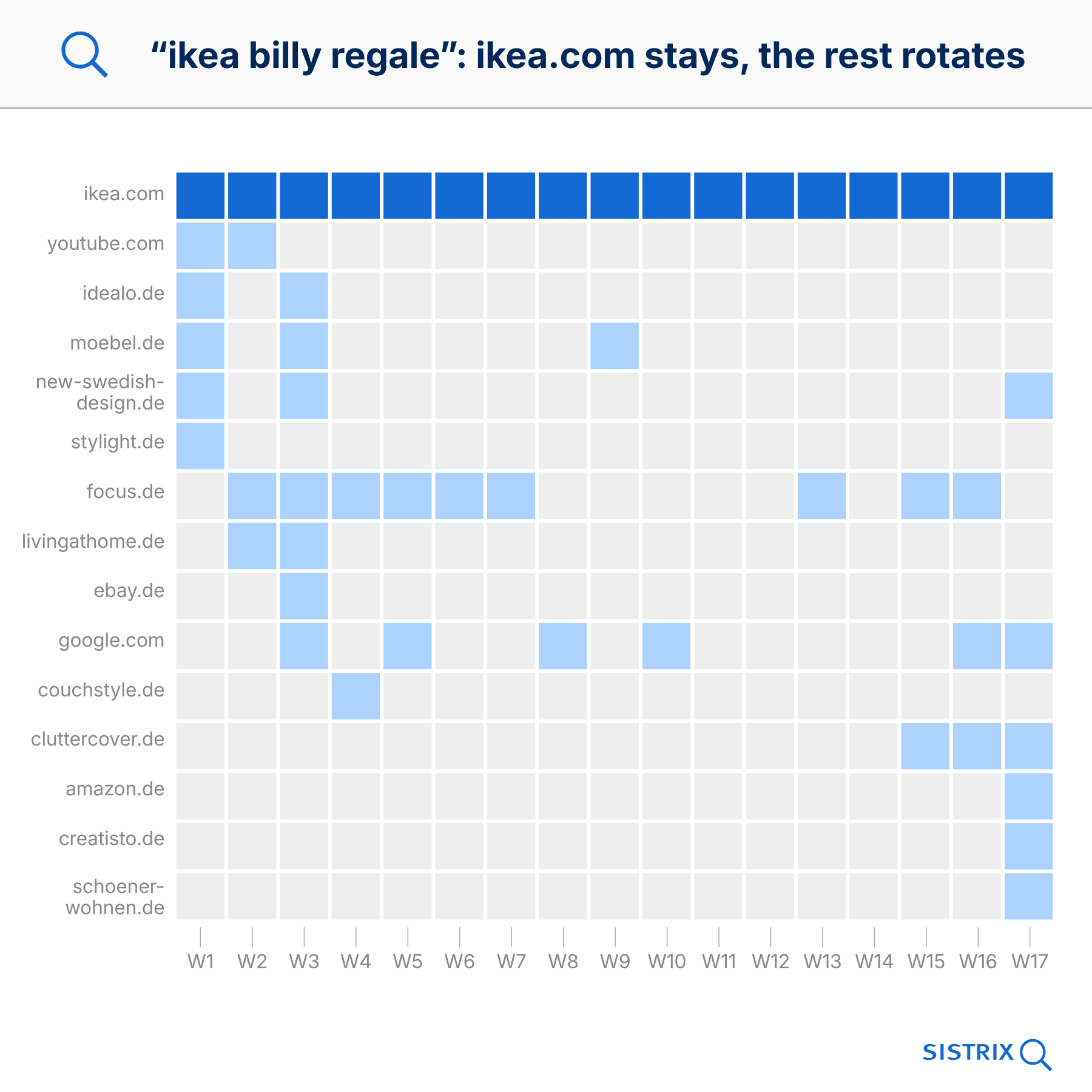
Example: For the search term ‘bbc newsreaders female’, bbc.co.uk appears in 13 out of 17 weeks. In week 1, it is joined by speakeragency.co.uk and wikipedia.org. In week 17, these are replaced by bbc.com and nmplive.co.uk. A complete change. Only bbc.co.uk remains.
If you want to know whether your domain belongs to the core or the periphery, you can check this directly in SISTRIX Prompt Tracking. To do this, you can use Prompt Research to define a set of prompts that are relevant to your brand. SISTRIX then checks daily whether and how often your brand appears in the AI systems’ responses, and which domains are cited as sources.
This makes it clear, for example, whether your own domain is permanently anchored in the citation set for your brand, or whether it appears and disappears on a weekly basis. SISTRIX for AI and chatbots is free for all accounts. If you’d like to give it a try, you can create a free trial account.
Which domain types survive the Citation Drift?
Not all page types are affected to the same extent. We have divided the domains mentioned into categories and looked at how often they make it into the stable core of a response.
Google AI Mode: a clear hierarchy
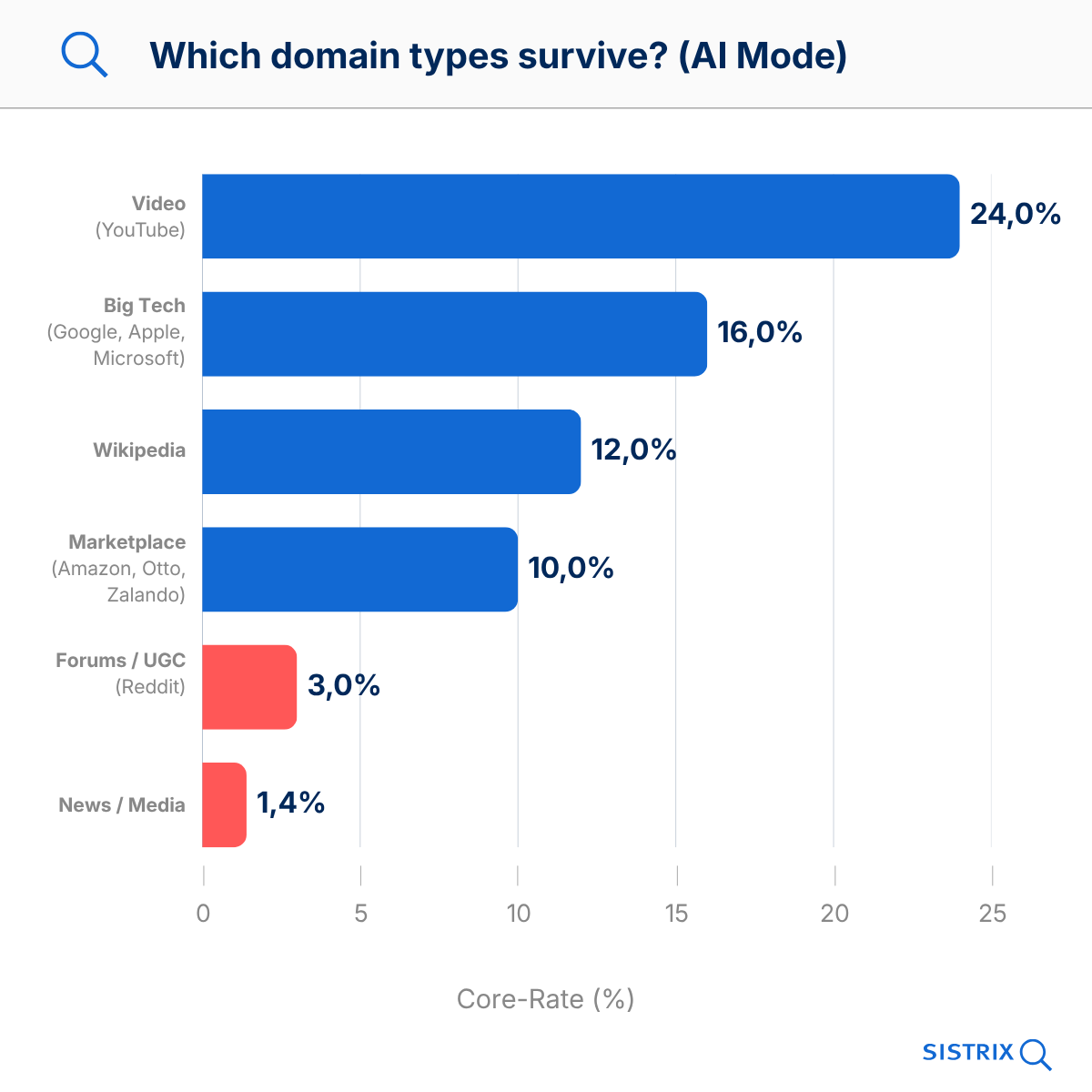
| domain type | median appearance | core rate |
|---|---|---|
| Video (YouTube) | 53% | 24% |
| Big Tech (Google, Apple, Microsoft) | 41% | 16% |
| Wikipedia | 24% | 12% |
| Marketplace (Amazon, Otto, Zalando) | 18% | 10% |
| News / Media | 12% | 1.4% |
| Forums / UGC (Reddit, Gutefrage) | 12% | 3% |
YouTube is the clear winner. The platform is cited as a source on more than half of all survey dates and, with a core rate of 24%, is the most frequently cited source in the core group. The fact that, of all things, Google’s own video platform performs so well is unlikely to come as a surprise to anyone.
At the other end of the spectrum are news sites with a core rate of 1.4%. News articles are a one-way ticket in AI responses. They are quoted and then gone a week later. For publishers looking to stake their future on GEO, this is a tough pill to swallow.
ChatGPT: no clear hierarchy
No comparable pattern emerges with ChatGPT. The differences between domain types are minimal, and even domains one might intuitively expect do not appear systematically more often in the stable core than others. This is consistent with the picture presented in the platform section: ChatGPT draws from a wide range of sources per response, without any particular category consistently dominating. For GEO, this means that no page type in ChatGPT presents itself as a reliable optimisation target.
What will survive? URL classification
We classified over 2,500 of the cited URLs using a Gemini-based NLP analysis according to language, content type, monetisation model, evergreen status and E-E-A-T signals. This reveals two distinctly different profiles for what ends up in the Core and Peripheral categories.
In Google AI Mode, 80% of core domains are in German (peripheral: 62%), and 85% of core URLs are evergreen (peripheral: 77%). Product and shop pages dominate the core, whilst guides and news articles rotate through. So if you want to feature in the AI Mode core in Germany, you should focus on German, timeless product pages, not magazine articles.
With ChatGPT Search, the picture is reversed. Core domains have an E-E-A-T score of 16/20, whilst peripheral domains score only 14/20 (the most significant E-E-A-T difference of all the platforms examined). The language shifts in the opposite direction: 68% of ChatGPT Core content is in English, even for German search queries. Documentation and institutional sources form the core, whilst editorial guides rotate.
The two platforms therefore reward almost diametrically opposed content profiles. Language, content type and monetisation model are structural characteristics of a website that cannot simply be adapted for GEO. For some sites, one profile is a better fit; for others, both; and for others still, neither. Which position a site occupies is therefore a question of its starting point, not just of optimisation.
Every platform cites different sources
Even Google’s own products hardly ever match. For the same prompt, AI Overviews and AI Mode cite different domains 83% of the time. The Jaccard index, which measures the overlap, stands at 0.17. In other words: of all the domains that appear in one of the two responses, only 17% appear in both. Between AI Mode and ChatGPT, the overlap is even lower at 0.125.
Examples: “wie kann ich kostenlos online tv schauen?” (translation: “how can I watch TV online for free“)
- AI Mode cites: check24.de, dslweb.de, hoerzu.de (comparison sites and TV guides)
- ChatGPT cites: arte.tv, zdf.de, 3sat.de (the broadcasters themselves)
- Both: only joyn.de
One reason for the low overlap lies in the platforms’ structural preferences. AI Mode draws on German-language sources 80% of the time, whilst ChatGPT draws on English-language sources 68% of the time, even for German search queries. This language bias alone ensures that the source pools of the two platforms can hardly overlap for the German market.
For GEO, this means that a strategy that works for AI Mode often doesn’t work at all for ChatGPT, and vice versa. Platform-specific citation strategies are therefore not optional, but a fundamental requirement.
Domain-Level vs. URL-Level: our numbers are conservative
All the drift figures mentioned so far are based on domain comparisons. At the URL level – that is, for the specific subpage rather than just the website – the drift is even more pronounced: 85% per week compared to 74% at the domain level. Even if a domain remains stable within the citation set, Google frequently changes the specific subpage.
Example: imdb.com remains the source for “action adventure movie“. In week 1, the link is to /list/ls594655800/, and in week 2, to /chart/moviemeter/. A completely different page on the same domain.
For GEO, this means that the ranking of a single URL in AI responses is not a meaningful metric. Domain presence is measurable and controllable. However, it is not possible to control which specific URL appears on that domain in a given week.
Citation Drift is global
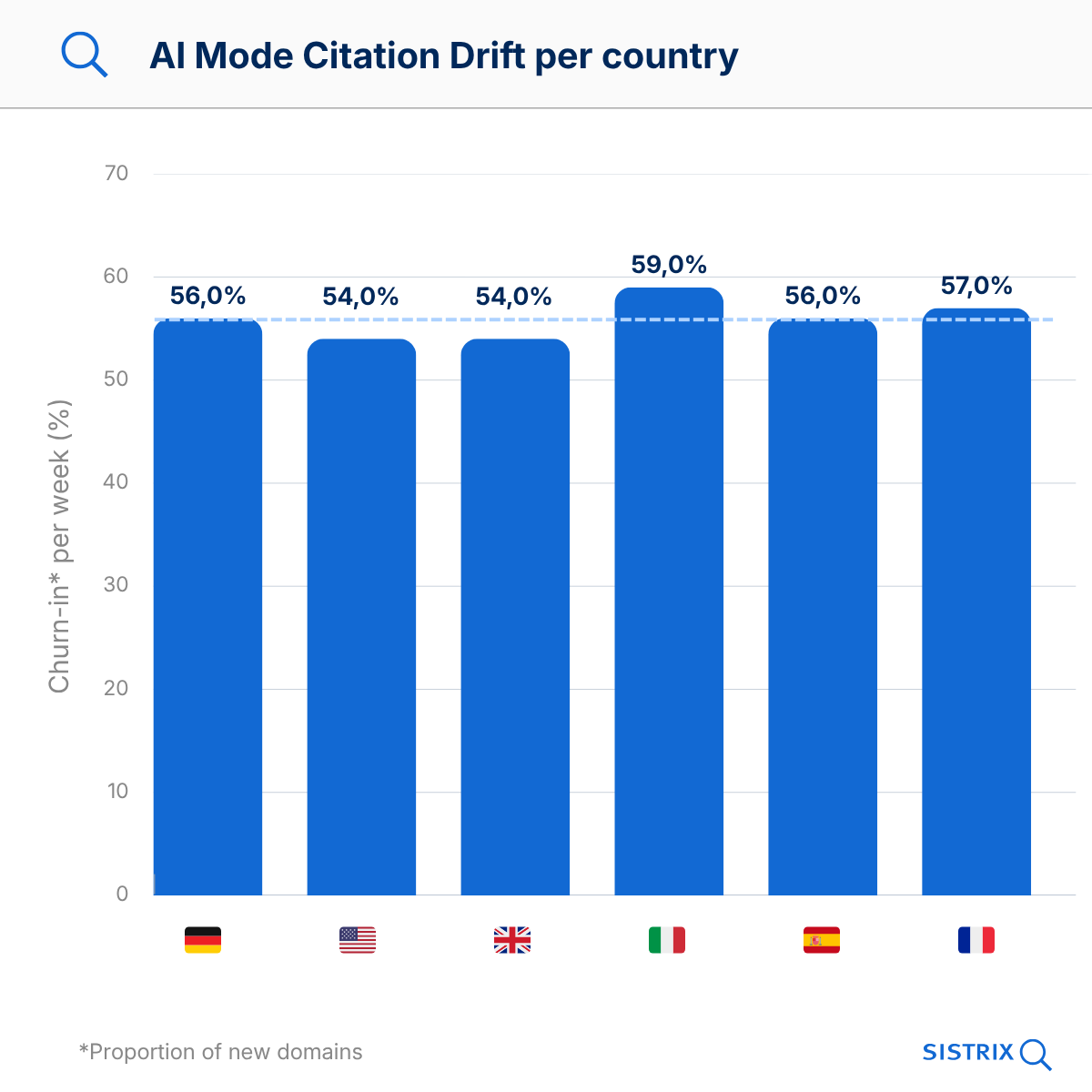
The drift rates in Google AI Mode are remarkably consistent across all six countries studied: between 54% and 59% weekly churn, regardless of country or language. Citation drift is not a phenomenon specific to the US or Germany, but rather a structural feature of the platform.
With ChatGPT, however, there are differences between countries. At 74%, Germany is significantly more volatile than the UK (60%) and France (42%). This is likely due to differences in crawl coverage for different languages.
No clear trend is apparent over the entire 17-week period. No stabilisation, no levelling off. Anyone waiting for the moment when AI platforms agree on a fixed set of sources may be waiting a long time.
What does this mean for GEO?
The findings of this study can be translated into three specific recommendations for action.
- Content planning: Evergreen content before news, product pages before how-to guides.
The core rates by content type provide a clear prioritisation. Evergreen content, product and shop pages consistently have a higher chance of being cited in the long term. With a core rate of 1.4%, news articles are practically unsuitable for citation targets, though this does not negate their value as a traffic-generating format – just not as a GEO investment. Video, with a core rate of 24%, is the strongest content type of all. For companies that do not yet operate a structured YouTube channel, it is worth taking a closer look here. - Set your platform focus based on your starting point.
AI Overviews, AI Mode and ChatGPT cite domains that differ by more than 80% for the same question. At the same time, they favour different content profiles (German shop pages in AI Mode, English documentation in ChatGPT). Most companies are structurally better positioned for one of the platforms than for the others. Rather than treating all three equally, it usually makes more sense to select the most suitable platform as the optimisation target and treat the others as monitoring targets. - Calibrating GEO expectations.
Traditional SEO promises such as “Rank 1 for keyword X” do not work with AI-generated responses. Ultimately, GEO is about optimising the random factors that LLMs work with, and with a 56% weekly drift, a single citation placement is not a reproducible result but merely a snapshot. For projects, this means basing success metrics on presence over time, not on individual results, and setting clear expectations with stakeholders: GEO is a continuous process, not a one-off optimisation with permanent results.
Data basis
This study is based on the SISTRIX AI Research Index and comprises 82,619 qualified prompts with 1,548,213 snapshots. The study covered six countries (Germany, USA, UK, Italy, Spain, France), three platforms (Google AI Mode, Google AI Overviews, ChatGPT Search) and 17 weeks from 17 December 2025 to 8 April 2026, with weekly reference dates. In addition, 2,556 source URLs were classified by language, content type and E-E-A-T.
All drift metrics are based on domain-level comparisons between consecutive weekly snapshots. The main metrics are Churn-in (proportion of new domains per week) and Retention (proportion of surviving domains).
Limitations: The ChatGPT data only includes prompts with consistent source attribution. The drift rates cited are conservative; at the URL level, they are 15% higher.