
If you want to prevent Google from crawling all or parts of your domain, you can do so within the robots.txt file.
Discover how SISTRIX can be used to improve your search marketing. 14 day free, no-commitment trial with all data and tools: Test SISTRIX for free
Lily Ray talks about blocking crawlers from a website using robots.txt
Note: If you are looking to block specific URLs, you can use the robots meta-tag. Also be aware that there are some cases where URLs will still be indexed, even if they are blocked using the robots.txt file.
Blocking the Google-Bot using the robots.txt
The robots.txt is a simple text file with the name “robots”. It has to be placed in the root-directory of a website in order for search engines to follow the directives.
If a website has a robots.txt, it can be accessed through the following path:
http://www.my-domain.com/robots.txtThe contents of the robots.txt
By using the following instructions, we exclusively forbid the Google-Bot access to our entire website:
You have to add the following to your robots.txt to tell Google-Bot to stay away from the entire domain:
User-Agent: Googlebot
Disallow: /If you only want to restrict access to some directories or files instead of the entire website, the robots.txt has to contain the following:
The following only tells Google-Bot that it is forbidden from accessing the directory “a-directory” as well as the file “one-file.pdf”:
User-Agent: Googlebot
Disallow: /a-directory/
Disallow: /one-file.pdfSome URLs may still be indexed
The code examples shown here are only meant for Google-Bot. Crawlers from other search engines, such as Bing, will not be blocked.
Block crawlers using WordPress
WordPress has a built-in feature that will set a robots meta-tag to noindex in the header of every page.
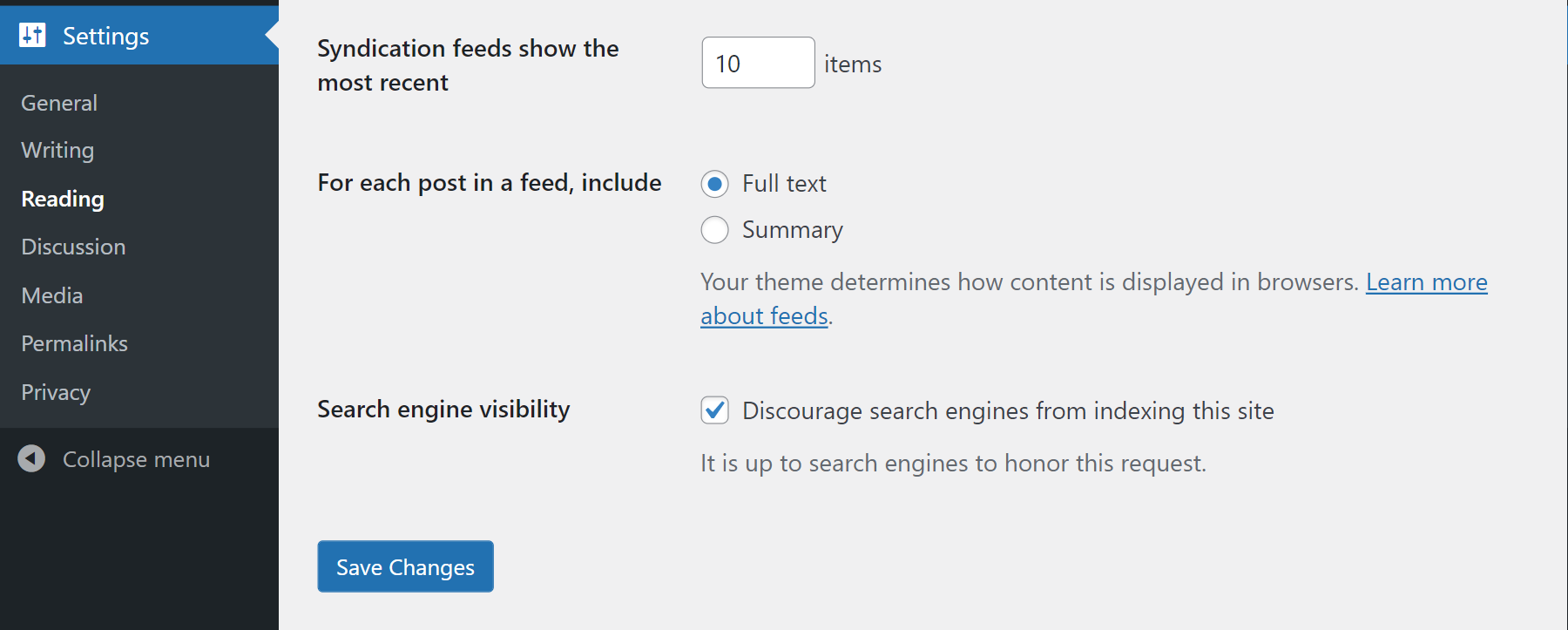
Assuming you have the Administrator rights in the WordPress site, go to the Settings -> Reading page and select “Discourage search engines from indexing this site” 1 as shown above.
More information on Googlebot and crawler control
What is the difference between robots.txt and the robots meta-tag?
https://support.google.com/webmasters/answer/6062608?hl=en
Test SISTRIX for Free
- Free 14-day test account
- Non-binding. No termination necessary
- Personalised on-boarding with experts