
The user-agent is sent by the browser to a web server with each network request, and it’s supposed to show information regarding the user’s system. Thus, we could say that this tag uses the browser as its “name”. More information and tips in this article.
Discover how SISTRIX can be used to improve your search marketing. 14 day free, no-commitment trial with all data and tools: Test SISTRIX for free
What is a User-Agent?
The user-agent is an HTTP header field which can be used to transfer more or less detailed information regarding the device making a network request.
This is done through an HTTP header and this information can be used, for example, to deliver certain elements only to those browsers, which are capable of managing them.
What is the User-Agent composed of?
The user-agent syntax is fairly simple:
User-Agent: <Product> / <Product version> <Comments>However, if we take a look at a standard user-agent of a Google smartphone, for example, things look rather different:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96
Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)We can break down this user-agent’s parts as follows:
- Mozilla is the product.
- 5.0 is the version of the product.
- (Linux; is the device’s operating system.
- Android 6.0.1; is the OS version.
- Nexus 5X Build/MMB29P) is the OS compilation.
- AppleWebKit/537.36 is the browser rendering engine.
- (KHTML, like Gecko) is the rendering engine based on KHTML, behaving like Gecko.
- Chrome/41.0.2272.96 is the browser and its version number.
- Mobile Safari/537.36 is the browser behaving like Safari with the version number 537.36.
- (compatible; here is where the comment really starts, explaining that the device is compatible with the Mozilla browser.
- Googlebot/2.1; name and number of the crawler version.
- +http://www.google.com/bot.html) where can I get more information about this agent?
If you’re wondering why Googlebot –which is a Google Chrome browser– is pretending to be Mozilla, you’re not alone. There is a fun blog post on the history of the browser user-agent string, which tells us all the important bits. The conclusion is that almost all browsers pretend to be Mozilla for “reasons”. The <Product> value is, thus, irrelevant, and comments were much longer.
How does User-Agent use the server information?
The server can use the information regarding the system making the request to provide users with the appropriate website version. For example: if a user-agent tells the server that a request is coming from an Android smartphone using Chrome, the server can return the mobile version of the requested website, provided there is a mobile version available.
With the user-agent’s help, the server can also determine if the browser version in use is still supported. For example, if someone is using an “old” browser like Internet Explorer 6, the server can respond and send an update request instead of the solicited website.
Finally, the user-agent information can be collected by web servers for statistical purposes, to name one possible example.
User-Agents and crawlers
Search engine crawlers also have a user-agent. Given that the user-agent identifies bots as what they are, this is, bots, web servers give them special “privileges”. For example, the web server can walk Googlebot through a sign up page. It’s important that we avoid taking the risk of showing users content that is different from what we show to Googlebot, because it could be considered cloaking.
Using robots.txt (file which also contains a user-agent), the web server can request search engines not to crawl certain areas of a website.
How can I use the User-Agent for SEO?
If you know what information Google’s various crawlers use, you can configure your browser to send the same identifier, either through a browser extension or the Developer console.
For example, we can often verify whether a website is serving content to its regular users that differs from what Googlebot sees.
To do this with Chrome, we simply need to access its console, which can also be done using the following shortcuts:
- Mac: Command+Alt+C
- Windows: Control+Shift+C
Or right-click and “Inspect”.
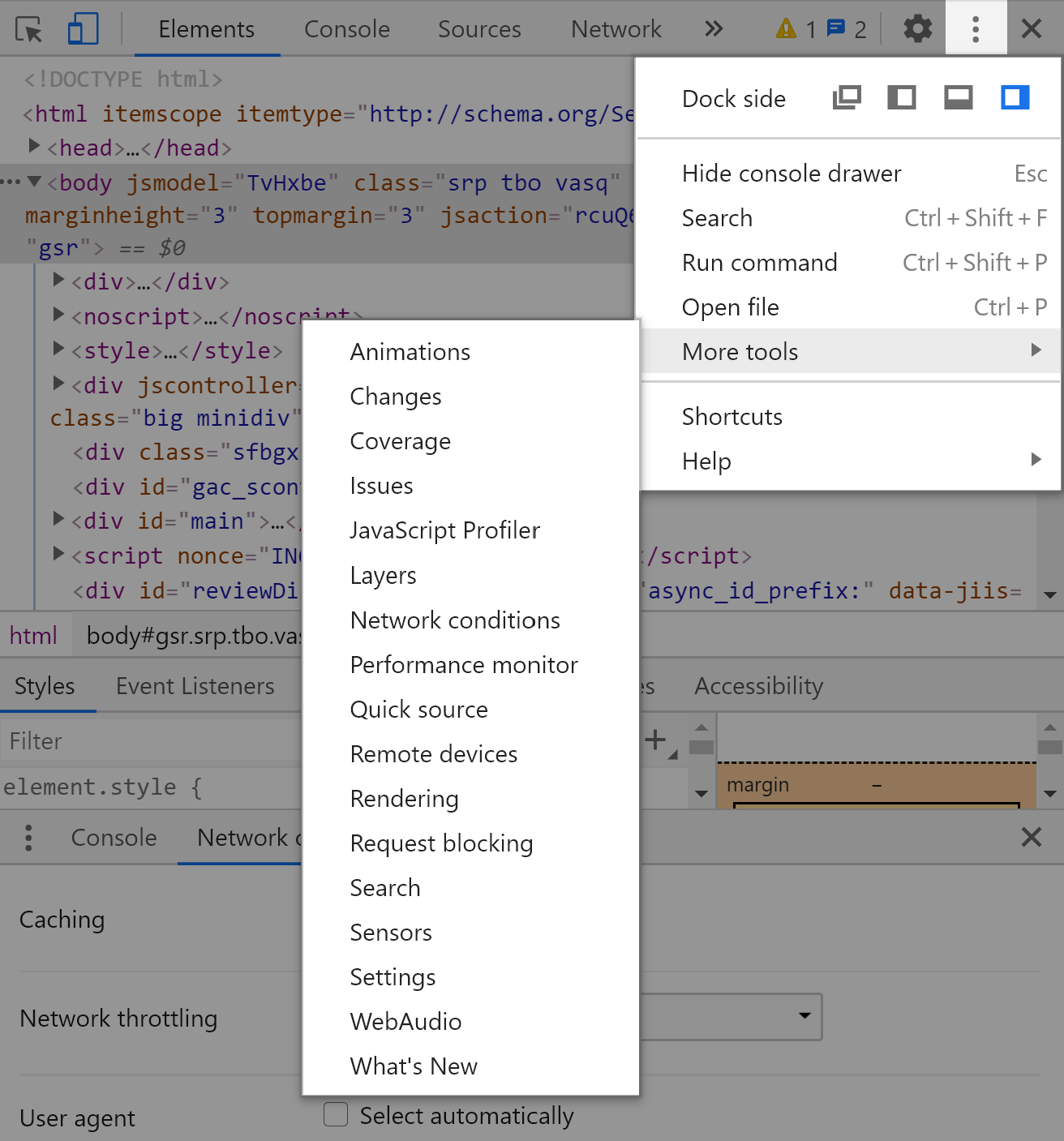
As shown in the picture above, you only need to:
- Click on Customize and Control DevTools, represented by the three-point icon.
- Click on “More tools”.
- Click on “Network conditions”.
Then, we only need to choose which user-agent we want to use to browse, by entering it into the red field, pictured below:
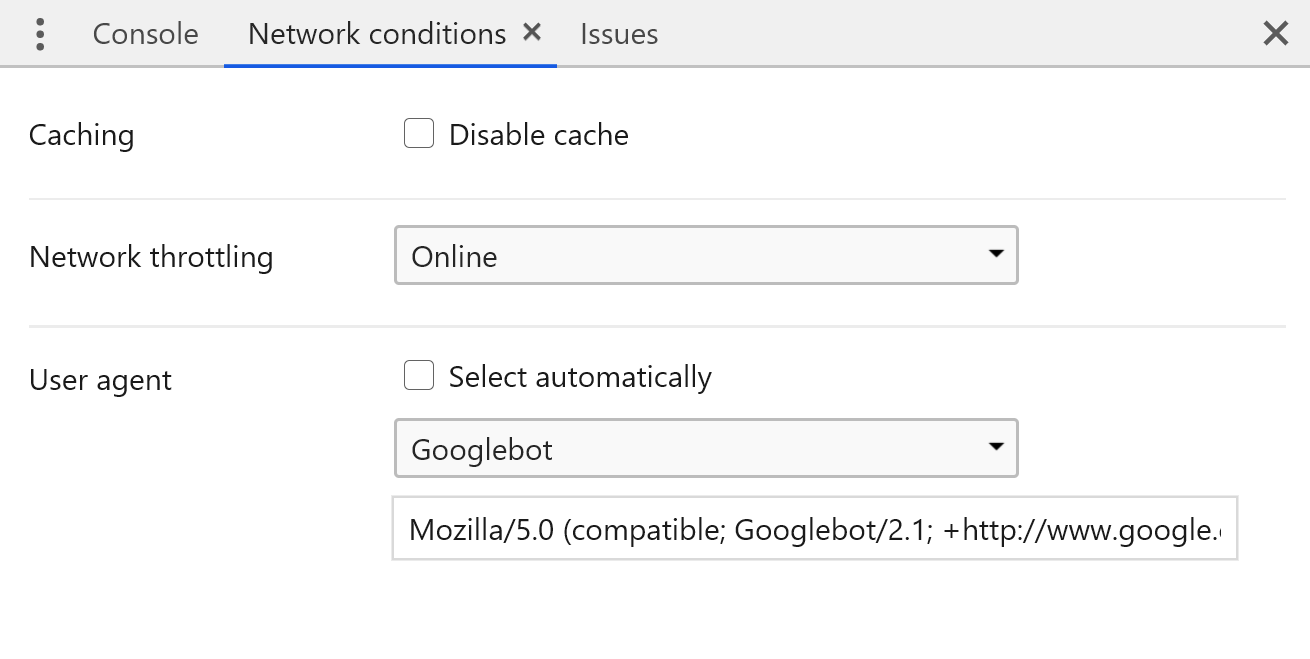
This will only work as long as the server doesn’t carry out an internal check, to find out whether a user-agent claiming to be Googlebot really comes from a Google IP address.
Useful User-Agents for SEO
In the tables below you can see the main and most-used user-agents in SEO environments. Each indicates the crawler it belongs to, and what will remain registered in the request headers, information that can be checked analysing the server’s logs.
Google-related user-agents
| Crawler | User-Agent Token | Full User-Agent |
|---|---|---|
| Googlebot Images | - Googlebot-Image - Googlebot | Googlebot-Image/1.0 |
| Googlebot News | - Googlebot-News - Googlebot | Googlebot-News |
| Googlebot Video | - Googlebot-Video - Googlebot | Googlebot-Video/1.0 |
| Googlebot Desktop | Googlebot | - Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Safari/537.36 or (infrequently used): - Googlebot/2.1 (+http://www.google.com/bot.html) |
| Googlebot Smartphone | Googlebot | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Googlebot Smartphone *** | Googlebot | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Mobile Apps Android | AdsBot-Google-Mobile-Apps | AdsBot-Google-Mobile-Apps |
Regarding the Smartphone User-Agent *: starting from December 2019 the Chrome browser version will start to get updated, so the X.Y.Z. letters will be replaced by whichever versions Google Chrome is going to use (more official info here).
Other user-agents to note
There are other user-agents which can be relevant to SEO projects, as well as in terms of saving web project bandwidth, reason why they require being monitored and optimised.
| Crawler | User-Agent Token | Full User-Agent |
|---|---|---|
| Pinterestbot | Pinterest/0.2 (+https://www.pinterest.com/bot.html) Mozilla/5.0 (compatible; Pinterestbot/1.0; +https://www.pinterest.com/bot.html) Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Pinterestbot/1.0; +https://www.pinterest.com/bot.html) | |
| LinkedInBot | LinkedInBot/1.0 (compatible; Mozilla/5.0; Jakarta Commons-HttpClient/3.1 +http://www.linkedin.com) | |
| Bing | bingbot | - Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Mozilla/5.0 (iPhone; CPU iPhone OS 7_0 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A465 Safari/9537.53 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Mozilla/5.0 (Windows Phone 8.1; ARM; Trident/7.0; Touch; rv:11.0; IEMobile/11.0; NOKIA; Lumia 530) like Gecko (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) |
| Yandex* | YandexBot | Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) |
| Wayback Machine | archive.org_bot | Mozilla/5.0 (compatible; archive.org_bot +http://www.archive.org/details/archive.org_bot) |
Regarding the Yandex User-Agent *: there are many other strings identifying as YandexBot, which can also be valid (more official info here).
Test SISTRIX for Free
- Free 14-day test account
- Non-binding. No termination necessary
- Personalised on-boarding with experts