
A few weeks ago, I explained how using a directory structure which uses dates within the URLs can kill your content in Google. The examples TheGuardian.com, HuffingtonPost.co.uk and TechCrunch.com all show us that there is still much room for improvement and an opportunity for more traffic. Using dates in the URLs are a symptom of a less than optimal information architecture.
Publishers or news websites have to prepare the pieces of information on their site in such a way that both Google and regular users can find them. Google users do not think in dates (they are not using news libraries!), they use search queries on search engines and that is the way how things work today. Something that e-commerce websites take for granted should also be something that news websites find self evident.
Could you imagine an e-commerce website using dates as part of their information architecture? No, of course not. Shops, for example, are made up of detail pages and categories. With the categories being an integral part of the site, because often users may not know exactly what they are looking for.
Another question is, why journals or news websites use dates in their website structure, when the number of topics that a journal will use are both quantifiable and almost always the same? A lot of scattered indexed URLs around the same news item is not the best answer for users and search engines. What really shines here are categories.
Categories are just the best holistic answer you can deliver
All URLs that deal with the same topics should be viewed as a whole, not as a collection of parts. Using categories, you are telling Google which part of your domain should rank for a particular topic. If you search on Google.co.uk for “Europe“, you will probably find this:
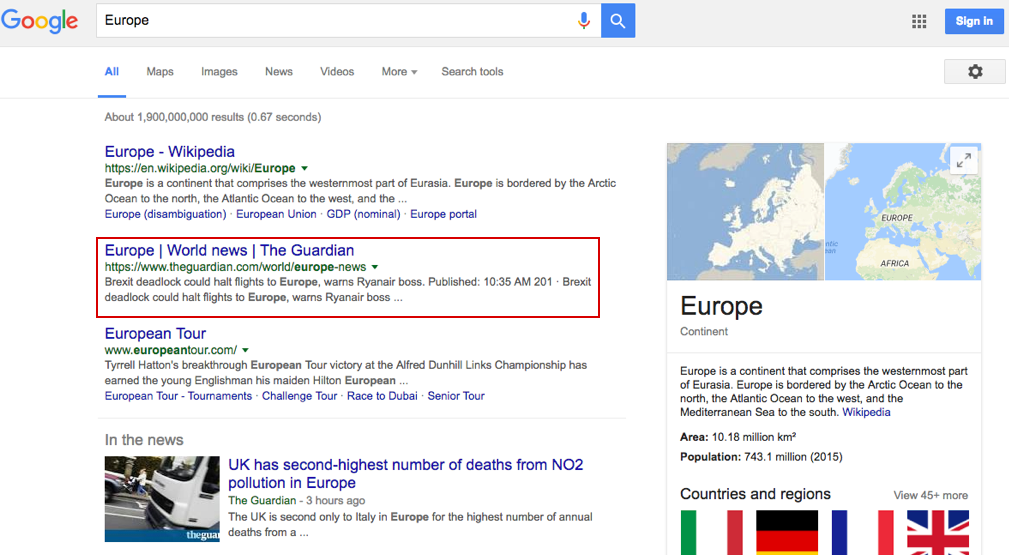
TheGuardian.com ranks in second position, right after the Wikipedia, because “Europe“ is not a collection of parts, it is a whole of all news around this topic. In other words, just a category.
The NYtimes.com and TheGuardian.com are already using categories but they are far from exhausting all their potential (which opens up room for improvement). Instead, I would like to show 3 examples which work very well, two from Germany and one from Spain:
Sueddeutsche.de
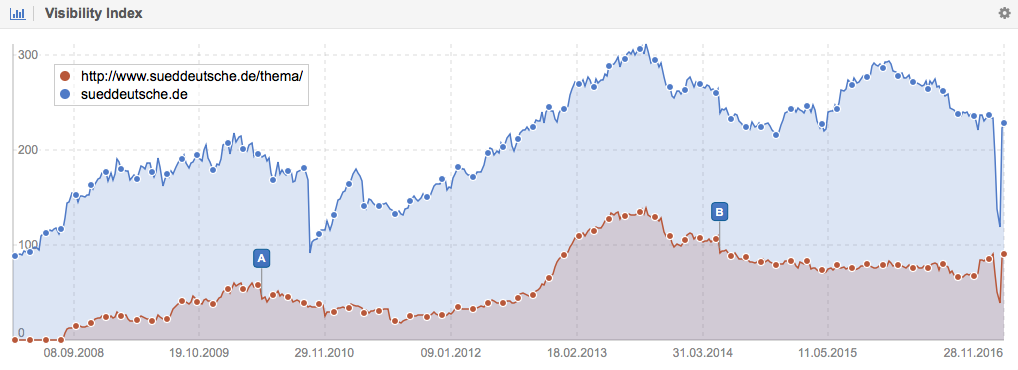
For the German news Website, Sueddeutsch.de, their category directory generates 40 percent of the entire site’s Visibility on Google.de.
Spiegel.de
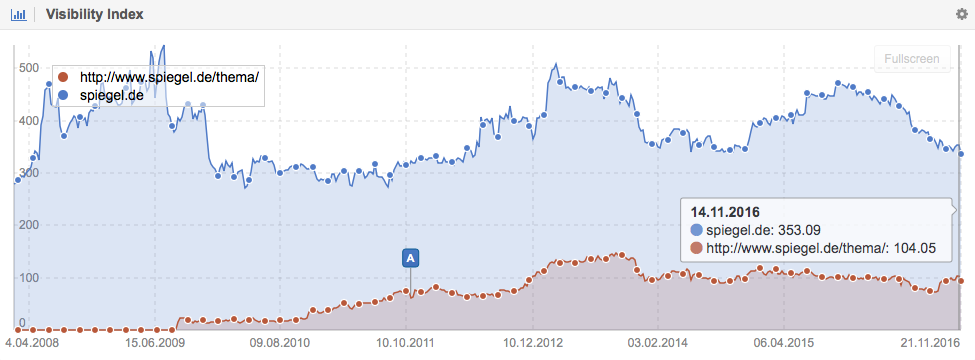
For the German magazine, Spiegel.de, their category directory represents 30 percent of their entire Visibility on Google.de. Spiegel.de even goes a step further with their category pages. They add a short description about the topic (for example “Donal Trump“):
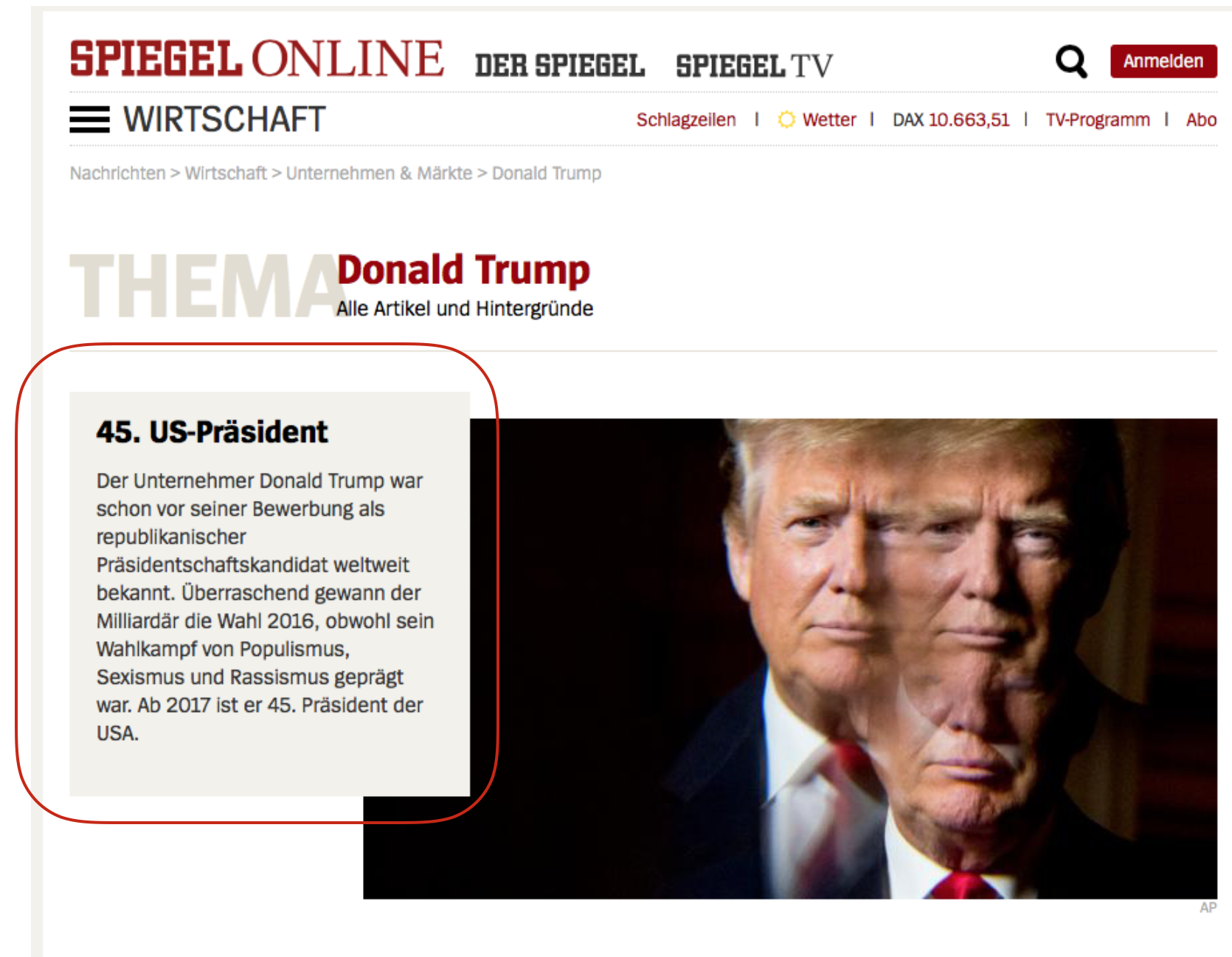
This short description is a good idea. Now imagine what News organizations could create using the vast amounts of information they have available to serve information pages that could rival and surpass even Wikipedia.
Competing with Wikipedia
85% of all keywords for TheGuardian that we know of are in direct competition with Wikipedia.org. If we forget about their position and brand searches for a moment, this number shows us how many opportunities there are for TheGuardian.com:
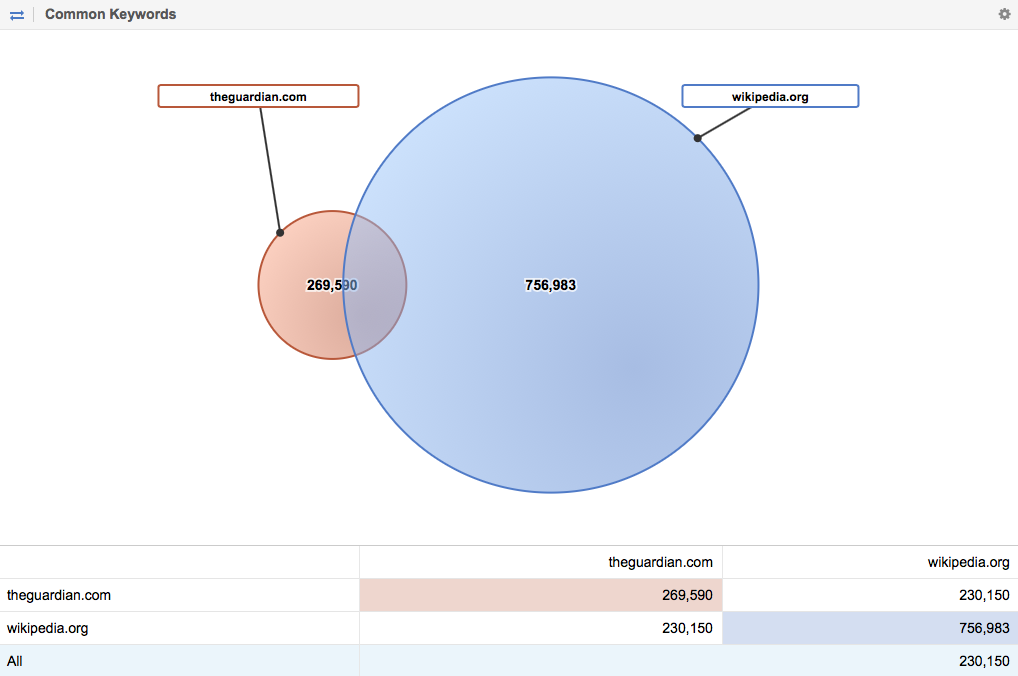
If the news websites would offer the best answer, Wikipedia might turn into just an alternative source for many Google users. News websites like the Nytimes.com, TheGuardian and Spiegel.de are able to offer a better answer than Wikipedia, just because they already own more reliable and verified Information than Wikipedia and they could present this information in other amazing formats. Something that Wikipedia is not set up to do.
I was not able to find out exactly how much traffic Wikipedia actually has – it seems that they do not release any information about their traffic. Obviously, traffic is not a critical success factor for Wikipedia. But Wikipedia’s market share on Google.co.uk is 13,6 times larger than TheGuardian.com. In other words, TheGuardian.com has a lot of opportunities on Google.co.uk alone.
I hope you like it.
Additional information about this topic
Rand Fishkin – Information Architecture for SEO – Whiteboard Friday
Wil Reynolds, “Go Where the Users Are. Building a Holistic SERP Strategy”.
