
A large language model, or LLM for short, is a computing system that, through training on extensive text collections, is able to analyse natural language input and respond to it with independently generated coherent, context-related text. Here’s more detail on how they work, and the risks involved.
Large language models are computer-based systems that process digital content on a large scale. They analyse linguistic patterns in texts and use statistical probabilities and databases to generate content that often appears convincing to human readers, even if the model itself does not ‘understand’ the content.
A characteristic feature is that they are trained with enormous amounts of data, texts from books, websites, articles, comments, etc., and in the process learn how language works: grammar, style, context, meaning and connections. However, this does not mean that language models know everything; they have only been fed with very large amounts of human knowledge and can only draw on this information.
The development of language models began with simple, rule-based systems that could only recognise limited contexts. Later, models were added that used artificial intelligence to learn how to process language better. These early neural networks brought initial progress, but were not particularly powerful when it came to longer texts or complex contexts.
The real breakthrough came with the so-called Transformer architecture in 2017. This made it possible to process very large amounts of data efficiently and capture longer text contexts. This laid the foundation for today’s large language models, which are significantly more powerful, flexible and comprehensive than their predecessors.
The Transformer architecture plays a central role: it allows the model to not only look locally at one part of the content, but to relate all parts of a text to each other (self-attention). This allows language contexts to be captured much more comprehensively, ambiguities to be resolved more effectively, and style and context to be applied more correctly. The modernisation towards LLMs therefore involves not only more data and computing power, but also fundamental improvements in model architecture.

Training and data
Training an LLM typically begins with a pre-training phase, comparable to primary school. This involves using large, widely varied text corpora, from books, scientific publications, news, forums, etc. The aim of this phase is not to solve a specific task, but to learn language patterns. E.g. How do people construct sentences? How do they connect thoughts? How is meaning generated across words? This phase is self-supervised: the model attempts to predict which word comes next or to reconstruct parts of a sentence.
Pre-training is often followed by a fine-tuning phase, in which the model is adapted to specific tasks or domains. For example, an LLM can be trained to understand legal texts particularly well, support medical conversations or interact with customers as a chatbot. Techniques such as instruction tuning, in which the model learns to respond to specific instructions or style guidelines, and reinforcement learning from human feedback (RLHF), in which human feedback is used to improve the quality, comprehensibility and safety of the outputs, are also used.
Architecture
Most modern language models are based on what is known as a transformer architecture. This enables the model to view all the words in a text simultaneously and recognise their relationships to one another. A key component of this is the attention mechanism, which helps the model decide which words in a sentence are particularly important for understanding the context. This allows the model to grasp not only individual terms, but also the meaning and structure of a text.
The performance of a model depends, among other things, on the number of its parameters. These are the adjustable values with which the model learns language. The more parameters a model has, the more complex the relationships it can map but the greater the technical effort required for training and deployment.
Another important feature is the so-called context length which determines how much text the model can take into account at once. With short contexts, the model quickly loses track of longer passages. Modern models, on the other hand, can easily process entire articles or long conversations without losing the thread.
In addition, there are LLMs that not only work with text, but can also process images or other types of data; so-called multimodal models. They can, for example, describe an image, interpret a graphic or answer a question that refers to a combination of text and image. This significantly expands the range of possible applications, for example in product descriptions, customer service or the analysis of visual content.
Prompts as an interface
The use of LLMs is based on so-called prompts. A prompt is the input that a user directs to the model, such as a question, an instruction or a text excerpt. The model processes this prompt and then generates a suitable response. Even small differences in wording can greatly change the output. Prompts can also be used to input large amounts of data, such as texts that need to be revised or translated.
Measuring visibility in LLMs with SISTRIX
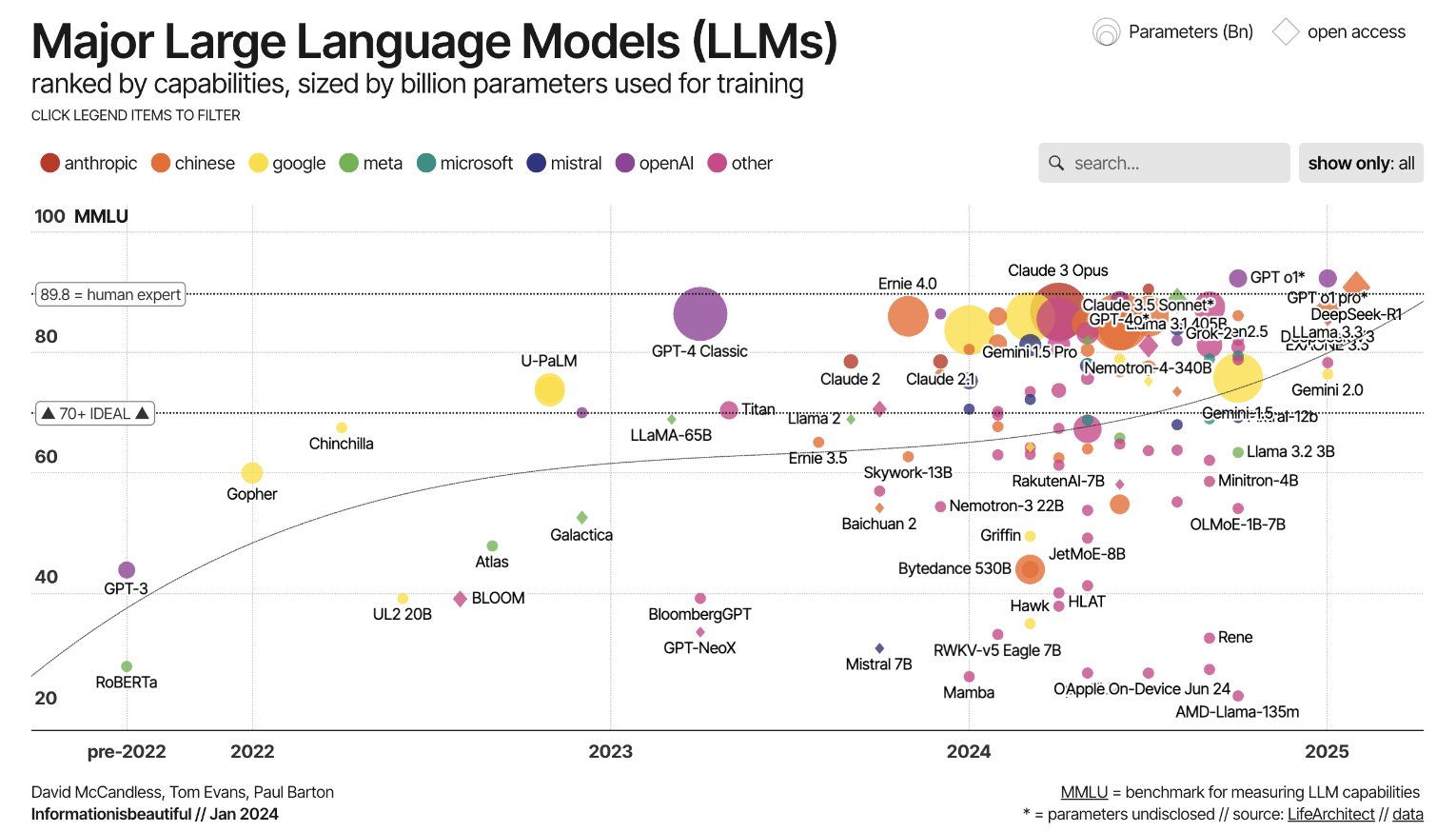
LLMs such as ChatGPT, Gemini and DeepSeek are changing how people find information and how brands become visible. More and more search queries that used to lead to website clicks are now answered directly by chatbots, AI search engines or even Google AI Overviews. This means fewer clicks and changes to key KPIs. What used to be page views and clicks are now citations and links in the AI’s responses in the new systems.
To measure these metrics, SISTRIX offers the AI / Chatbot Beta. This makes it easy to check in which chatbots a brand is mentioned, which prompts your own entity appears in, and where only competitors are visible instead.
Nevertheless, most search queries still run through Google, and that is not going to change anytime soon. Many strategies that apply to classic SEO are also the right approach in the context of the new LLMs.
Typical areas of application for LLMs
LLMs are used in many fields, some in everyday scenarios, some in specialised ones.
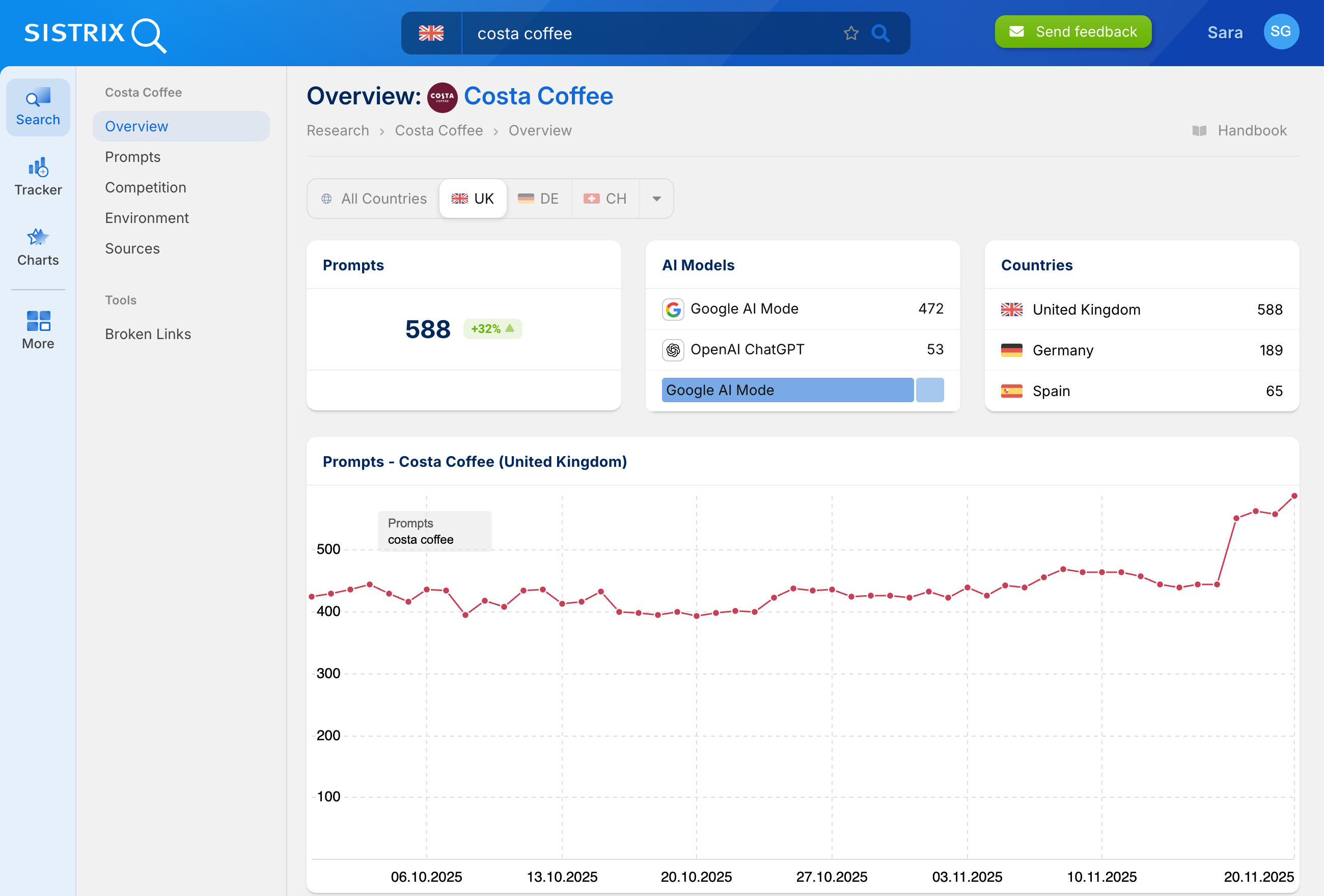
The automatic generation of text is one of the most obvious areas of application. Whether for blog posts, marketing texts, emails or creative content such as stories and poems, LLMs can create content or at least provide drafts that facilitate and accelerate human editing.
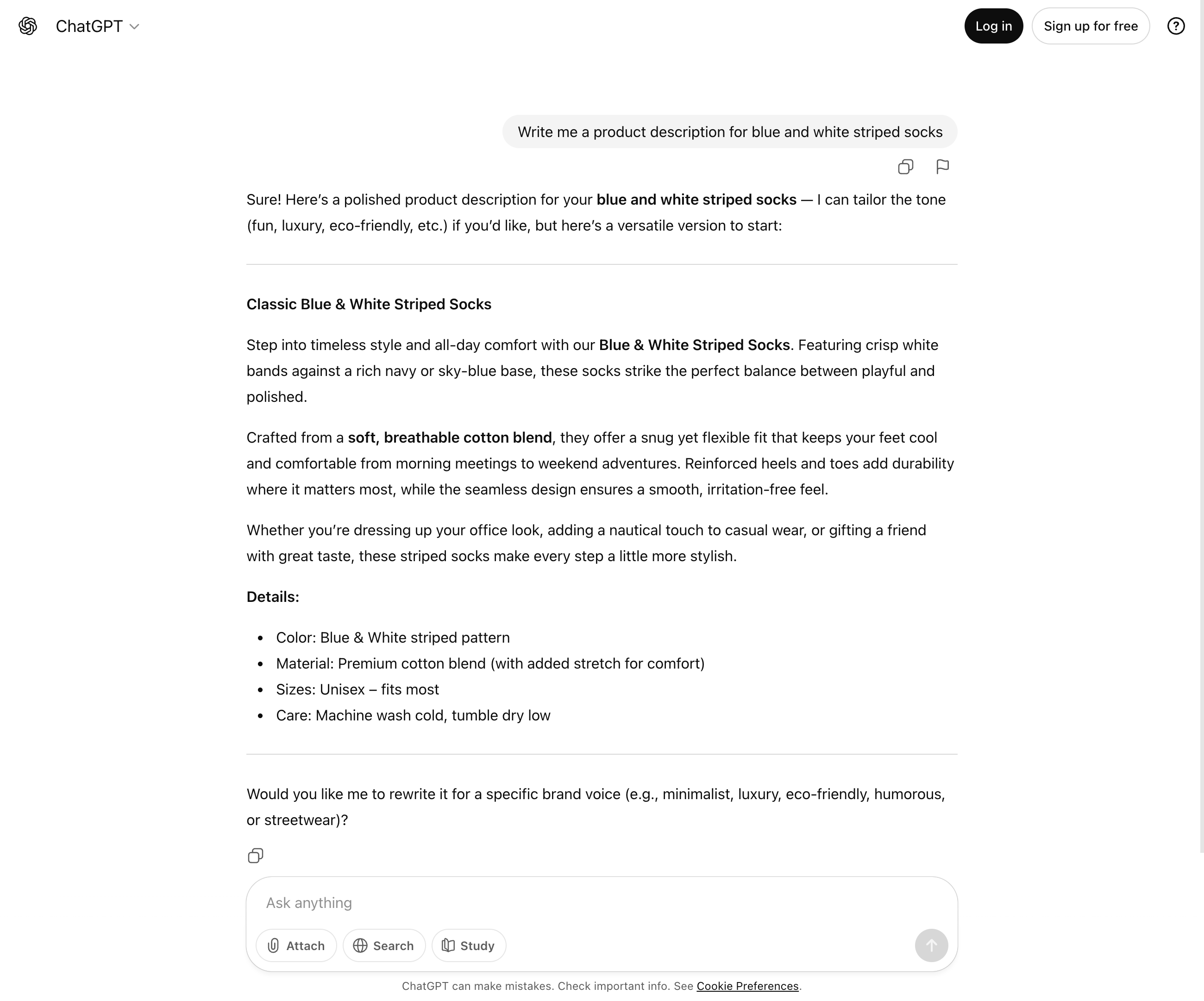
LLMs are used as chatbots or virtual assistants in communication with users. They answer questions, give recommendations, conduct dialogues and can provide support. In this way, they improve the user experience and enable scaling, for example in customer service.
LLMs also play an important role in processing large amounts of information. They can summarise texts, extract key statements from long documents, answer complex questions or structure information. Such skills are valuable in science, research, corporate documentation or legal opinions, for example.
In addition, LLMs are used for data analysis and classification: emotion recognition (sentiment analysis), topic clustering, classification of texts by topic or direction, and identification of opinions, trends or risks in social media or user feedback.
Some LLMs are specialised for specific domains such as medicine, law or finance. These domains often have stricter requirements for accuracy, traceability and reliability.
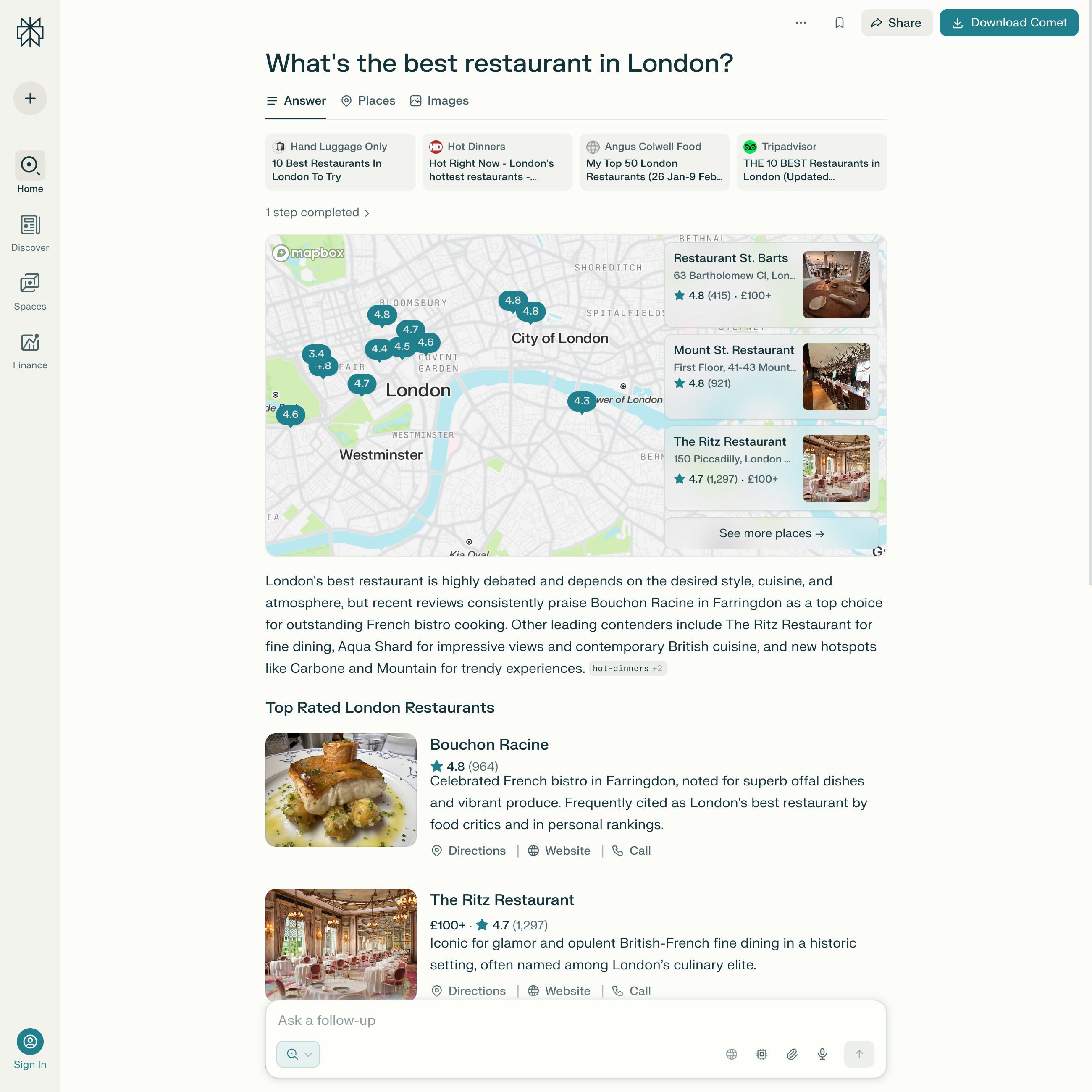
Another growing area of application is the integration of LLMs into search engines. Instead of just providing lists of links, they generate direct, language-based answers to search queries. Search engines are becoming answer engines. This is giving rise to a new form of information retrieval that no longer focuses on navigating to content, but rather on immediate comprehensibility and ease of use. The models act as an interface between users and knowledge, fundamentally changing how search results are perceived and processed.
Challenges and risks
As powerful as LLMs are, they also come with some risks.
One fundamental problem is the lack of grounding: language models calculate probabilities but have no understanding of the real world. Even though web-connected systems such as ChatGPT or Gemini incorporate current information from websites, they do not check facts but continue to generate answers on a purely linguistic basis.
This results in bias and hallucinations. Distortions in the training data lead to discriminatory or stereotypical outputs, while hallucinations can generate seemingly plausible but false information, with potentially serious consequences in sensitive areas such as medicine or law. LLMs cannot correctly classify facts and respond to every prompt, even if it is already incorrect or biased.
Another risk is prompt injections. Here, attackers attempt to use prepared inputs or manipulated websites to trick models into circumventing security requirements or revealing confidential data. These attacks are particularly difficult to defend against because they affect the language level itself rather than the code.
The ecological footprint is also considerable: training and operating large models consume enormous amounts of energy and computing resources.
Added to this are legal uncertainties, such as questions of copyright, data protection and ownership of generated texts. Finally, there is also the risk of misuse: LLMs can be used to spread disinformation, spam or manipulative content.
The opportunities offered by this technology are great in some areas, but these risks can only be managed with clear rules, transparency and research.
Examples of well-known large language models
The best-known LLMs include the following:
- GPT models (OpenAI) are among the most widely used. They offer strong performance in generative language production and have broad support from tools, integrations, and community resources.
- LLaMA models (Meta) are often open (at least in part), are used in research and specialised application scenarios, and allow for customisation to specific requirements.
- Gemini (Google DeepMind) is a family of models that has been around since December 2023 and is considered the successor to LaMDA and PaLM. Gemini includes variants such as Gemini Ultra, Gemini Pro, Gemini Flash and Gemini Nano. These are multimodal models, i.e. models that can process other modalities such as images in addition to text. A particularly notable feature of Gemini is its very large context window.
- Claude (Anthropic) is a language model that has been in development since 2023. It is based on the ‘Constitutional AI’ approach, in which the behaviour of the model is controlled by a set of rules. Claude has been released in several generations (Claude 1, 2 and 3) and is undergoing continuous development.
LLMs and Search Engines
With the increasing capabilities of LLMs, a central question has emerged that is currently being widely discussed: Are Large Language Models replacing traditional search engines?
Conventional search engines such as Google or Bing are fundamentally based on crawling, indexing, and ranking web pages. Users enter search terms, receive a list of results, and click through to relevant content. This interaction is information-oriented but fragmented: the user remains responsible for filtering information, verifying sources, and combining content on their own.
LLMs, by contrast, offer a direct, language-based interface, which makes usability simpler. Instead of lists of links, they provide (seemingly) complete answers—often with summaries, arguments, or context. The user experience changes: instead of “Find information about X”, the focus shifts to “Explain X to me”. This marks a move from searching to understanding. In many “clear-cut” scenarios—questions for which there is only one correct answer, such as simple factual queries, definitions, or instructions—LLMs already replace traditional web searches almost entirely.
This shift also changes the behaviour of providers. Since March 2025, Google has been integrating LLM components directly into its search results through its AI Overviews, displaying AI-generated responses above traditional search listings and experimenting with dialogue-based interfaces. Bing took a similar step early on with the integration of GPT technology into “Bing Chat”, putting pressure on Google to respond. Startups such as Perplexity.ai are also focusing entirely on an LLM-driven search experience that includes sources, but primarily communicates through natural language.
At the same time, traditional search engines remain relevant—particularly in areas where source verification, up-to-date information, and transparency are crucial. While LLMs can generate fluent answers, they do not always provide verifiable evidence or current content. Especially for breaking news, complex research, or legally binding information, searching through linked sources remains indispensable.
In the long term, a process of hybridisation is emerging: search engines and LLMs are gradually converging. Users receive AI-generated answers with source references but can also research further, add context, or verify information. This development represents not a displacement but a realignment of the search process—from the click-based model to a dialogic structure, from a list of URLs to an answer on equal footing.
For SEO, this means that content must become not only machine-readable but also model-intelligible. Structure, clarity, authority, and context gain even greater importance. At the same time, SEO professionals must prepare for significantly reduced reach, since in many AI-generated responses to questions with only one correct answer, no further clicks are required. However, this does not mean that SEO will cease to generate clicks altogether.
Test SISTRIX for Free
- Free 14-day test account
- Non-binding. No termination necessary
- Personalised on-boarding with experts