
The inverse document frequency – IDF – counts how often a certain word occurs in a collection of documents. In this way, the uniqueness of a word within a document group can be calculated.
Inverse document frequency is a measure that is used in the field of Information Sciences to provide an indication of the number of documents in a document collection in which certain words occur. The size of the document collection is determined beforehand.
Where does the inverse document frequency come from?
The foundation for the IDF value was laid as early as 1972 by the British computer scientist Karen Spärck Jones. In her article, ‘A statistical interpretation of term specificity and its application in retrieval’, she was the first in her field to define how the incidence of a term/keyword can be calculated.
The idea behind this method is elegant and easy to understand: a word from a query that occurs in very many documents is not a suitable discriminator and should therefore be weighted less heavily than a word that occurs in very few documents.
How does the IDF help me in evaluations?
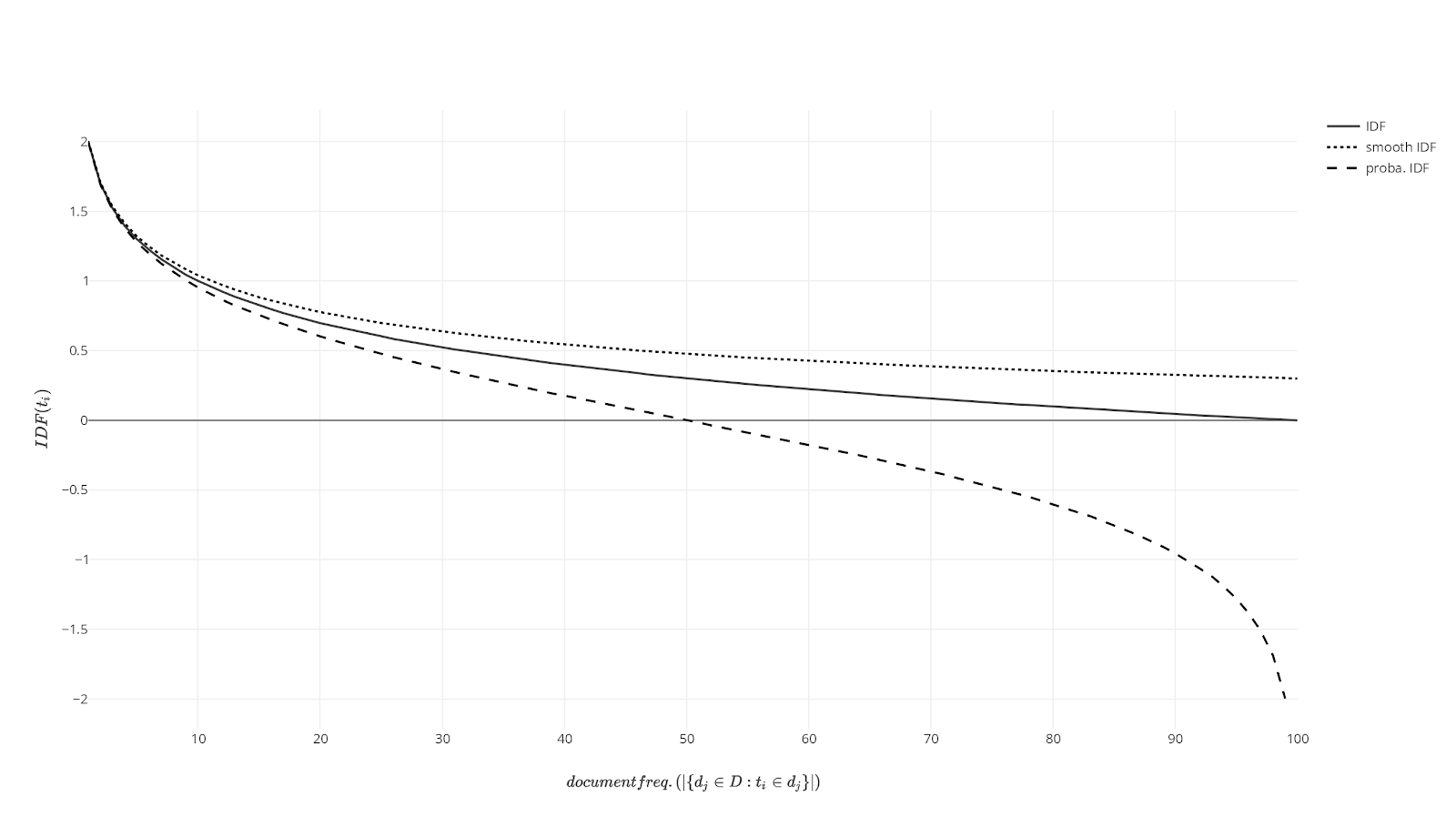
The Inverse Document Frequency for a given word (IDFt) divides the number of documents in the document collection (ND) by the number of documents in the collection that contain the given word (ƒt):
IDFt = log10( ND / ƒt )The more documents there are in the collection that contain this word, the smaller the IDF value for a word becomes.
This is a very good way of calculating stop words (commonly used words in any language), for example, as they occur in a large proportion of the documents.
Example 1 for IDF
An example would be a collection of 100 documents in which the word ‘the’ occurs in every document:
IDFt = log10( 100% of all documents in the corpus / 100% of the documents in the corpus that contain the particular word ) = log10(1) = 0.
The word ‘the’ has no unique feature in this collection of documents.
Example 2 on IDF
In the same collection of 100 documents, the word “it” occurs in 50 documents:
IDFt = log10 ( 100% of all documents in the corpus / 50% of the documents in the corpus that contain the particular word ) = log10(2) = 0.3
Due to the nature of a logarithm, an occurrence in 50% of the possible cases is no longer 50% of the total uniqueness, as is the case with the value 1, but a value of 0.3.
Example 3 on IDF
Last but not least, let us assume that the word ‘xylophone’ occurs in exactly one document in the above corpus of documents:
IDFt = log10( 100% of all documents in the corpus / 1% of the documents in the corpus that contain the particular word ) = log10(100) = 2.
The absolute uniqueness of a word within a document collection has a maximum value of 2, according to the above calculation.
{kind=link}
Conclusion
The IDF can be used as an effective counterpart to other metrics that are used to measure the incidence of terms by asking the following questions: which words occur frequently in a single document but are relatively unique across all the documents that we look at? Which words occur in all documents and are therefore probably less interesting?
This is the case if we are looking at either the pure keyword density (term frequency – TF) or a weighted value (Within Document Frequency – WDF).
IDF as a counterpart to Term Frequency and Within Document Frequency
In both the TF*IDF and WDF*IDF weighting evaluations, the IDF value has the function of giving a lower rating to words that occur in all documents.
The more often a word occurs in a document, the higher the TF/WDF value; the more often a word occurs across all documents, the lower the IDF.
Stop words, which occur in (almost) all documents thus lose importance, no matter how often they occur in a single document, since the IDF value for these approaches 0.