
The root directory is the top-level directory in a folder structure. All of the other folders grow outwards from the root directory, so it makes sense to think of the root directory as the trunk of a tree from which the branches grow.
Discover how SISTRIX can be used to improve your search marketing. 14 day free, no-commitment trial with all data and tools: Test SISTRIX for free
What is the Root Directory?
In a folder structure, the root directory is level zero. Data can already be stored in the root directory, and the structure of the system is such that the folders branch out from it, much like a tree. In most representations, the tree is upside down, with the root directory at the top.
Let’s look at a simple example of a root directory, in which there is a total of four folders that are distributed over three levels:
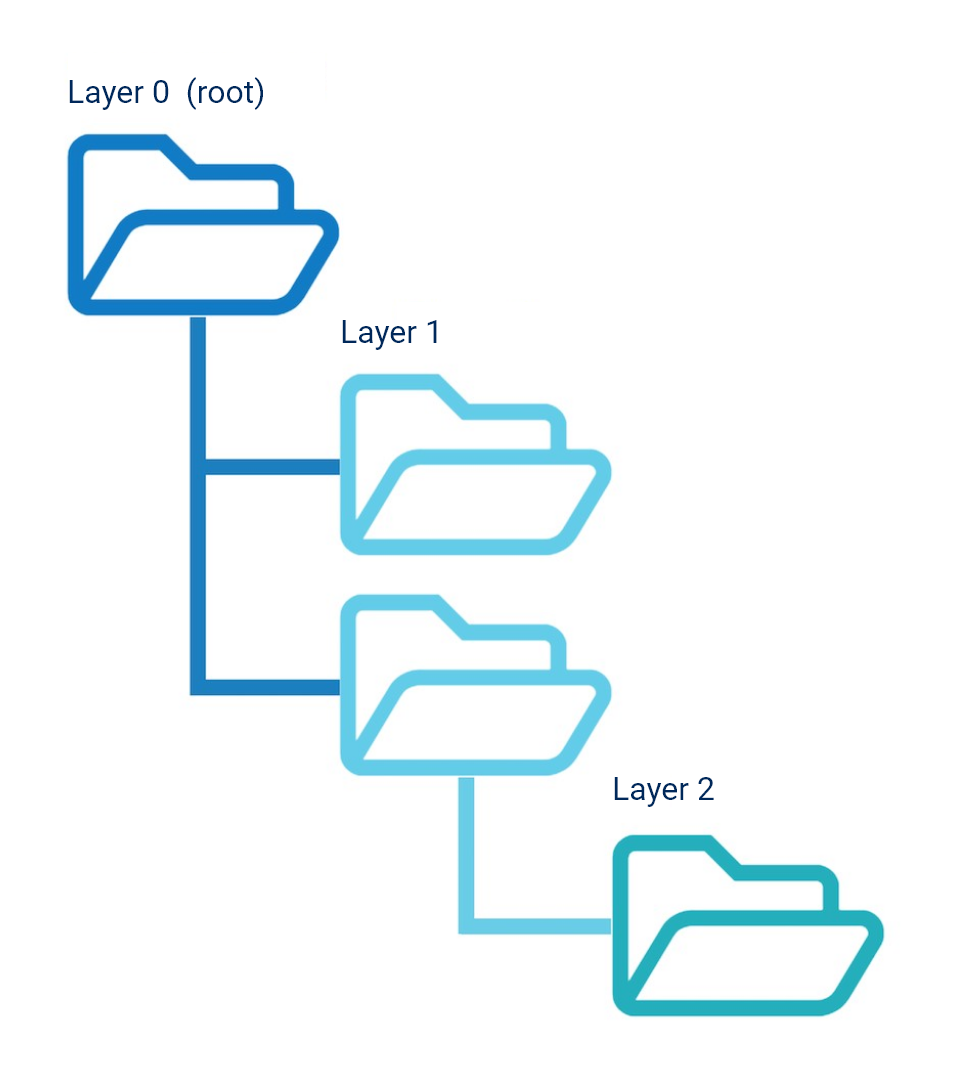
The root directory represents level 0 and a folder. Then there are two folders on level 1, one of which has another subfolder (level 2).
The same principle can be applied to a website. The root directory represents the start page, e.g. https://www.sistrix.com/. The first level can then be the category pages, e.g. https://www.sistrix.com/ask-sistrix/ and https://www.sistrix.com/blog/, with the second level encompassing subcategory pages, e.g. https://www.sistrix.com/ask-sistrix/onpage-optimisation/.
The Root Directory in Folder Structures and Website Structures
There are many parallels between the root directory of a website’s folder structure and the information architecture of a website. The homepage, for example, is the trunk from which the website grows.
Differences arise when information or articles are nested deep in the website’s structure. On the surface, an article in the first subdirectory (level 2) of the second subdirectory (level 1) is equidistant from the trunk in both representations. The big difference comes from how search engine crawlers handle this information.
The difference between the distance to the root directory and the distance to the home page
For Google, the distance separating a piece of information from the main entry point of the page makes a significant difference. The question of how deep the information is buried in the directory structure, on the other hand, is not as important.
Let’s take the above example and assume that each level can only be accessed from the previous level, so that the website structure corresponds to the folder structure.
In this case, users, much like search engine crawlers, need to take a total of two steps (clicks) to reach the document on level 2:
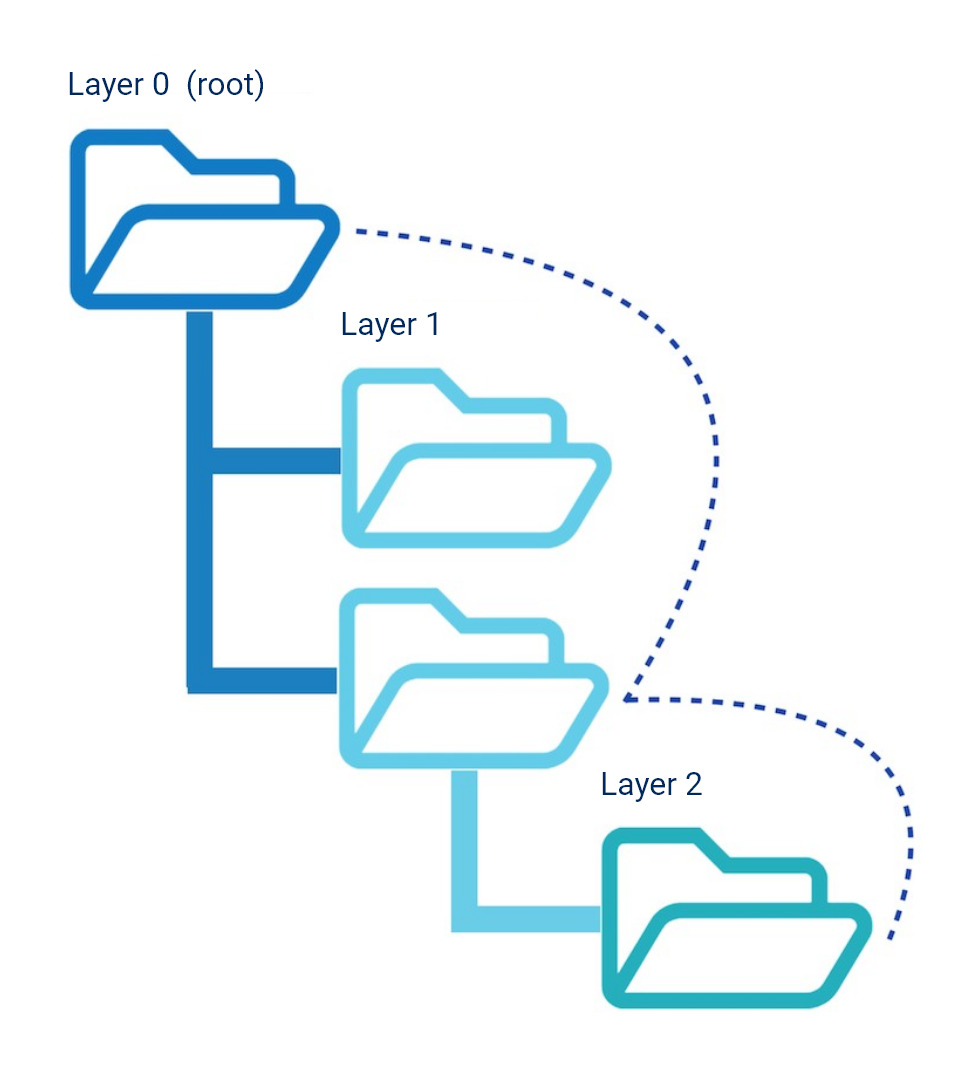
However, Hyper-Text Markup Language enables documents to be linked to one another. This makes it possible to link to the desired document, at the second level, directly from the domain’s homepage. Users and search engines can therefore reach this document with one click:
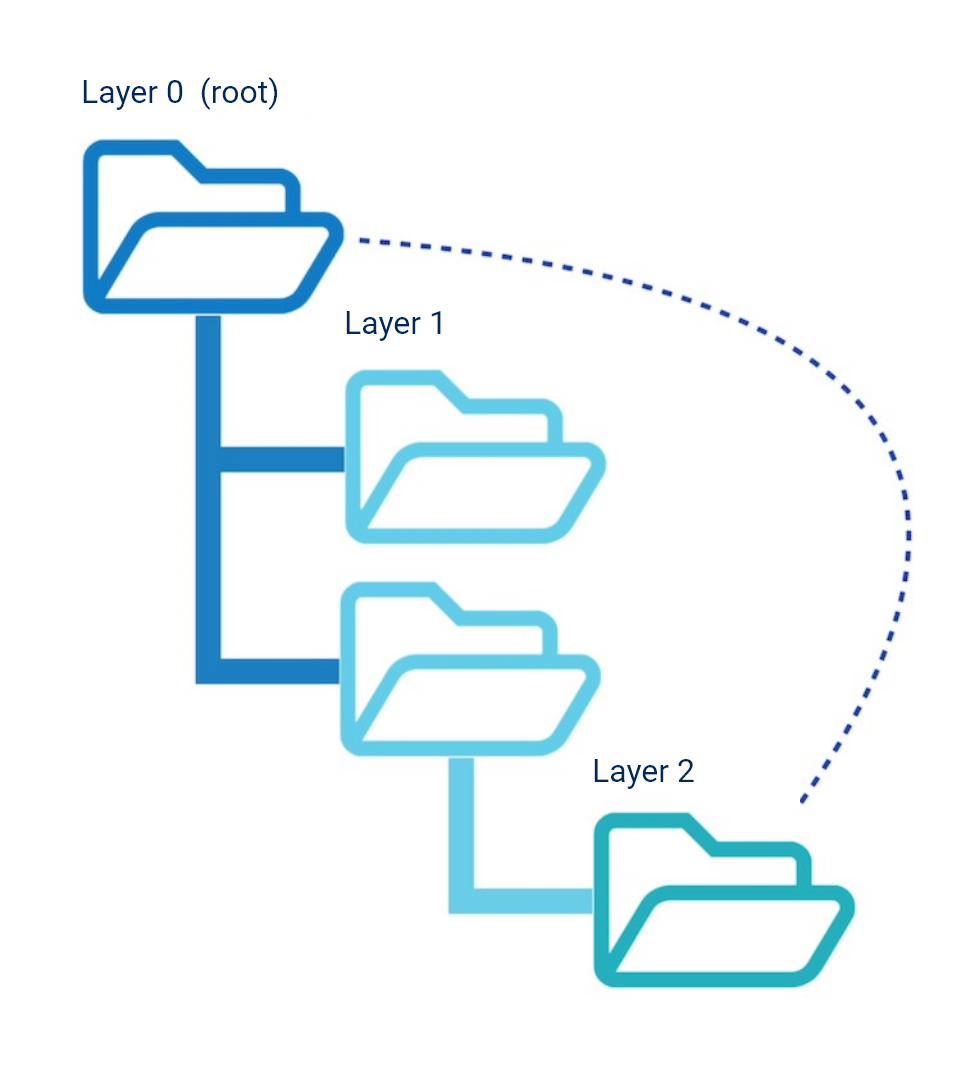
Google would interpret this as an indication that the article in the second example is more important than in the first. The question of how many clicks a document is away from the homepage is much more relevant, then, than the depth of this document in the folder structure of the page, which is not as important.
Test SISTRIX for Free
- Free 14-day test account
- Non-binding. No termination necessary
- Personalised on-boarding with experts