
A trailing slash is the last slash in a URL. Depending on its position, it can either have an impact on the URL or be discarded by browsers and search engines.
The trailing slash at the end of a URL originally had the purpose of distinguishing a directory (https://sistrix.com/ask-sistrix/) from a file (https://sistrix.com/ask-sistrix.html).
Since URLs today are, for the most part, created virtually and no longer have a direct reference to the files in the web server’s file system, the purpose of trailing slashes has changed.
The trailing slash in the URL can have an impact on the URL, depending on its position, and this can lead to duplicate content problems for Google.
John Mueller from Google has addressed the issue. Here, he explains when trailing slashes can make such an impact:
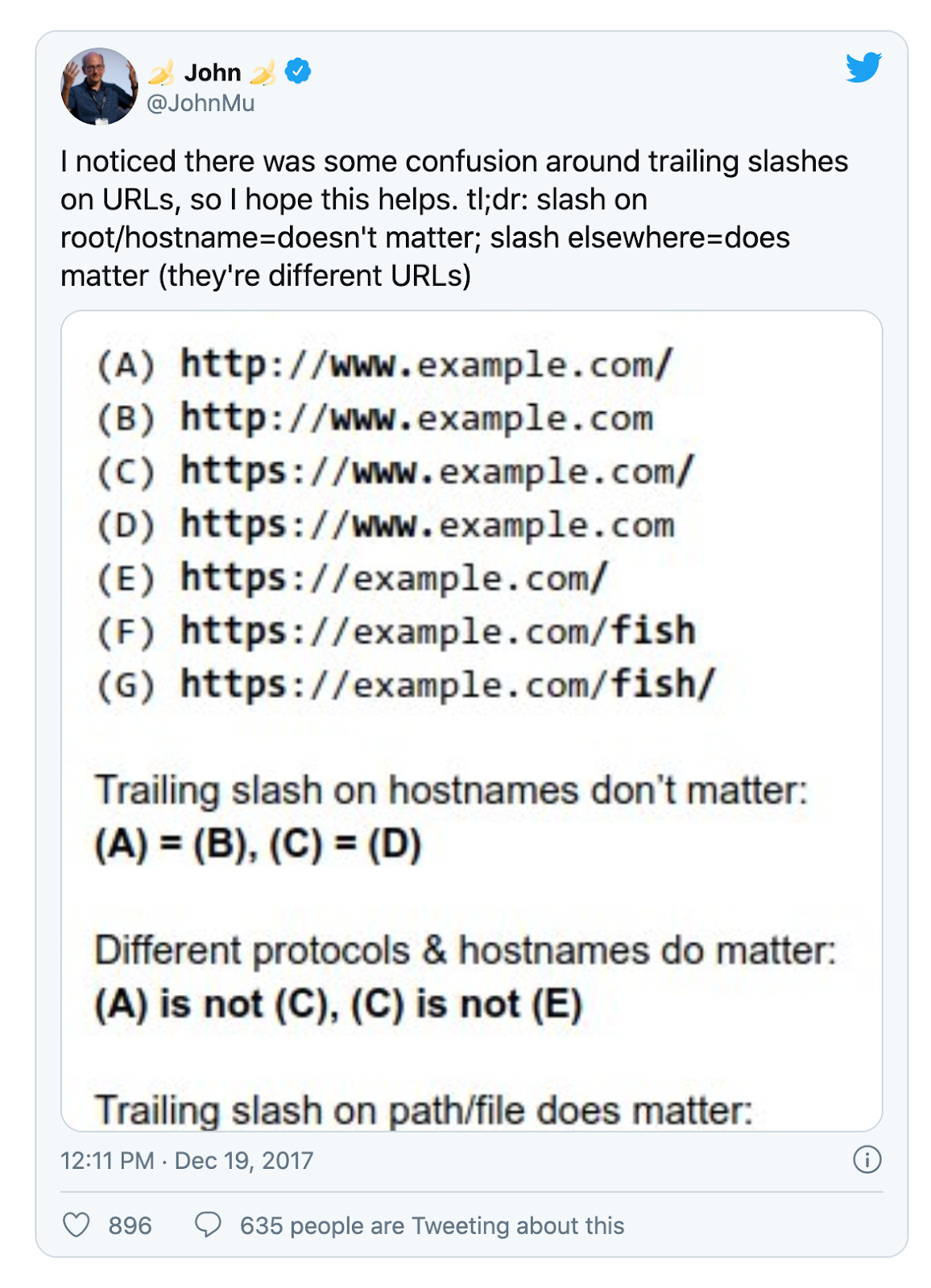
At the end of a host name, it makes no difference whether there is a trailing slash or not. Accordingly, both a browser and Google would treat https://sistrix.com exactly the same as https://sistrix.com/.
The situation is rather different, however, if the slash is part of a path on the website. Let’s take ‘Ask Sistrix’ as an example. Here, it makes a difference for browsers and other users, such as the Googlebot, whether a page is located at https://sistrix.com/frag-sistrix or https://sistrix.com/frag-sistrix/.
In this case, there are two different URLs, each of which can provide its own resources and give different answers to a querying system (a browser, for example).
With respect to search engine optimisation, this means that problems with duplicate content can arise if your system does not differentiate between URLs with or without a trailing slash. If it does not differentiate, the system will display the same content on both versions of the URL and return a 200 status code (OK).