
SEO, Search Engine Optimisation, is fairly simple and in this guide we’ve summarised it down into useful nuggets of information that you can work through and understand. By understanding this, you’ll be well on your way to improving your own visibility in Google Search.
- SEO - Google's definition
- How does Google Search work?
- A simplified view of the process.
- Crawler
- Index
- Ranking Algorithm
- Search Engine Results Pages (SERPs)
- 6 good reasons to practice SEO
- The Google SERPs
- Element #1: SEA (Google Ad)
- Element #2: SEO (Organic search results)
- Element #3: Universal Search
- Other SERPs features.
- Element #4 AI Overview.
- Element #5 Featured Snippet.
- Element #6: Knowledge-Graph
- Element #7: Google Shopping
- Domain, Subdomain, Host and URL
- Google Ranking Factors
- Google is your source for successful SEO
- Help Google to find your website
- Help Google to understand your website
- Help the visitor to use the website
- Basic principles of the quality evaluator guidelines
- Avoid the following methods
- What does the Search Quality Evaluator Guideline cover?
- SEO Glossary of Terms
- Further reading
SEO – Google’s definition
What is SEO? Let’s start by looking at Google’s definition of SEO? “By making sure search engines can find and automatically understand your content, you are improving the visibility of your site for relevant searches. This is called SEO”.
How does Google Search work?
Google is the most-used search engine in Europe. In the UK there’s a market share of about 90% and as a result, Google has the natural lead on defining which SEO methods are allowed, and what isn’t.
When you search for a keyword or term on Google, the results are displayed almost instantly but how does Google find the websites that are relevant, and how does it order the results?
A simplified view of the process.

Crawler
The Googlebot crawls (searches through) billions of web pages every day searching for new and updated content and it adds some of these pages to its index.
Index
In order for a website to be found through search, Google needs to have it in its index. Google must also add relevant information about the site to its index.
Ranking Algorithm
When a search is started, Google looks for results based on a ranking algorithm.
Search Engine Results Pages (SERPs)
Google uses about 200 ranking signals to find the best result in the index for the given query. All the matching results will form the search results list – the SERPs (search engine results pages.)
Our reference library includes a complete range of articles about crawling, indexing and Google’s ranking algorithm.
6 good reasons to practice SEO
SEO is free. In comparison to Google Adwords which can also appear in the search results, there is no cost involved with being listed in the ‘organic’ search results.
SEO brings relevant traffic. If you interpret the search intention of the user correctly and present matching content, the search results can provide high quality traffic.
SEO is more relevant than SEA. In our research at Sistrix we found that 93% of clicks go to organic search results. (7% to search engine advertising.)
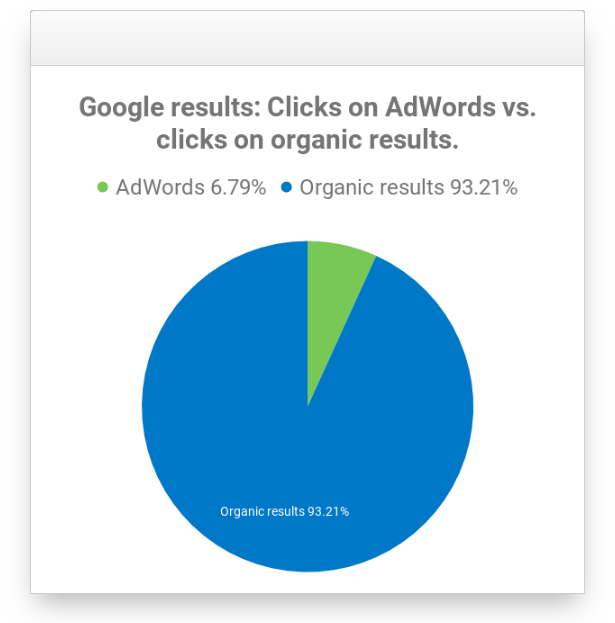
Reducing competition through SEO.. The ranking positions are limited (normally 10) so with good SEO, one can displace the competition by generating a higher-position presence in the Google SERPs.
SEO can strengthen an Image. Brand awareness for target-groups can be improved through increased visibility in the search engine results.
The Google SERPs
SERPs are presented in different ways on different screen sizes. A typical desktop search result in Google, a SERP, is usually formed of the following elements. In the top half you’ll often find the Google Ads. These don’t appear for all search results. Underneath the Ads you’ll find the start of the important organic search results.
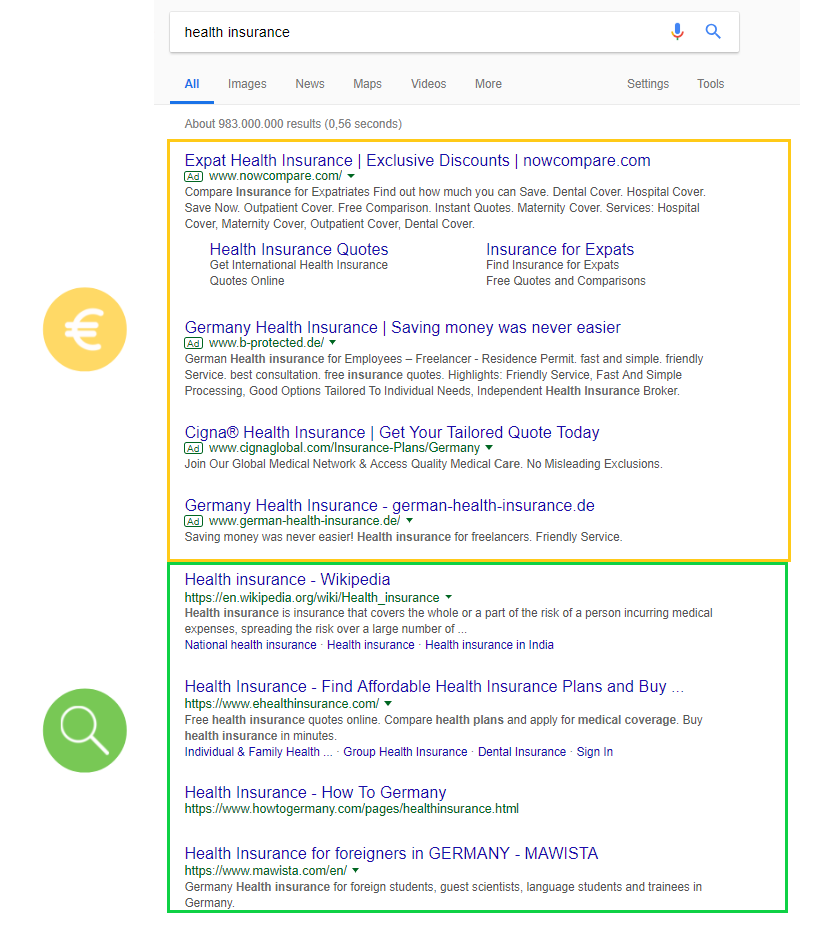
In addition you’ll find the universal search modules shown, in mobile form, below.
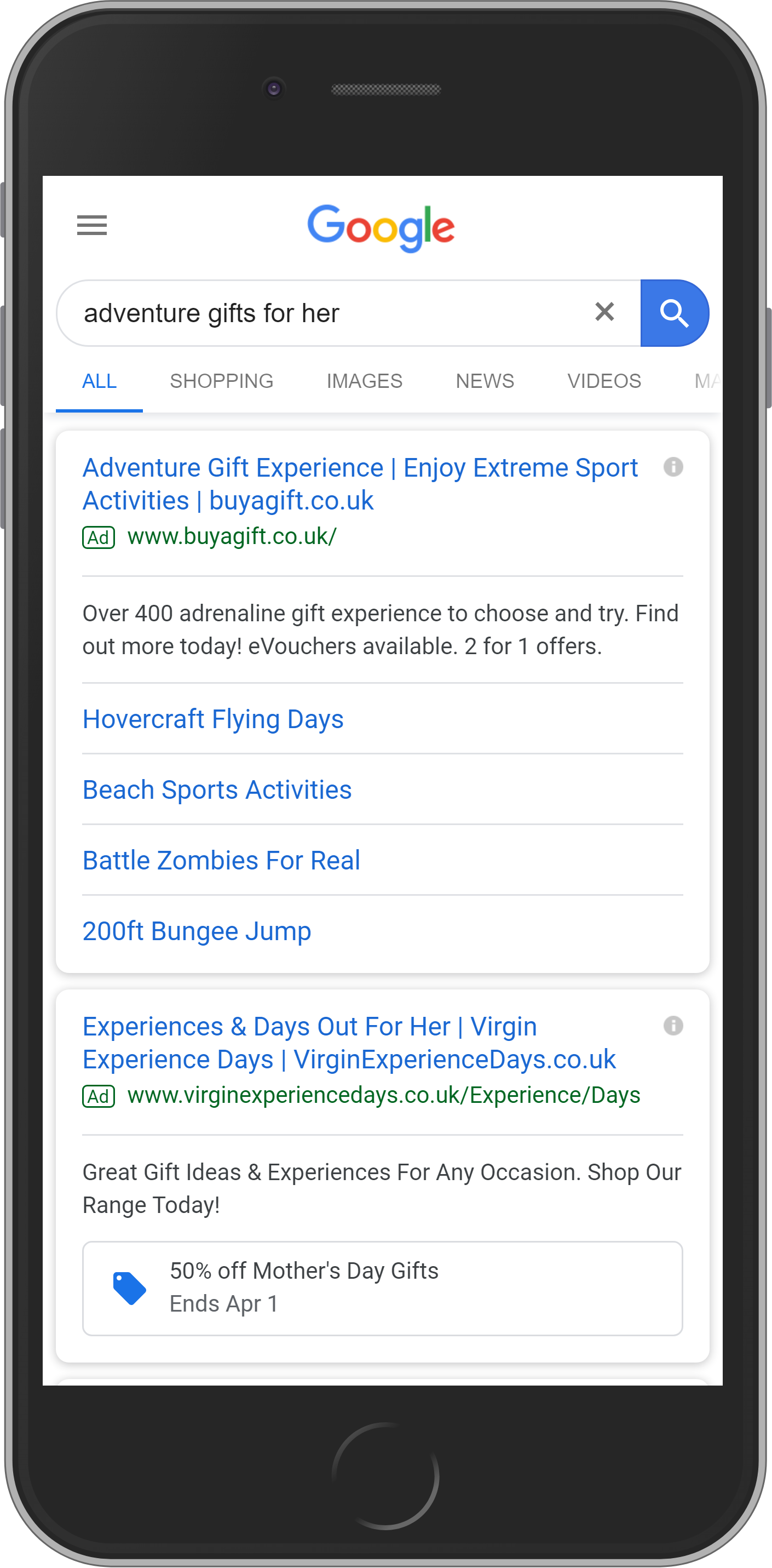
Element #1: SEA (Google Ad)
Most SERPs include Google Ads above and up to three Google Ads below the organic search results. All ads are marked with “Ad” next to the URL.
Element #2: SEO (Organic search results)
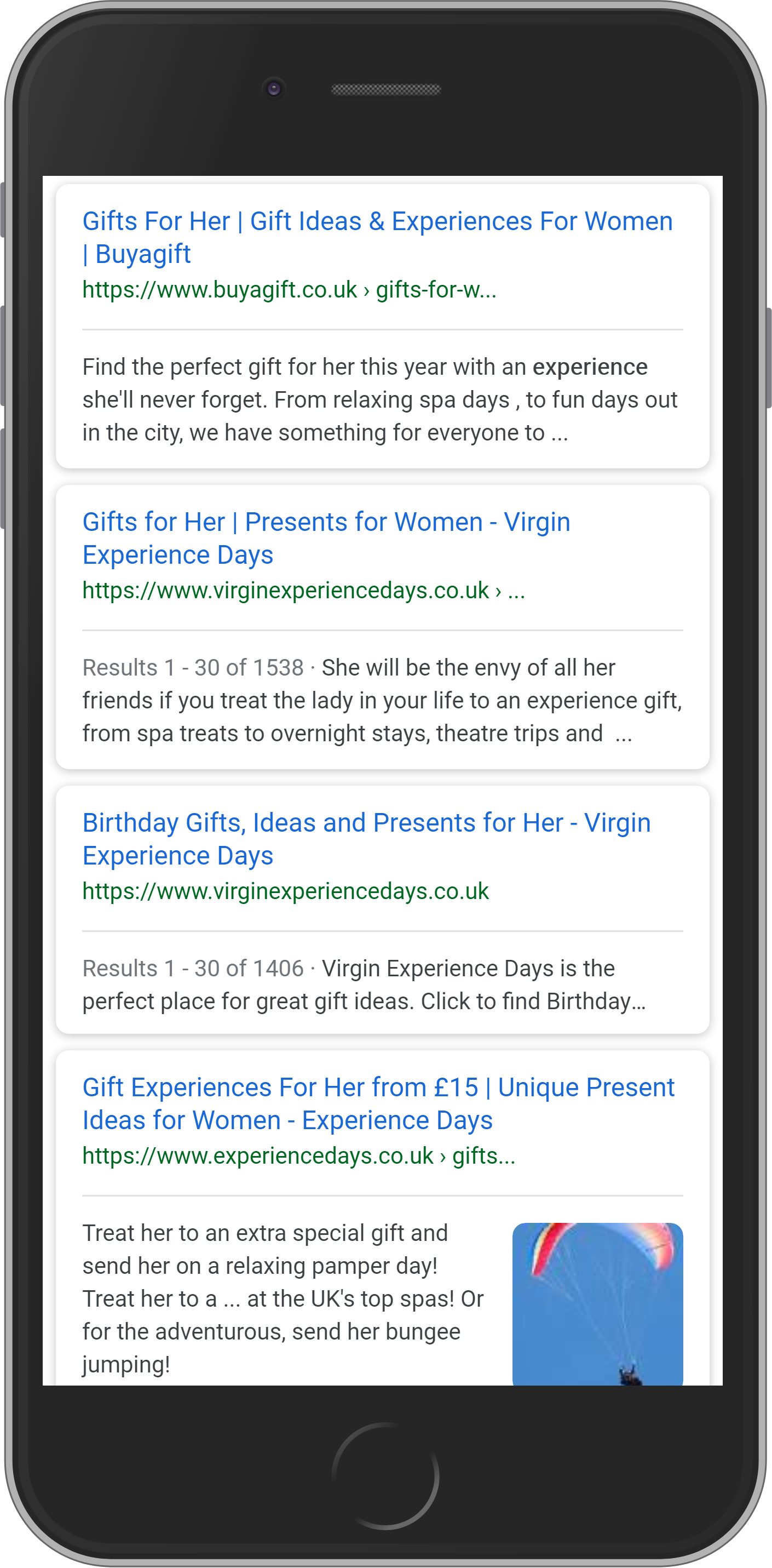
You’ll find the organic search results (SEO results) between the two paid search (Google Ad) sections.
As a rule of thumb you can expect 10 organic search results in this area and they count as SEO results.
Element #3: Universal Search
The third important search element is a Universal Search box. The results here are taken from other Google search products such as News, Image and Maps and are automatically integrated in the page.
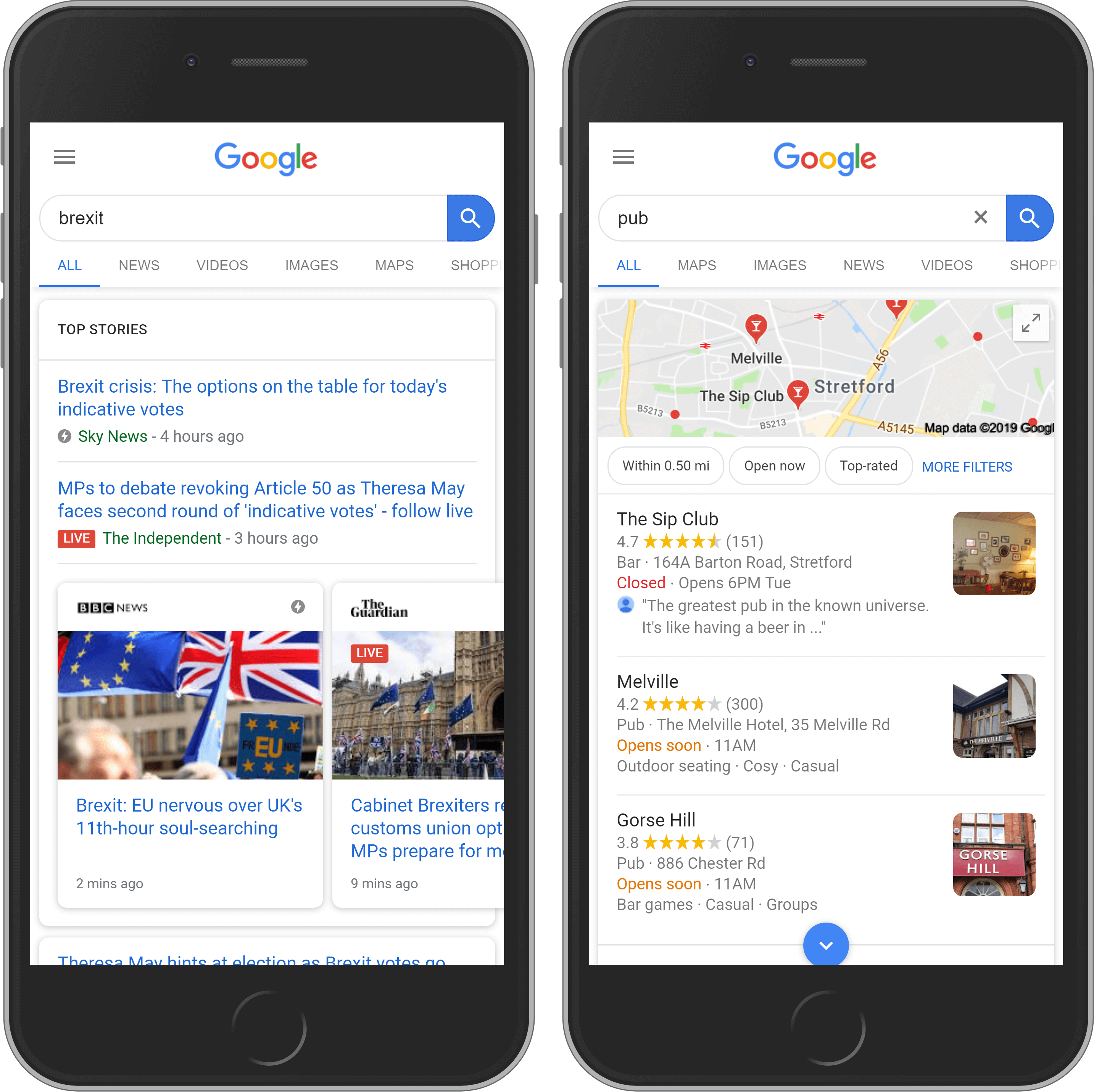
Other SERPs features.
In addition to the three elements described above there are a number of additional SERP results that, depending on the type of search, can appear in the results. Here are some examples.
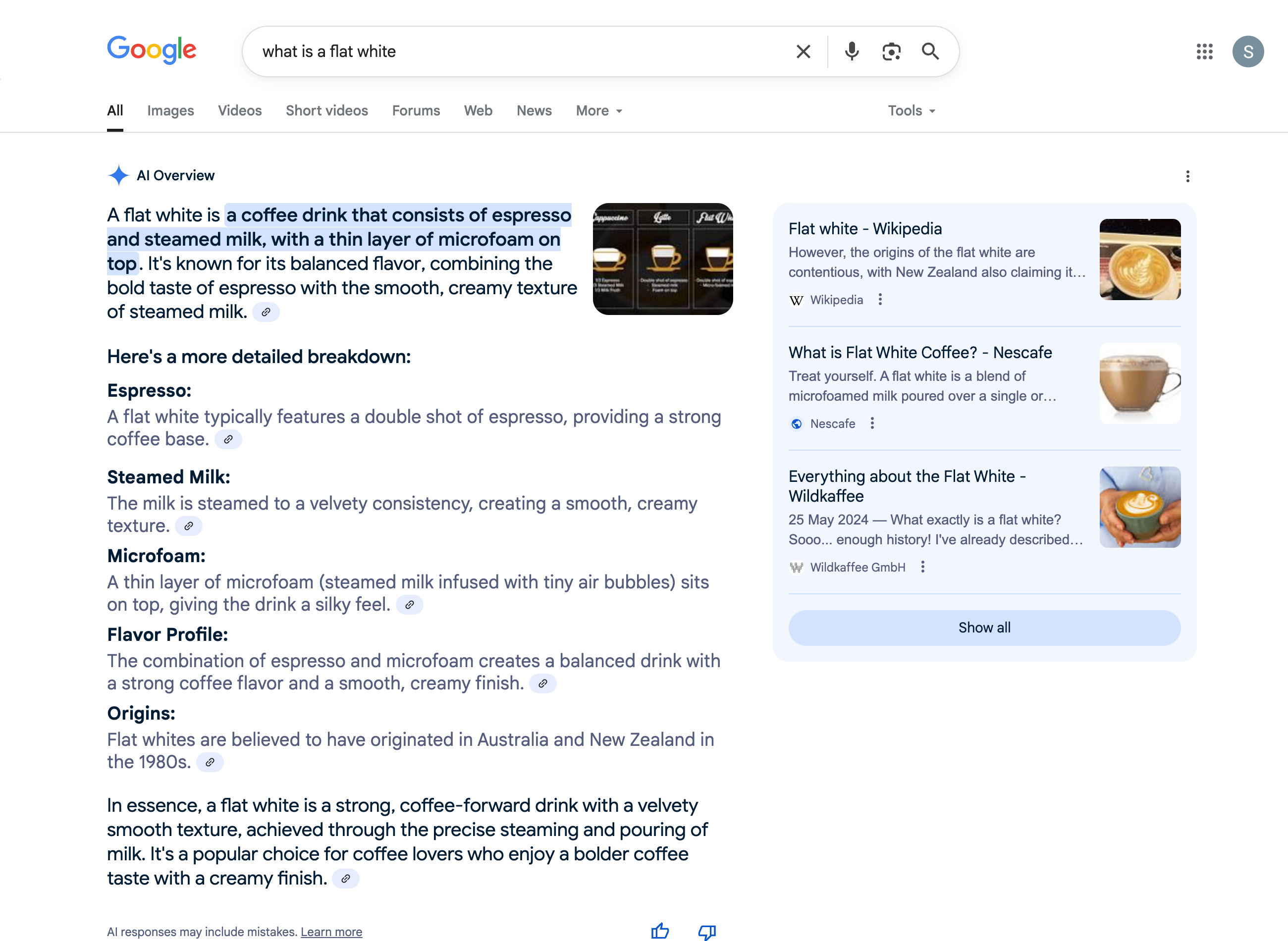
Element #4 AI Overview.
The AI Overview, or AIO, is a summary of results aimed at solving a users query with Google-generated text. There are often links in this summary.
It appears in a large number of search query results. You can find out more, here.
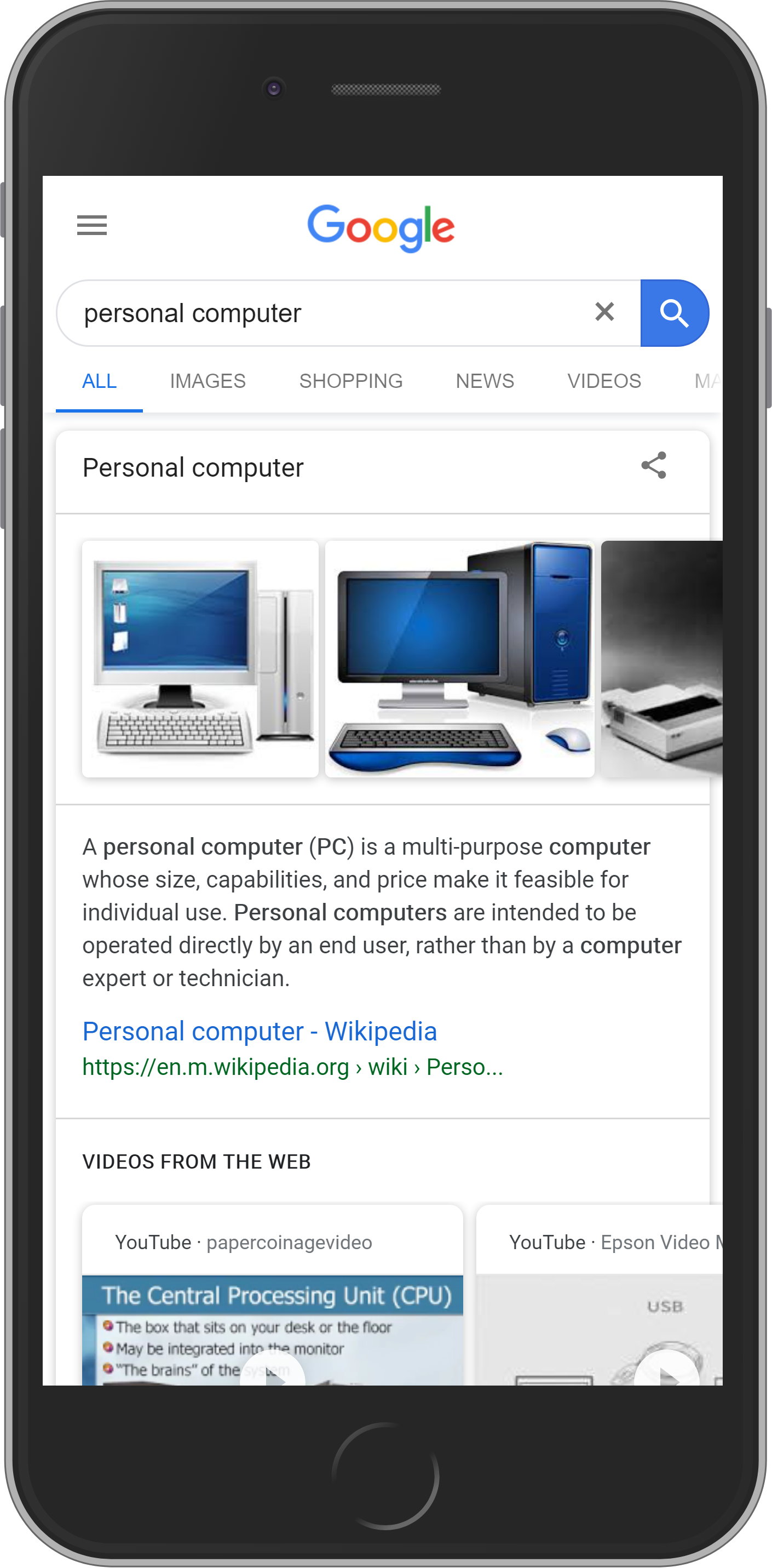
Element #5 Featured Snippet.
A featured snippet is an extended SERP snippet. The additional information can appear in the form of text, video, lists or tables.
The featured snippet will always be found at ‘position zero’, above the organic search results.
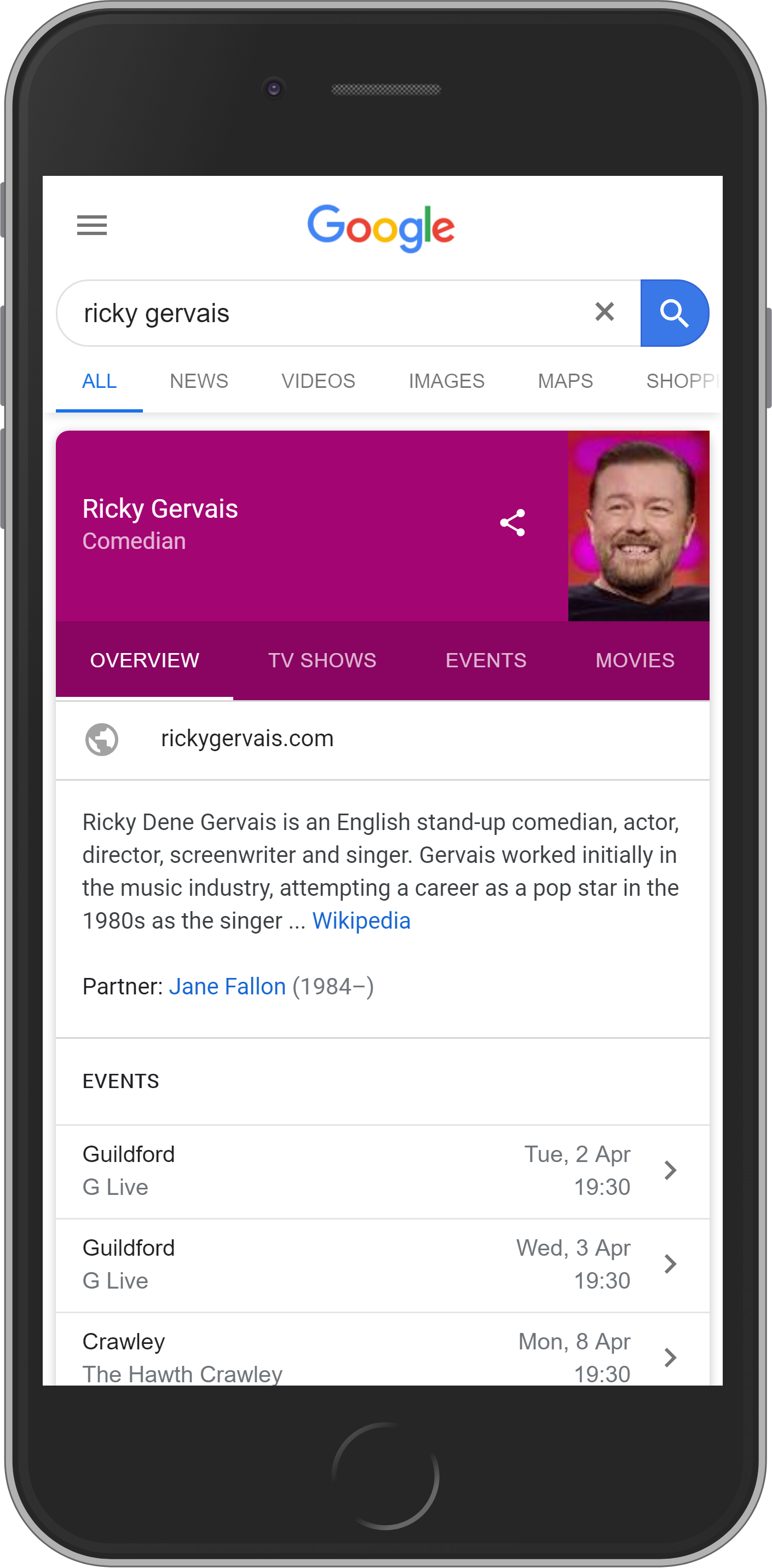
Element #6: Knowledge-Graph
The knowledge graph will appear to the right of the search results on the desktop version and inline as the first result on mobile. It contains a selection of information for places, people and common subjects.
Element #7: Google Shopping
A Google Shopping element is often found to the right of the search elements (desktop search) but can also appear above the SERPs. It usually appears in the carousel or tiled format.
Domain, Subdomain, Host and URL
A Web address is formed from different components.
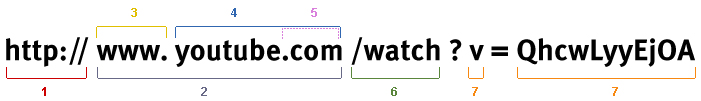
- The protocol used. In most cases today this is an HTTPS protocol – Hypertext Transfer Protocol (Secure) but FTP and other protocols are sometimes supported by browsers.
- The hostname: www.youtube.com which is formed of
- The subdomain: www. (or blog. , news. , support. , …)
- A domain name
- The Top-Level-Domain (TLD) In this case, .com
- The path: /watch. This is often simply a sub-directory on the web server (but does not have to be.)
- Parameter & Value: Parameters are specified after the “?” character. In this case the parameter is “v” and the value is “QhcwLyyEjOA.” These can be interpreted by the web server for further processing.
It’s generally understood that when someone talks about a URL, they are referring to a path in a directory ( https://www.reddit.com/r/Unexpected/ for example) or to a file ( C:\Users\Steve Paine\Pictures\Frag-SISTRIX_URL-Aufbau.jpg )
More information about the differences between a domain, path and URLs.
Google Ranking Factors
When we talk about Google search and the search algorithm there are factors that will influence how the results are positioned and shown in the search results.
Finding a trusted source of data for Google Ranking Factors is not easy as there’s a lot of incorrect information in circulation.
The best advice is to use Google as an information source and to that end, we recommend the following document.
Search Engine Optimization (SEO) Starter Guide.
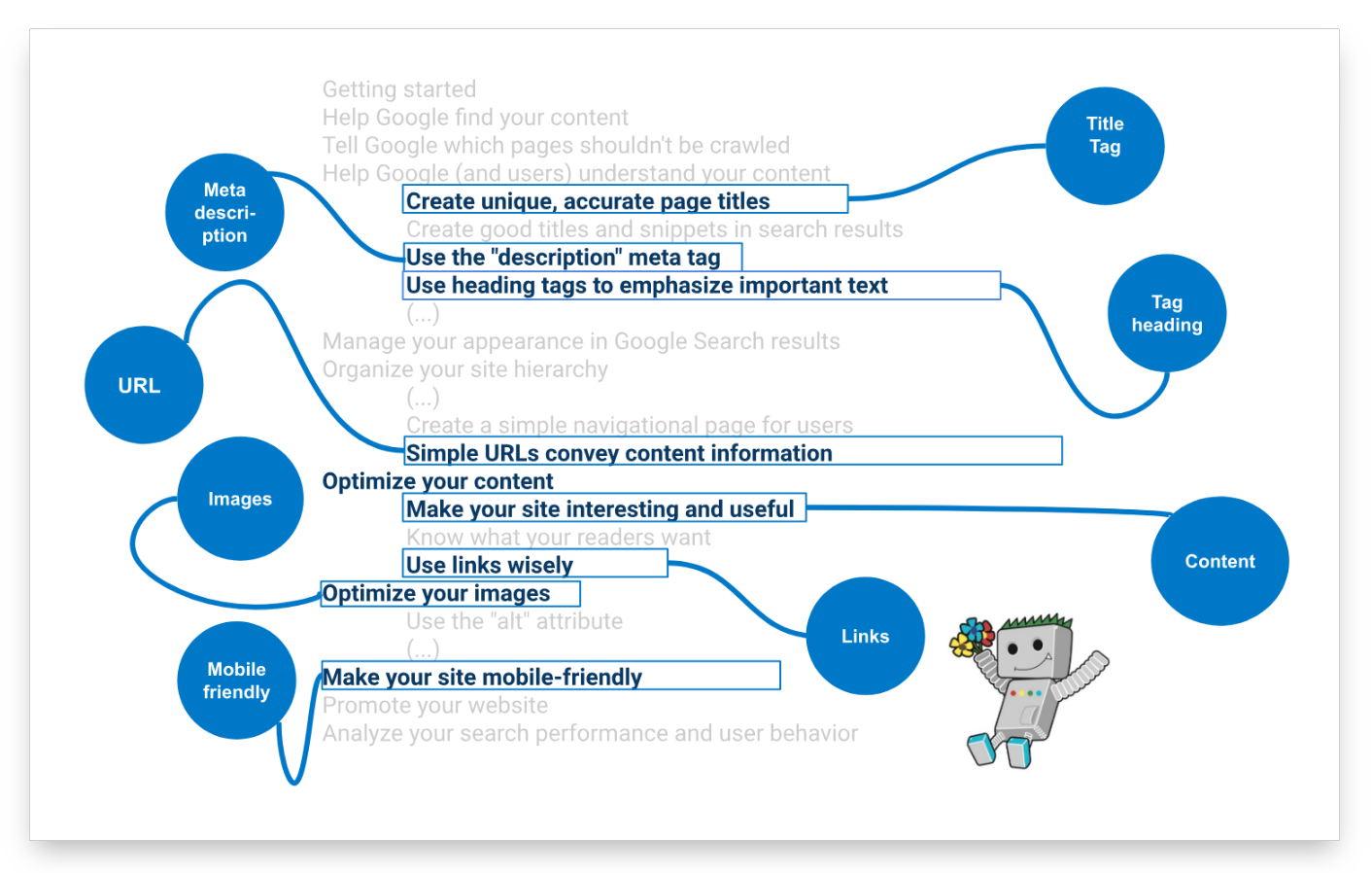
Among many other things, you’ll find more detailed information on the most important ranking factors.
Google is your source for successful SEO
For successful and sustainable SEO one should, in addition to the above guide, use the following resources for useful tips and to learn how search results are created.
Let’s take a quick look now at some of the advice for webmasters. What criteria does Google list?
Help Google to find your website
- Ensure all your pages are discoverable via internal links.
- Use a sitemap
- Keep the number of internal links to a minimum
- Use the HTTP-Header If-Modified-Since
- Manage the Crawling-Budget (robots.txt)
- Submit the website to Google (Search console)
Help Google to understand your website
- Create a helpful and informative Website.
- Understand the search intention of your target audience and create content that supports this.
- Use a clear site hierarchy.
- Ensure your CMS is not blocking Google from accessing content.
- Ensure that other assets, such as CSS and Javascript data, is accessible by Google.
- Reduce the visibility of session-IDs and URL-Parameters for search robots.
- Prevent crawlers from following advertising links with the help of robots.txt or rel=”nofollow”
Help the visitor to use the website
- All links should be valid and pointing to live pages.
- Optimise the loading time of the website.
- Make the website compatible for different screen sizes.
- Make the website compatible with different browsers.
- Create a barrier-free website. (Text sizes, colours, positioning, for example.)
Basic principles of the quality evaluator guidelines
- Create a website for users, not for search machines.
- Don’t create different user/crawler experiences via cloaking
- Avoid the use of manipulative ranking tricks
- Create a unique website experience
Avoid the following methods
- Link exchange programs
- Cloaking
- Bridging or Doorway pages
- Hidden links
- Copied content
- (…)
What does the Search Quality Evaluator Guideline cover?
The core of the search quality evaluator guideline is for the manual testing of new search engine algorithms by contracted third parties.
However, through the guidelines, 160 + pages long, it’s possible to get a feel for where Google wants to see quality.
The full PDF document is available here and it is highly recommended reading.
SEO Glossary of Terms
You’ll find a lot of specialist words used in the world of SEO. To help you understand them we’ve create a list of the most important terms and their definitions.
AI Overview. Google often summarises search results with an AI generated feature box at the top of the search results. This is known as the AI Overview, or AIO for short.
Alt-attribute. This is related to the alternative labelling of an image. Google is able to understand the content of the image through the use of a short and precise description that contains important keywords.
Anchor text. The description of a link is known as the anchor text. In practice it’s simply the highlighted, clickable part of the text link.
Backlinks. Backlinks are the name of links that connect one domain to another, external domain. Users can click on these links to access the external content. These are still important ranking factors for Google.
Bounce-Rate. This value, also known as the jump-rate, shows how often a user leaves a website without having viewed at least one more page on the site.
Canonical Tag. With the canonical tag you’re able to set the original URL. If there are pages on a website with the same content, Google can use the canonical tag to understand that only one page is the ‘master’ and thus avoiding the indexing of duplicate content. Tip: There are only a few legitimate uses for a canonical tag where it mostly serves as a ‘band aid’ for other problems that can’t be solved.
Conversion. An expression used in online marketing practices where a final action occurs after a user has landed on a page. For example, a purchase, a download or a subscription.
Duplicate Content. Where the same content is found on multiple URLS it is known as duplicate content. It’s important to avoid this and to make sure that the content is only accessible through one URL. If not, Google is not clear which URL should rank for that content and what positive ranking signals should be attributed to those URLS.
Crawler. Automated software that views site content, follows links, reads sitemaps and records structure and content as it goes.
Featured Snippet. A snippet is a piece of information that can directly answer the users query. A featured snippet is formed from the Title Tag, URL and the answer for the query. It can take the form of text, a video, table or a list.
Follow-attribute. With the ‘follow tag’ it’s possible to tell search engine crawlers to follow links. External links that are followed pass ‘link juice’ , an important signal for Google, to the linked site.
Google PageRank. PageRank is a value attributed to a website through an algorithm created by Google founders Larry Page and Sergei Brin. The value from 1 to 10 (and no longer made available for public viewing) is a value of the reputation of a site based on the number and value of incoming links. It continues to be used as part of Google’s algorithm.
Googlebot. The common name of the Google crawler. Googlebot continuously crawls the internet for websites.
HTTP Status code. An HTTP status code is sent from every web server as an answer after every HTTP or HTTPS request. The values fall into ranges with different meanings. For example 200 to indicate a successful request for content, 3xx, 4xx or 5xx along with many more.
Hreflang attribute. By using the hreflang attribute you can ensure that Google understands the geographic target of the website and delivers the correct language or regional URL to the user.
Index. Every web page that’s known to Google is added to their index. The index entry describes the content and the location (URL).
Indexing is the process of retrieving a page, reading it and adding it to the index.
JavaScript. Javascript is a coding language that enables a variety of design and implementation options such as image carousels and page interactivity that can be included in a web page.
Meta Description. The meta tag “description” summarises the topics covered on the page for Google and other search engines. The title of a page may include a few words or an expression. The “description” meta tag of a page, on the other hand, can contain one or two sentences or even a short paragraph. Google Search Console provides a handy HTML enhancements report that provides information about too short, too-long, or too-often-duplicated “description” meta tags. The same information is also available for <title> tags. Like the <title> tag, the description meta tag is also placed inside the <head> element of the HTML document.
Meta-Tags. Meta tags allow webmasters to provide information about their websites to search engines. Meta tags can be used to provide information to a wide range of clients. Each system processes only the known meta tags and ignores the unknown tags. Meta tags are placed in the <head> section of the HTML document.
Mobile-Friendly. This refers to the usability of a page on a mobile screen.
nofollow attribute tag. The nofollow tag communicates to the search engine that it should not follow one or more links on a page. Thus, the linked page is not crawled. In addition, the nofollow attribute value does not propagate PageRank ‘linkjuice’ to the linked landing page, so the nofollow attribute should never be used for internal links.
noindex value. The meta-robots value “noindex” instructs a search engine not to include the corresponding page in the Google index. Indexing of a page (URL) can thus be actively controlled by the webmaster.
Robots.txt A robots.txt file is a file in the root of the Web site that specifies the parts of the Web site that search engine crawlers should not access. The file uses the Robots Exclusion Standard, a simple protocol with a few instructions that are communicated in the text file. This file specifies the accessibility of the site for individual sections and for different types of web crawlers, such as: Mobile crawlers, as opposed to desktop crawlers.
SERP. The SERP or Search Engine Result Page, lists the search results (also known as hits) to a search query (keyword) on a search engine (Google). There are usually 10 natural or organic hits and 3 to 5 paid Google ads.
SERP Features. This is the name we give, inside the SISTRIX Toolbox, to the different forms of snippets that may appear in Google search results. Examples are: images, Adwords, news boxes, knowledge graphs and maps.
SEO. Search Engine Optimisation describes all the measures that can be take to increase the profitability of a website by targeting visitors through the organic search results.
TLD. Top Level Domain. Part of the domain name found at the end. Common examples are .com .org. and country top level domains such as .uk
Title-Tag. The title tag represents the title of a URL and is displayed, for example, in the web browser tabs. In most cases, Google also displays the title tag as the heading of a search results hit (SERPs). The content of the title element of a page (URL) is a strong ranking factor and should therefore always be set.
301 redirect. A 301 redirect is an HTTP status code 301 – Moved Permanently. This means that the content of a URL has been permanently moved and can now be found under a different (new) URL.
302 redirect. A 302 redirect is an HTTP status code 302- Moved Temporarily. This means that the content of a URL been moved for a limited time and can now be found under a different (new) URL.
Further reading
- Ask SISTRIX – Getting started articles – Our reference library of SEO information for beginners
- How Google Search Works – What Google says about search
- The SISTRIX Blog – case studies and news