
In this post we are going to explain what the canonical tag is and what we need to know to use it in our SEO project. We’re also going to talk about how you can analyse and audit this link element.
- Lily Ray talks about the canonical tag. What is it, and when would you use it?
- Canonical Tag Definition and meaning
- Nomenclature, considerations and errors to avoid
- Implementation procedures
- HTML tag
- HTTP header
- Other signals: sitemap and internal links
- Effect and SEO cases
- How to analyse or audit canonical tags
- Explore the source code
- Chrome developer tools
- On Google Search Console
- How to analyse canonical tags using the SISTRIX Toolbox Optimizer
- Crawling and detection of warnings
- URL explorer: analyse individual URLs
- Expert mode
Discover how SISTRIX can be used to improve your search marketing. 14 day free, no-commitment trial with all data and tools: Test SISTRIX for free
Lily Ray talks about the canonical tag. What is it, and when would you use it?
Canonical Tag Definition and meaning
The canonical tag is the HTML element we use to let Google know that 2 or more URLs on our website are duplicate, similar, or identical.
This tag allows us to ‘select’ which of the multiple URLs should be displayed in the SERPs, to help Google decide which page it should ultimately show in the results. In other words, we are providing Google a signal indicating the preferred version to be indexed.
Besides strengthening this indexing signal, it also consolidates our internal links pointing from the URL of origin to the target canonical URL.
With regard to duplicate content and various myths floating around in the industry, there’s no better way to clarify it than by citing official sources and references coming from Google itself:
“Let’s put this to bed once and for all, folks: There’s no such thing as a “duplicate content penalty.” At least, not in the way most people mean when they say that. You can help your fellow webmasters by not perpetuating the myth of duplicate content penalties!”
Susan Moska
https://webmasters.googleblog.com/2008/09/demystifying-duplicate-content-penalty.html
“Duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar. Mostly, this is not deceptive in origin.”
https://developers.google.com/search/docs/advanced/guidelines/duplicate-content
Nomenclature, considerations and errors to avoid
Here are the main considerations regarding the canonical directive, and ways to specify it:
- A canonical can be self-referential, especially on the home page, as it can have several access points generated by the CMS or the server itself (index.html, to name one).
- A canonical must be used whenever there are two pieces of content that are similar, duplicate, or, in other words, totally or partially identical. Otherwise, this tag can be ignored.
- A canonical must point to an indexable URL, returning 200 OK and not carrying a noindex tag. Another thing worth mentioning is that we shouldn’t send a canonical to an irrelevant URL, because it will be interpreted as a Soft 404.
- There should only be one unique canonical for each URL. If there are two different canonical tags, they may clash and both end up being ignored.
- A canonical can use absolute and relative URLs. However, it’s important to point out that relative URLs are prone to errors and oversight.
- A canonical tag can be ignored if there are obvious errors, in terms of their spelling or other unintentional mistakes. There may be other signals, which will be analysed to determine whether a canonical tag should be respected or ignored.
- A canonical tag can also be ignored if we’re sending confusing signals, like referencing a canonical from url1 to url2, and then from url2 to url1. To incur in this kind of “loops” can result in unexpected behaviour.
- A canonical can be cross-domain, i.e. point from domain1 to domain2. It should be used –preferably– when we have control over both domains and we want to favour indexing of one domain over the other to prevent duplicities. Be cautious with this.
- Another example can be content syndication.
Provided that it solves duplicate content situations between pages, some of the most typical cases where we’ll have to deal with this, are:
- URLs with www vs URLs without www
- URLs with http vs URLs with https
- URLs ending with / vs URLs not ending with / (not counting the home page)
- URLs with parameters vs URLs without parameters (like urls with session IDs).
- URLs with pagination vs URLs without pagination
- URLs with AMP vs URLs without AMP (as a required markup).
- Mobile URLs (m-sites) vs desktop URLs
- Pre (staging) URLs vs prod (production) URLs (anyway, it’s better to keep Google out of the staging is per HTTP-Login)
- Etc.
Albeit all these situations could be solved using canonical tags, there is another, more direct method for Google: 301 redirect.
You’ll read plenty of 301 and canonical tag comparisons. We’re not going to delve too much into it, but we are going to stress the most important points regarding this matter in the image below:
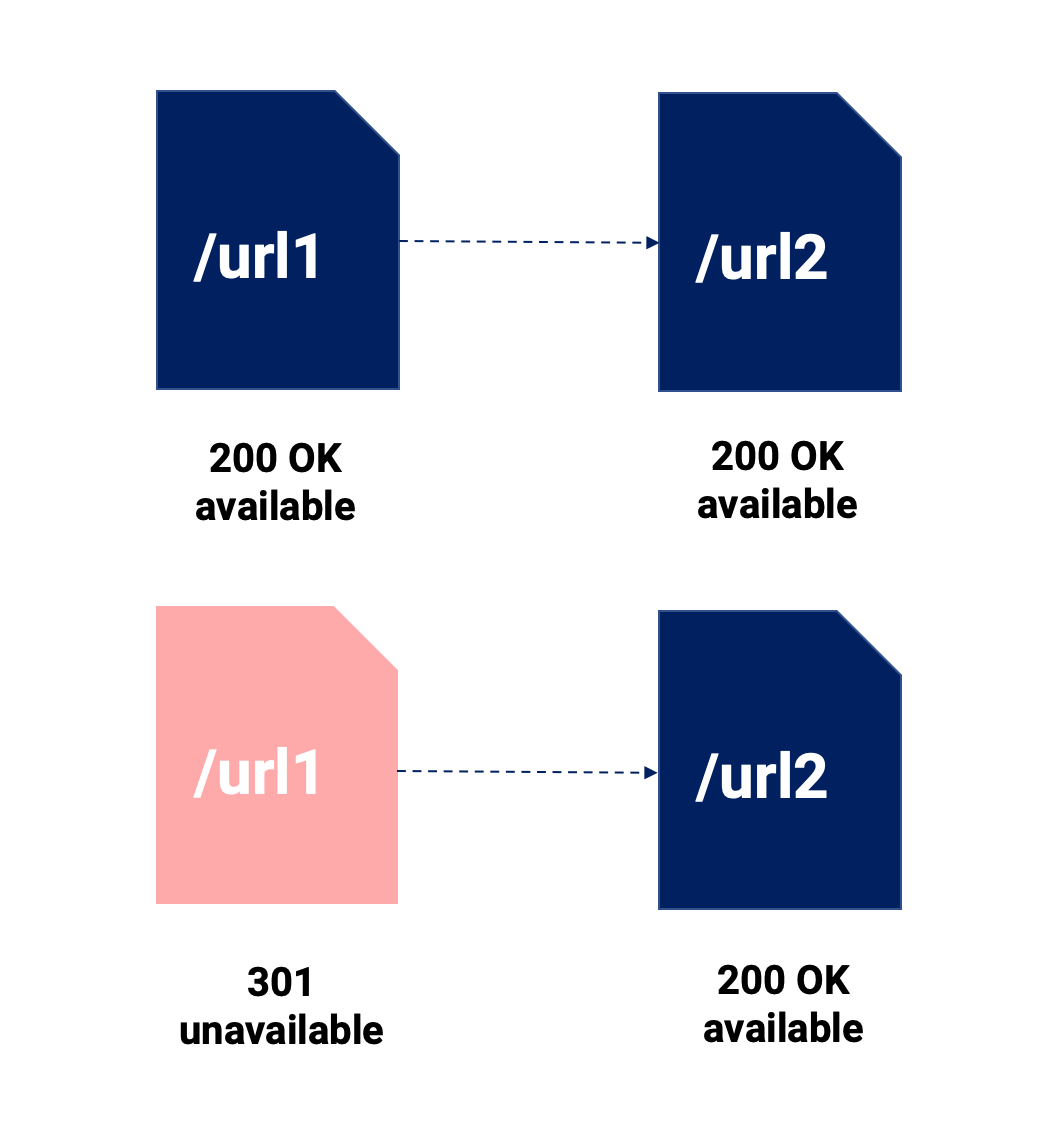
Using this visual summary, we want to highlight the following things:
- 301 redirect merges two pieces of content, which means the original content ceases to exist. It’s direct and 100% followed by Google (and users).
- The canonical, what it does is allow us to keep available various URLs for any channel, and if Google respects the directive, only the canonicalised URL will be indexed for the SEO channel.
- Both can possibly involve signal dilution, and it could have a more significant effect when we don’t use a 301 redirect, as canonicalised URLs can have internal and external links pointing to them, forcing us to divide our efforts between several URLs.
Implementation procedures
There are several ways to implement canonical tags:
HTML tag
The most common way to implement a canonical is by placing a link element with the attribute rel=”canonical” and the absolute path to the canonical version within the <head> of each URL. Here’s the correct syntax:
<link rel="canonical" href="https://www.sistrix.com/ask-sistrix/what-is-the-canonical-tag-and-how-to-use-it/" />HTTP header
This method is normally used on non-HMTL pages. For example: PDF, XML or TXT files.
This is the typical method being used, when we have both a PDF and matching HTML page. Through the canonical we can show Google that we want the HTML page to rank.
Nevertheless, given the variety of different cases there can be, we recommend this post, covering the more technical implementation through the .htaccess file.
<Files "seo-guide.pdf"> Header add Link "< http://www.sistrix.com/seo-guide/ >; rel=\"canonical\"" </Files>Other signals: sitemap and internal links
In this case we aren’t going to implement the canonical directive, but we’re stating, implicitly, that this URL (as opposed to its other versions) is the original one, and it has more weight and value.
Something as simple as adding URLs to a sitemap, or linking a URL from the website navigation already has a tacit and implicit importance, so we’re pretty much sending an SEO signal regarding the importance of this URL version for us. If we contradict ourselves or there are other ambiguous or inconclusive signals, we’ll be breaching the law of simplicity in SEO: do not make it more complicated for Google than it already is.
- With 2 duplicate URLs, using canonicals, the original URL will be included in the sitemap, the canonicalised won’t be.
- With 2 duplicate URLs, using canonicals, the original URL will be prominently linked, the canonicalised won’t be (although this isn’t always possible, and the canonicalised URL may have some link pointing to it).
Effect and SEO cases
The biggest impact the use of canonical can have, is that once it’s respected by Google, the URL to which the canonical tag is pointing becomes indexable, and the one issuing the canonical will step down and sacrifice itself, so that the more original content can get indexed.
On the other hand, if the URL issuing the canonical receives internal links somewhere within the navigation structure, Google will be able to crawl this page and invest time on it. This should seriously make us think about our combined use of Robots.txt (even “noindex”) and canonical. If we want to save our crawl budget, it’s possible we could be preventing Google from understanding where the duplicate and its canonical lie.
Speaking of more particular cases, we can specify a bit more:
- Passive parameters: are used as a precaution, in combination with Google Search Console’s parameter management. However, these parameters are used to tag campaigns (paid, email, social…).
- Active parameters: language, filters. The key here is to identify which ones have minimally original content we can position, besides knowing with certainty whether or not they respond to a search intent. Additional issues can be internal linking and waste of authority through these filters’ internal links.
- Pagination: the current scenario with regard to pagination is still a controversy in and of itself. Google removed the rel prev rel next guideline, and now the SEO world is debating whether we should use noindex, a canonical to the first page, infinite scroll, or dynamic technologies like AJAX to maintain functionality for the user without generating new pages/links, depending on the case. It’s not a trivial decision at all.
- Product pages with similar attributes (colour, size): Similar to what we said about filters, we need to identify when their content is not minimally original to rank, and we need to know whether they respond to a search intent. We should keep in mind the rule of “that, which is not searched for, should not be indexed”.
How to analyse or audit canonical tags
Now, we get down to the business of how to identify or audit canonical tags. We have methods to suit everyone’s preferences:
Explore the source code
Visit the page and right-click anywhere on the page to reveal the menu with the “View Page Source” option (Control + U if you’re using Windows; CMD + Alt + U if you’re using Mac).
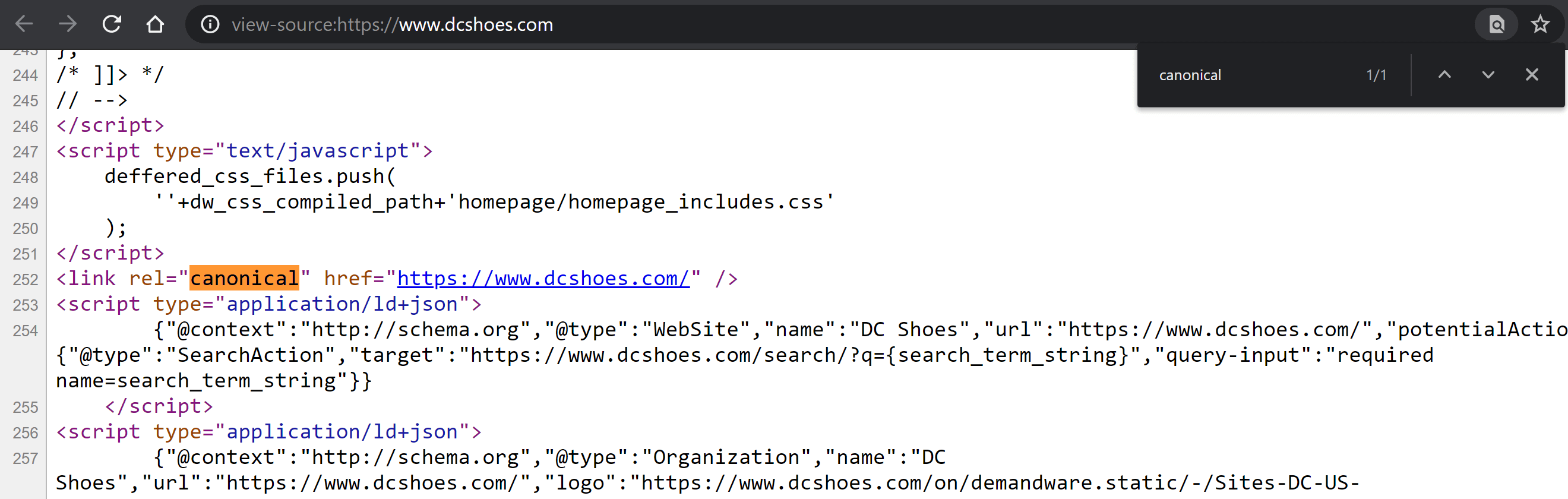
Once inside, hit Control + F on Windows or CMD + F on Mac to search within the code. Type “canonical”, so that the tag becomes highlighted in a different colour, if it’s there. Compare its content and determine whether this value has been correctly defined or not.
Chrome developer tools
Using Chrome we can open the website we want to analyse, right-click on the screen, and hit “Inspect”. This will open the developer tools, where we can search for the tag with Control + F or Cmd + F, just as we did in the previous point.
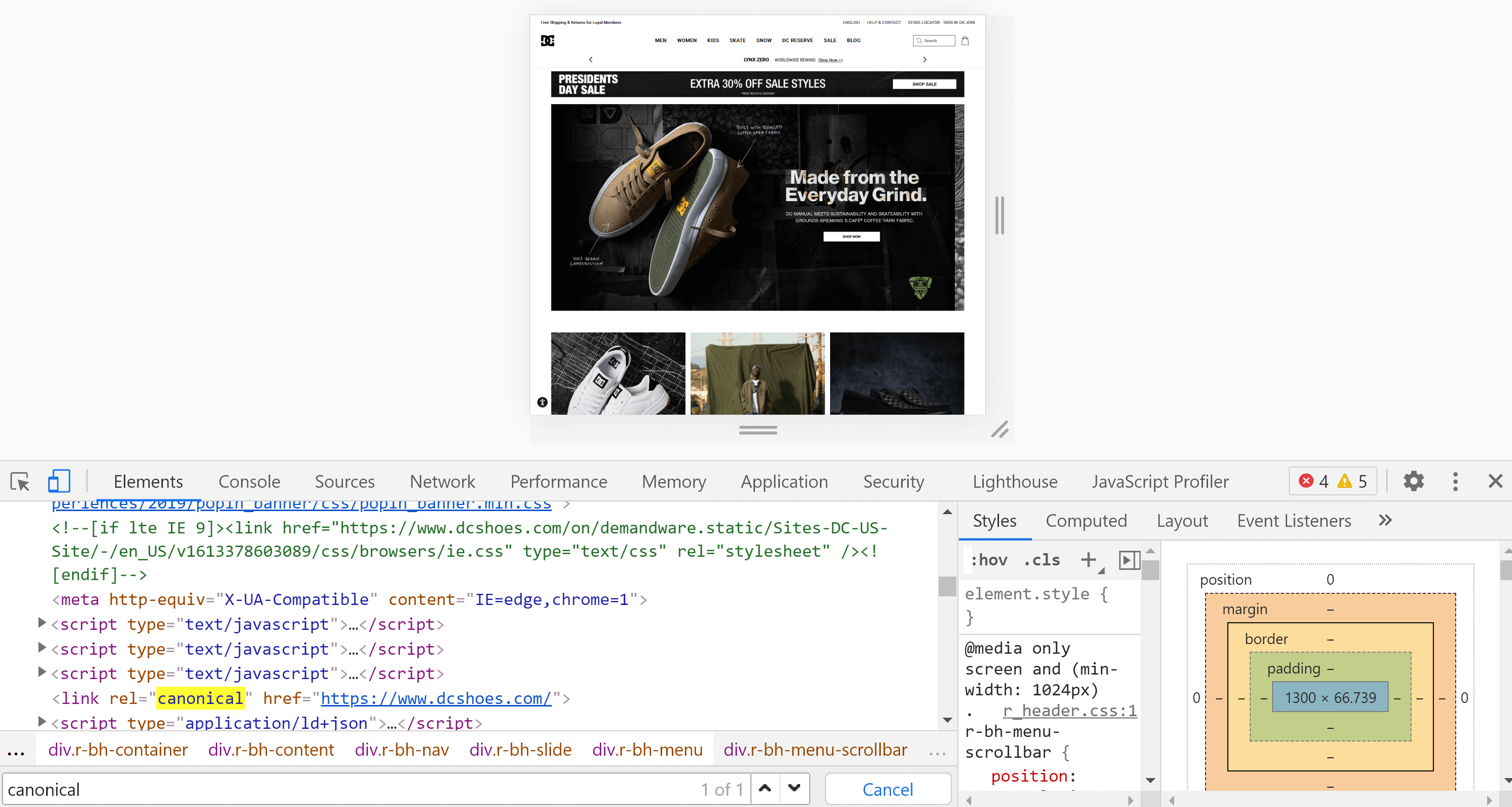
The main difference between the page source code and the inspector, is that the second one has already rendered the page and we see the content after this process (including the execution of JavaScript) is finished.
Alternatively, we can use the console, by going to the “Console” tab and entering the following command:
$$('link[rel="canonical"]')[0]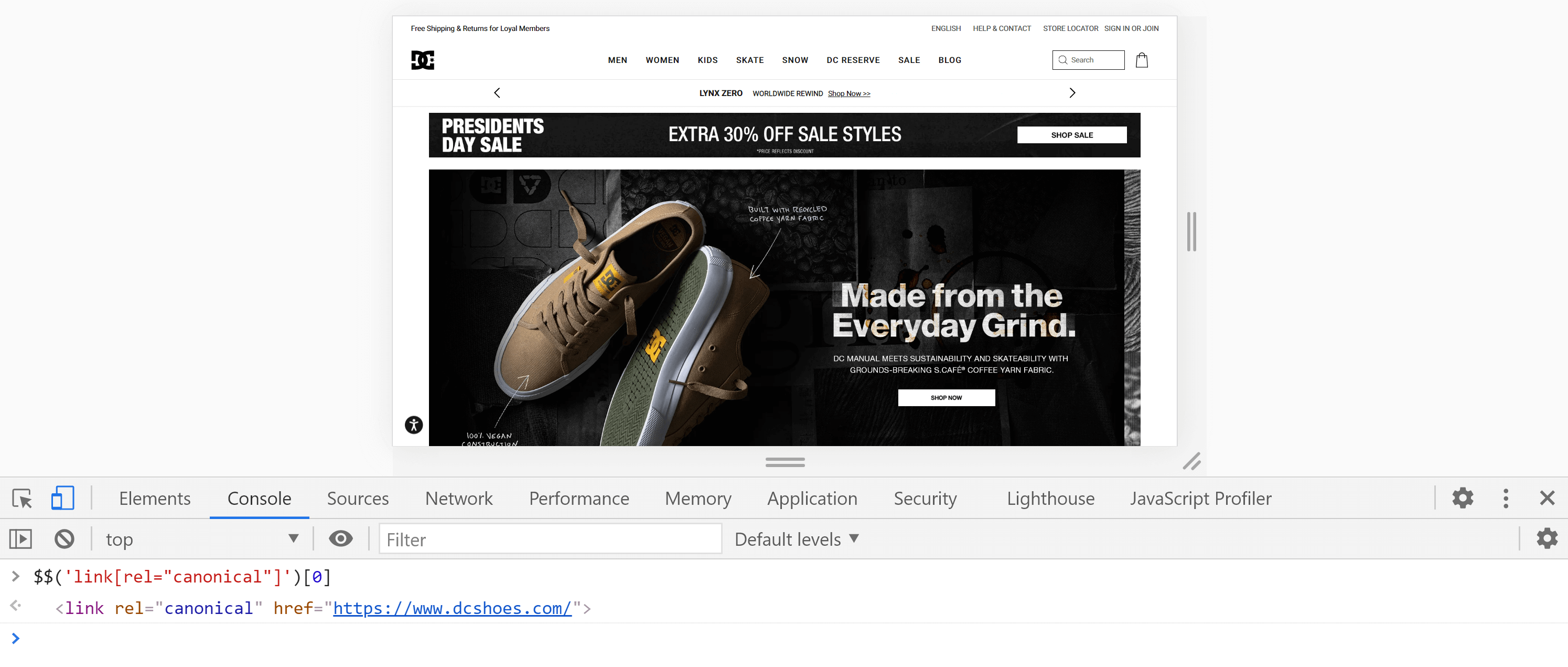
On Google Search Console
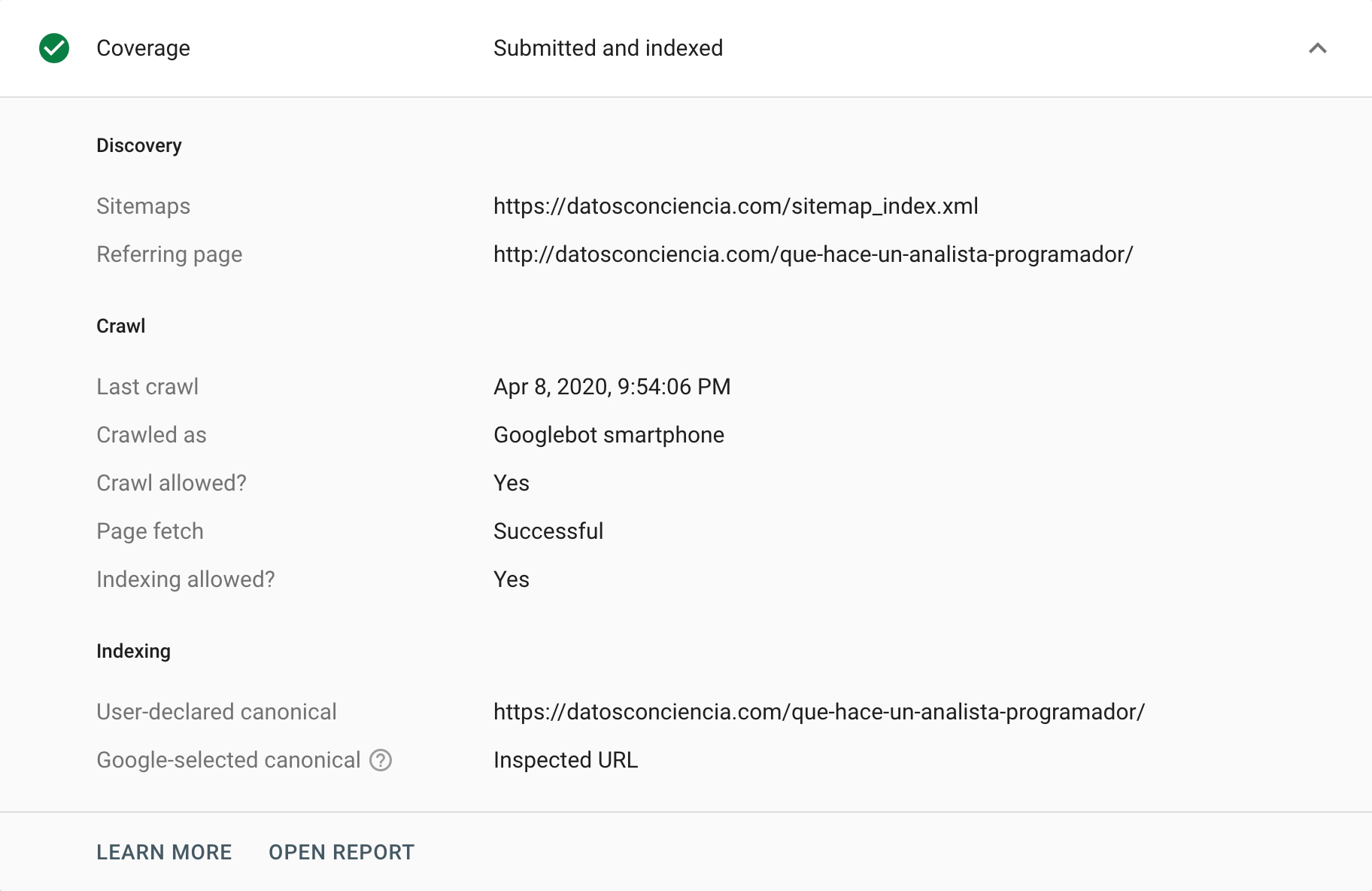
Google Search Console provides different ways to analyse or audit canonical tags. One way to do it, is to go to the “Coverage” report, where we can analyse any event responsible for the exclusion of certain URLs from its index. In this “Excluded” section, we can sometimes find situations related to canonical tags, both correct and incorrect cases (correctly and incorrectly interpreted). Undoubtedly, it’s the perfect way to start pulling at the thread that will help us identify problems.

On the other hand, we have the URL inspection tool, which can provide insights on canonical tags of individual URLs. We can request it to crawl them and return their status, especially if there’s a difference between our instruction and what Google chooses to interpret.
How to analyse canonical tags using the SISTRIX Toolbox Optimizer
There are several ways to analyse canonicals using the SISTIX Toolbox Optimizer.
Crawling and detection of warnings
Being a crawler, Optimizer will visit your website to identify opportunities for improvement, errors, and other aspects you will be informed about in an easy and visual manner, so you won’t have to waste your time processing data. Here’s an example related to canonical tags, which the Optimizer will notify you about (if you make a mistake):

URL explorer: analyse individual URLs
This feature is similar to Google Search Console’s URL inspection tool, which means you will be able to evaluate individual URLs that were crawled in your Optimizer project and see the information for that one specific URL..
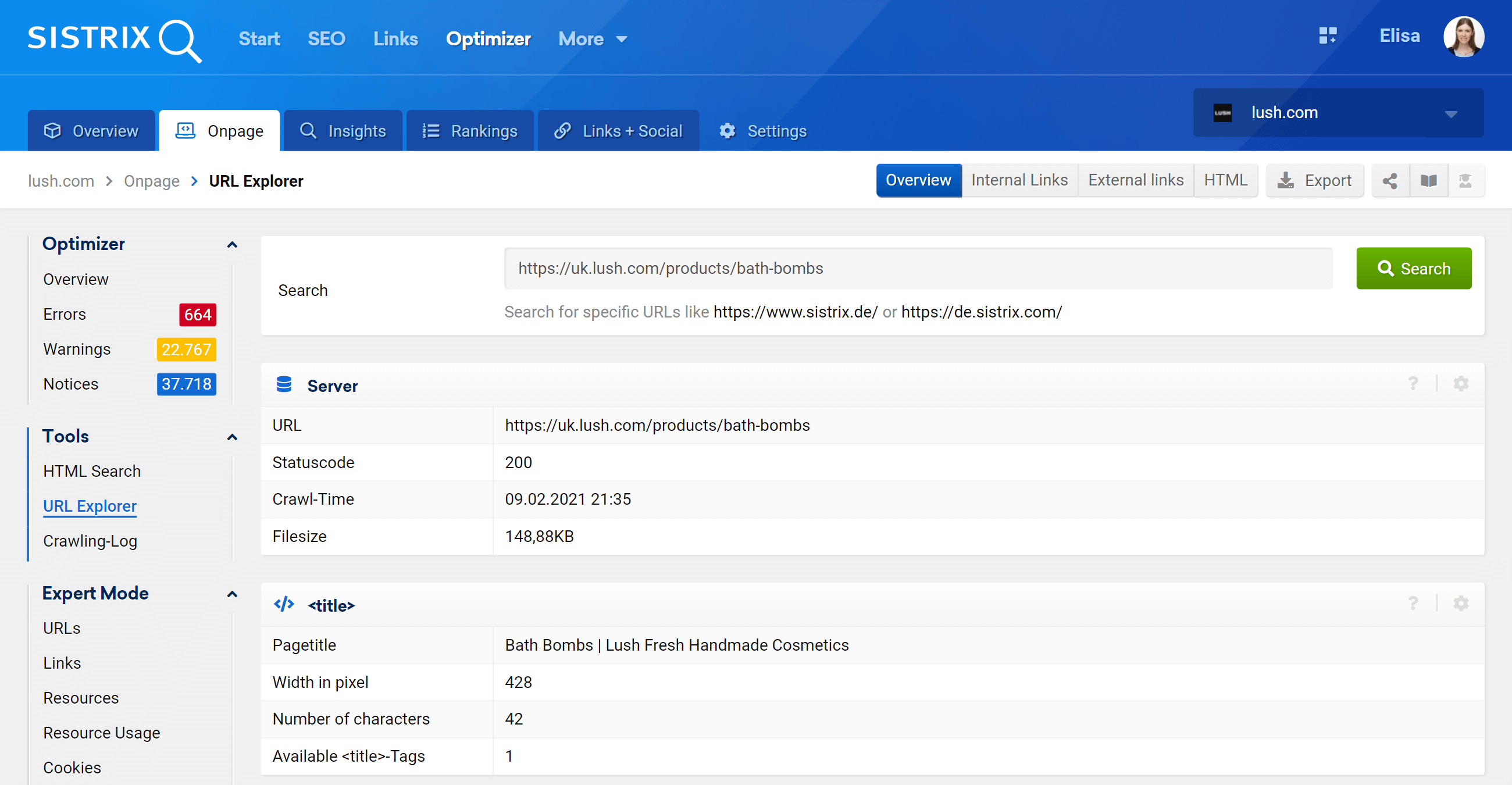
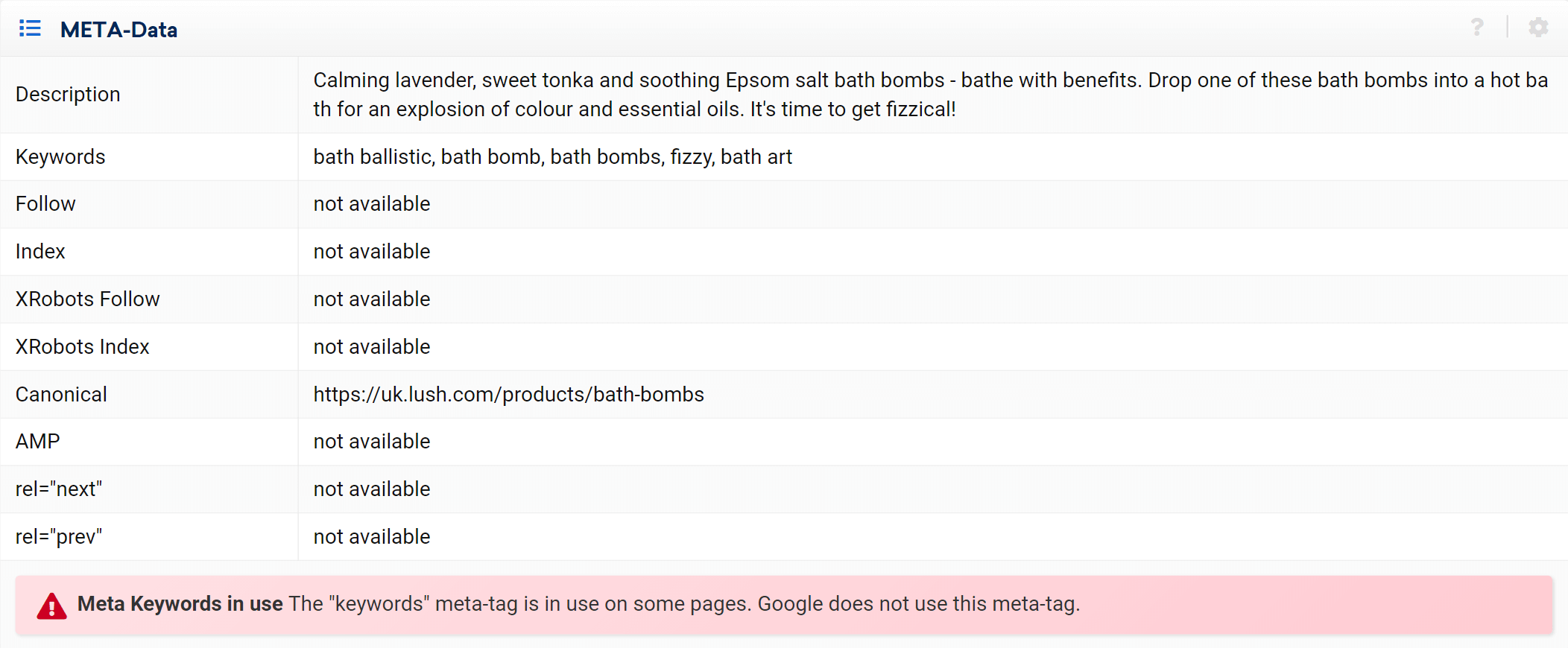
As you can see, we can analyse all on-page aspects concerning this URL, both inbound and outbound internal links, server information, SEO tags, and here is where you’ll find the canonical implementation as well, which is the subject at hand.
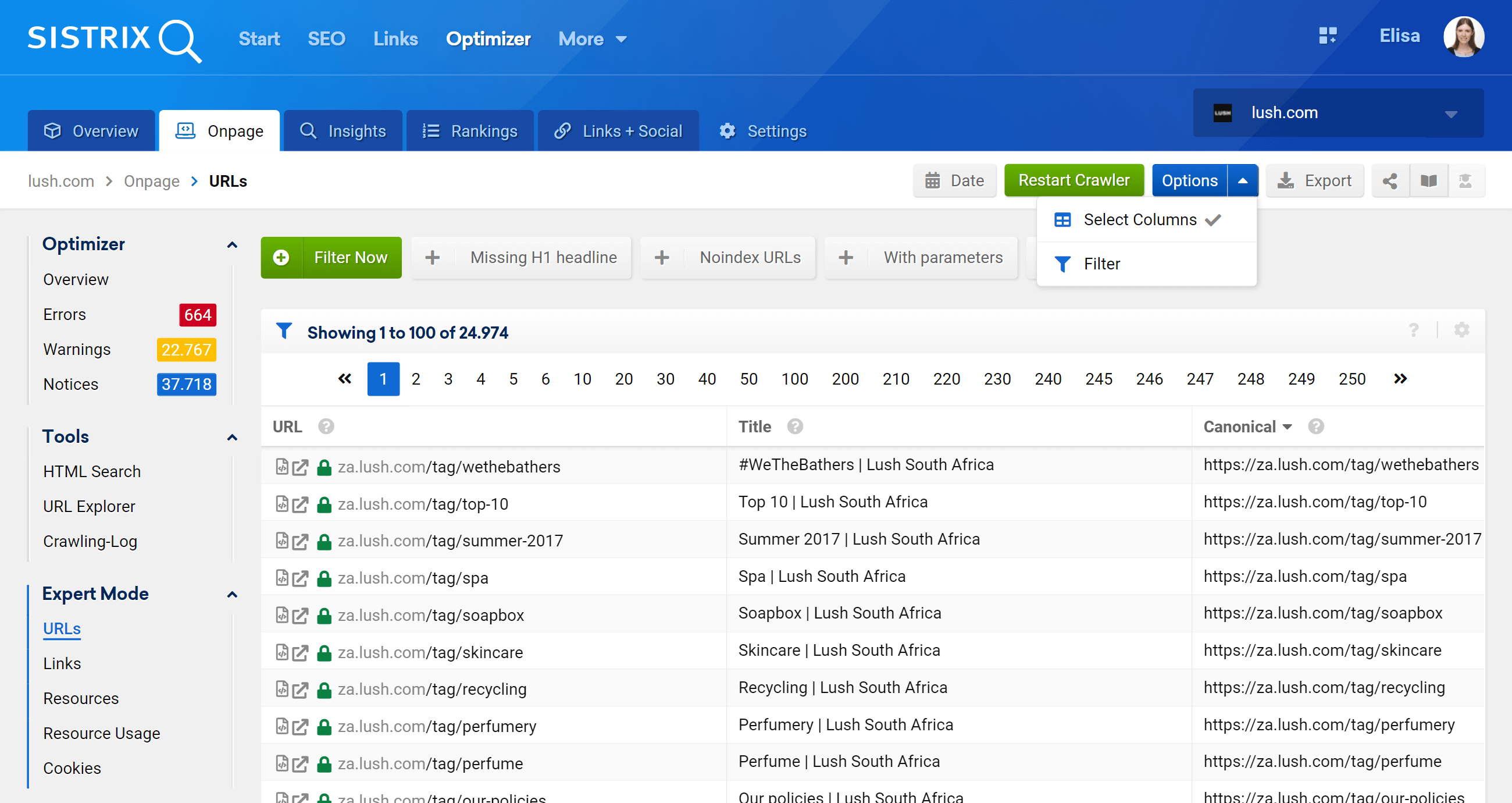
Expert mode
By going to the Expert Mode section we can access all of our project’s crawled URLs, and use multiple filters to refine our search. In the example below, I’ve included the URLs that contain /products/ in their URLs, but don’t belong to the /en_gb/ market.
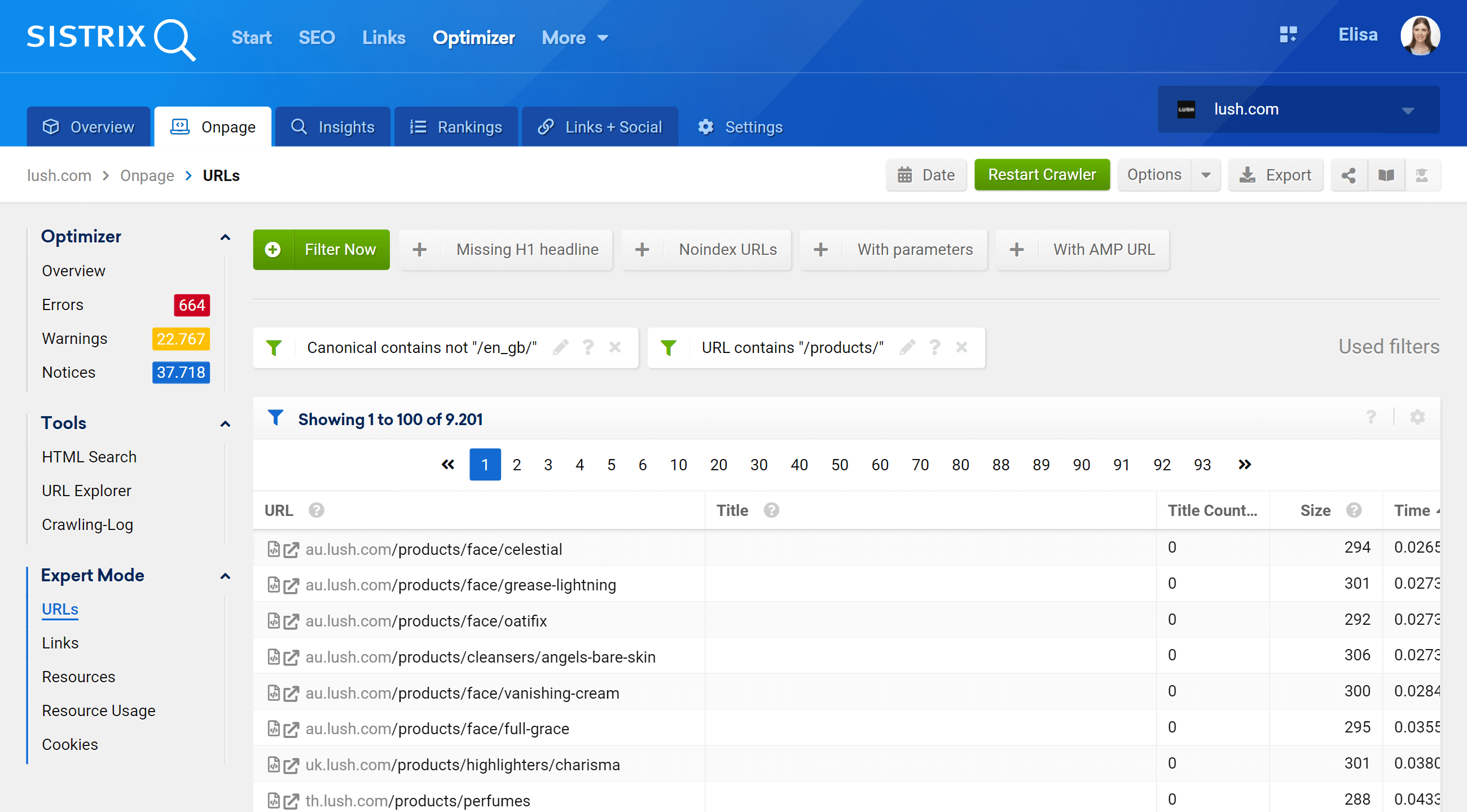
Moreover, we can also configure the table columns to display fields we are more interested in. In my example, I’ve chosen to show status codes, depth level, internal links, meta robots and canonical, but we could also add –by simply checking their box– the title, description, H1, size, type of content, etc.
Test SISTRIX for Free
- Free 14-day test account
- Non-binding. No termination necessary
- Personalised on-boarding with experts