
A HTTP status code, more commonly referred to simply as status code, is a three-digit code which is sent from the webserver to the client (a web browser or Google-Bot for example) as a page is requested. It is used to inform the client (user, Google etc) whether the HTTP-request has been processed successfully, or whether an error has occurred during the request for a URL.
- HTTP Status Codes: An Overview
- HTTP status codes and Google SEO
- Search Console error notification
- The best known HTTP status codes
- How to implement status codes
- A list of HTTP status codes
- 1xx Informational Response
- 2xx Success
- 3xx Redirection
- 4xx Client Errors
- 5xx Server Errors
- Unofficial HTTP status codes
- Other types of http status codes
- Status-code case studies
- Conclusion
Discover how SISTRIX can be used to improve your search marketing. 14 day free, no-commitment trial with all data and tools: Test SISTRIX for free
HTTP Status Codes: An Overview
Whenever you load a page, particularly if there’s an error, a HTTP status code will be displayed. The nature of the code depends on the type of response and where it originates from. It can be helpful for both the user and the developer.
Understanding error codes is useful for anyone who owns a website, as it will help improve your user experience and lower your bounce rate, especially if you fix any error status codes. It can also inform users of the reason behind an error, and direct them elsewhere instead.
HTTP status codes and Google SEO
In general, you should always evaluate the HTTP status codes during the course of a website’s OnPage optimisation and improve or repair them, if necessary. Incorrect status codes may lead to de-indexing and loss of search traffic.
Googles reference document on how its crawl and indexing process react to the above errors is available here
More information in crawling and indexing is available here.
Search Console error notification
Google search console will alert site administrators when errors are found and it summarises them in the coverage report.
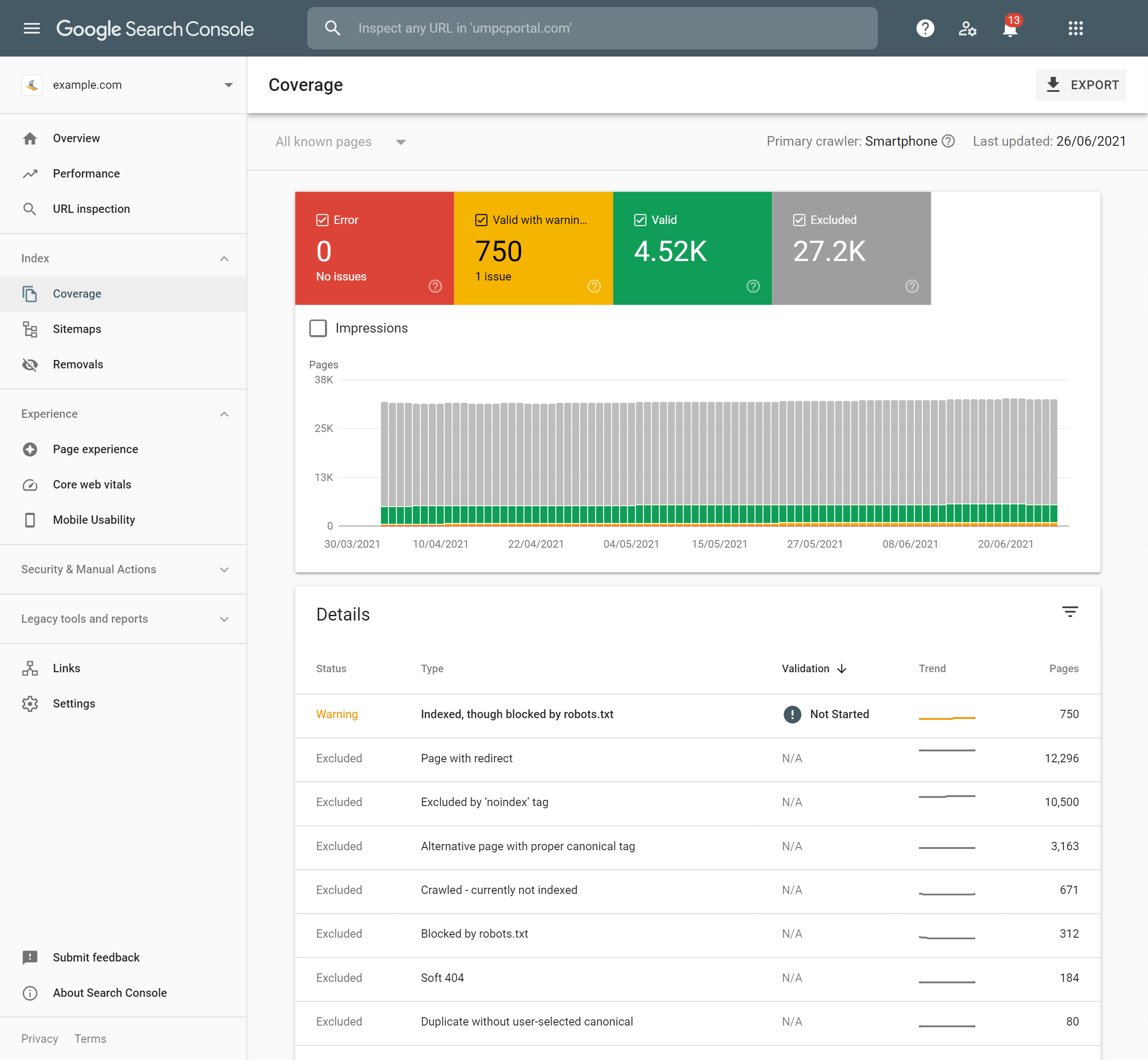
One important variation that Google highlights is the Soft 404 error, which is the label that Google gives to URLs that contain what looks like error text, or very little content, but send the 200 (success) code. Google regards this as bad practice. Soft 404 errors can be seen in the image above. 1
The best known HTTP status codes
The best known HTTP status codes are:
- 200 – OK
Meaning: The requested resource (URL) has been found on the server and can be transmitted to the client.
Meaning: The URL requested by the client has changed. The webserver automatically redirects the client to the new URL. This is extremely common on mature web builds. If you want to learn more about redirects, we have prepared a set of articles. Learn how to create a 301 redirect, including the common non-www to www redirect. There are some limitations and problems related to chaining redirects that you should be aware of and you can learn about the important differences between the 301 (permanent) and the 302 and 307 (temporary) redirect types.
Meaning: The resource (URL) requested by the client could not be found on the webserver.
Meaning: The webserver is temporarily not available. This could be due to maintenance or overload, for example.
How to implement status codes
Status codes are generated by the webserver in different ways. It’s common for it to be done using the .htaccess file or via PHP code, which is often the way that a WordPress plugin will do it.
A list of HTTP status codes
More detailed information available in our library is available via the links.
1xx Informational Response
- 100 continue
- 101 switching protocols
- 102 processing
- 103 early hints
The 1xx category is a response that indicates the request was received and understood. This category is somewhat of an anomaly in that this section of status codes is rarely used.
2xx Success
- 200 OK
- 201 created
- 202 accepted
- 203 non-authoritative information
- 204 no content
- 205 reset content
- 206 partial content
- 207 multi-status
- 208 already reported
- 226 IM used
Any code within the 2xx category means the request was successful. Both 200 and 201 are similar, but 201 gives the browser a little more information as it means that something was created, whereas 200 literally means ‘OK’. 200 and 201 are treated the same by the Google crawling and indexing process.
204 is a common code within this category and means the server processed the request but it did not return any content. However, this is deliberate as not returning any content was the intention, and so is still considered a successful return. For Google’s crawling and indexing process, a 204 may be shown as a soft-404 in the Google Search Console.
3xx Redirection
- 300 multiple choices
- 301 moved permanently – Google takes this as a strong signal that the destination is canonical (the master, in terms of indexing.)
- 302 found – Google takes this as a weak signal that the destination is canonical (the master, in terms of indexing.)
- 303 see other – Google takes this as a weak signal that the destination is canonical (the master, in terms of indexing.)
- 304 not modified – Has no effect on indexing but the URL maybe re-calculated for ranking signals
- 305 use proxy
- 306 switch proxy
- 307 temporary redirect – Google treats this as a 302
- 308 permanent redirect – Google treats this as a 301
Websites are complex and the needs of your users or indeed your business model as a whole are ever-changing. Sometimes, a page may have moved or merged with another page, and so the original URL will no longer take the user to where they want to be. Or, perhaps your domain name has changed, and you don’t want to lose customers who still visit the old URL, so you instruct the page to redirect users over to your new website instead. Such examples are where the 3xx category of status codes would be used.
304 is a common status code in this category. It’s not so much about redirecting the user from one URL to another, rather it deals with caching information. If nothing has changed on the page, 304 will inform the user, without having to increase the amount of data which would slow down the browser. If any of the information had changed, then the status code would switch to the corresponding 2xx response.
4xx Client Errors
- 400 bad request
- 401 unauthorized
- 402 payment required
- 403 forbidden – Commonly used when a page is blocked through a security process
- 404 not found – Commonly seen when URLs are not found on a web server. Google may start to deindex these URLs quickly.
- 405 method not allowed
- 406 not acceptable
- 407 proxy authentication required
- 408 request timeout
- 409 conflict
- 410 gone – Used when pages have been removed on purpose.
- 411 length required
- 412 precondition failed
- 413 payload too large
- 414 URI too long
- 415 unsupported media type
- 416 range not satisfiable
- 417 expectation failed
- 418 I’m a teapot
- 421 misdirected request
- 422 unprocessable entity
- 423 locked
- 424 failed dependency
- 425 too early
- 426 upgrade required
- 428 precondition required
- 429 too many requests
- 431 request header fields too large
- 451 unavailable for legal reasons
For the important crawling and indexing process from Google there are some points to now. All 4xx errors send messages to the indexing pipeline that the content does not exist and the URL will be removed from the index. 401 and 403 errors should not be used to try and affect the crawl rate. The 429 signal is treated as a server error. (5xx codes. See below.)
The 4xx category is the most recognisable of all the HTTP status codes. Essentially, it is communicating that there is an error on the client’s side. From a webmaster’s perspective, 4xx codes are the ones to look out for, because they will generate a poor user experience if the user cannot complete the action properly.
So for example, 401 unauthorized means you don’t have access to the page, which could happen if you don’t have permission to view its contents, or if you’re not logged in. 403 forbidden is similar in that you may be trying to view a page that requires admin permission to do so.
Both 401 and 403 HTTP status codes act as a virtual gatekeeper protecting the website from suspicious activity. However, 401 is saying it doesn’t recognise the user at all, whereas 403 does recognise the user, but knows the user doesn’t have the right credentials to view the content.
404 is arguably the most recognisable of all the HTTP status codes. It means that the page you are trying to access does not exist. As an example, if you manually typed in a URL and added a word to try and locate a page, but that page didn’t exist (at least under that particular URL) a 404 status code would be generated.
A notable mention for the 4xx category is the 418 I’m a teapot code. It was generated as an April Fool’s joke, to mean ‘the server refuses to brew coffee because it is permanently a teapot’. While this status code is never actually used, Google created a page dedicated to it.
5xx Server Errors
- 500 internal server error
- 501 not implemented
- 502 bad gateway
- 503 service unavailable
- 504 gateway timeout
- 505 HTTP version not supported
- 506 variant also negotiates
- 507 insufficient storage
- 508 loop detected
- 510 not extended
- 511 network authentication required
5xx errors relate to errors within the server, namely that it’s unable to load because a connection cannot be established. Usually, the error is within the hosting platform itself and is unexpected.
For example, 500 internal server error could be caused by a bug within the code, meaning the page doesn’t load as intended or at all. This kind of status code helps identify the location of the problem, namely that it is something within the server and not a user error.
For Google, all 5xx errors, along with the 429 error, cause Google to temporarily slow down the crawl rate for the site and the decrease is proportional to the number of errors found. Persistent errors will send signals to the indexing pipeline that the URL should be removed from the index.
Google states that indexed URLs that are unreachable, will be removed from the index within days.
Unofficial HTTP status codes
Other HTTP status codes run on a scale of 103 to 598. These codes are not specified by any standard, and therefore don’t fit into a particular category.
A notable example is the 522 connection timed out error by Cloudflare. As Cloudflare acts as a middleman between the server and the user, if it has an error it’s not going to be able to pull up the result and so the site effectively goes down until it’s resolved.
Other types of http status codes
Status codes are just one type of information that is returned by a webserver in the HTTP protocol. Other information includes the x-robots codes and the http-content-type.
Status-code case studies
- For Spaghetti’s sake, don’t forget your redirects
- The Price of Changing the Domain Name
- Buying links that others earned… Why not?
- If you want to confuse Google use a 302 redirect
Conclusion
HTTP status codes essentially provide information on whether a page loaded correctly or not, and if not the reason why this was the case. It’s a method of webserver communication not only with users, but webmasters too.
While all HTTP status codes have a valid purpose, the 4xx codes are the ones you and your users are more likely to encounter. Sometimes the error messages can be helpful, especially as the user may be required to login to continue. However, it’s worth remembering that any disruption to the user experience should be avoided where possible. This means, testing your site regularly especially for errors such as broken links.
HTTP status codes can also be used to better communicate between different pages on your website. It’s highly recommended to regularly check the status of your website’s performance on tools such as Google Search Console, so you can identify any issues.
Test SISTRIX for Free
- Free 14-day test account
- Non-binding. No termination necessary
- Personalised on-boarding with experts