
AI search engines are more than just a technical update to classic search. With Google’s new AI mode, which integrates generative answers directly into regular search, it is now clear that the way information is found and presented is changing fundamentally. Users are increasingly receiving complete answers without having to visit a website.
- How AI search engines work
- Crawling and web access
- Language processing using LLMs
- Generative answers - what this means for websites and SEO
- Analyse AI search engines with SISTRIX
- Create a monitoring project
- Prompts in detail
- Keeping an eye on the competition
- AI search engines vs. AI chatbots with web access
- AI search engines
- AI chatbots with web search
- AI chatbots without web search
- Outlook: Will AI search replace traditional search?
- Sources & Studies
The classic web search, as we have known it for over two decades, is based on a simple principle: the user enters a search query and the search engine returns a list of links. These so-called ‘blue links’ refer to websites where the user will hopefully find the information they are looking for. This model is based on web crawlers that systematically capture and index the internet, making it searchable.
The integration of artificial intelligence into search engines is fundamentally changing this paradigm. In AI search engines, the answer to a search query is no longer compiled exclusively from a list of potentially relevant websites. Instead, the system processes the information in the background and uses it to create a new, coherent answer. Users no longer see only references to content, but a direct formulation that brings together various sources. This change affects not only the way information is processed, but also the expectations of search engines as a whole. For SEO, this means new opportunities, but also new challenges: visibility is no longer created solely through rankings, but also by whether content appears as a source in generative responses.
How AI search engines work
To understand how AI search engines work, you need to differentiate between two systems: web access (crawling, indexing) and language processing (generating the answer).
Crawling and web access
A classic web crawler, such as those used by Google, Bing or Perplexity, systematically searches the internet. It follows links from one page to the next, temporarily stores content and files it in an index. This index forms the foundation on which search queries are later processed. The content is recorded in a technically structured manner – as HTML, text, images, metadata – but is not understood semantically.
AI search engines need up-to-date information to generate relevant answers. Some systems operate their own crawlers for this purpose, but this is very costly. Perplexity AI, for example, has now established its own crawler system, which it uses to build its own index. Others, such as You.com, combine crawling with API access to existing search engines. Hybrid systems – such as ChatGPT with a browsing function – do not perform their own indexing. Instead, the model uses existing search engines, such as Google or Bing, to retrieve specific websites at the moment of the query. The selection of these pages is based on the ranking of the underlying search engine.
The language model then takes over in the next step: it processes the content, evaluates the context and formulates a new response. We explain exactly how this language processing works and what consequences it has for SEO later in this article.
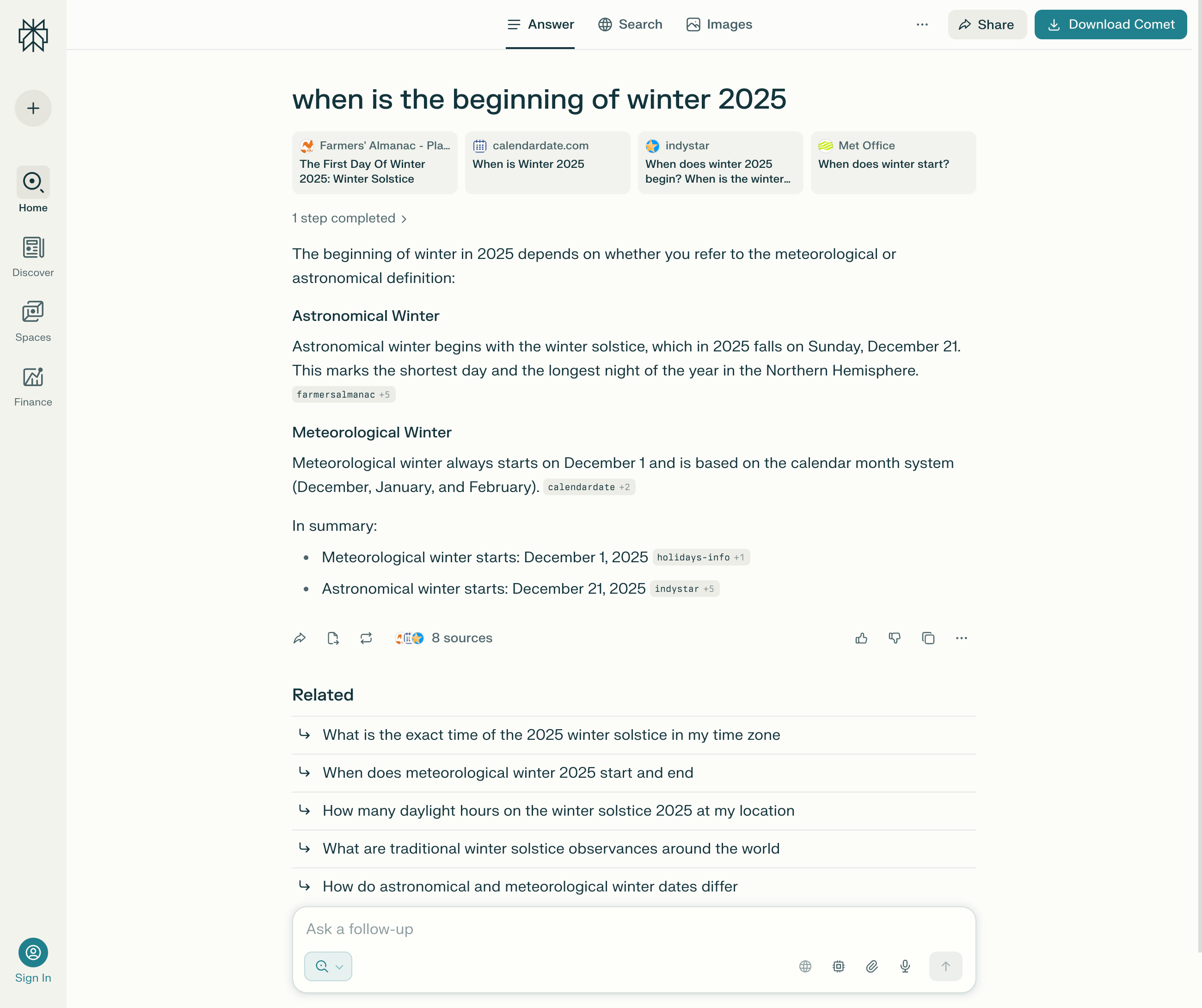
Language processing using LLMs
Large language models (LLMs) such as GPT, Claude, and Gemini are neural networks that have been trained with huge amounts of text data. They can recognise language patterns, interpret meanings, and generate text. In an AI search engine, they take on the role of a language comprehension and response generator: they analyse the search query in natural language, process relevant content from the index or web access, and use it to formulate a new, coherent response.
In doing so, they evaluate the context, collate information from multiple sources and can even recognise contradictions or redundancies. The key difference to classic search is that the output is not a list of links, but a (supposedly) conclusive answer. This means that clicking on the source of the information is no longer necessary. This is extremely convenient for users, but it also brings with it problems.
“While Google continues to have a structural advantage with its huge web index and integrated systems, AI-based systems such as ChatGPT first have to access external data sources and scrape content in order to provide answers.” (Johannes Beus in the German-language OMT podcast)
Generative answers – what this means for websites and SEO
With the shift from link-based results to generated answers, the rules of the game for visibility on the web are changing. The central problem is that if the answer already appears on the search results page, there is no need to click on the actual website. This so-called ‘zero-click’ phenomenon leads to a decline in organic traffic, even if the content of your own page is correctly cited or used.
Since the introduction of AI Overviews, many sites have seen significant losses in their traffic from Google, depending on the topic. However, the losses particularly affect generic topics such as searches for simple facts, figures or names. AI search engines can already answer such search queries conclusively without any problems.
For SEO, this means a strategic expansion: a good ranking on Google remains important, but is no longer sufficient. Companies must prepare their content in such a way that it is not only visible, but also used as a quotable basis for AI-generated answers. The benefit of such a citation lies less in the immediate click and more in the perception as a trustworthy source.
Those who are regularly mentioned in AI responses relating to their area of expertise strengthen their brand, build authority and can thus secure long-term reach and trust, even when direct traffic declines.
New SEO principles coming to the fore:
- Trustworthiness: Content must be created in such a way that it is considered credible, reliable and quotable by an AI system. The criteria summarised by Google under E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) also apply to other systems.
- Structured content: Clear, concise answers, FAQ blocks and structured data (Schema.org) help AI systems to correctly capture and extract content.
- Question-oriented content: Preparing content in such a way that it directly answers specific user questions increases the chance of appearing in generated AI responses.
- Branding and recognisability: In an environment where content is processed anonymously, it becomes all the more important to establish a recognisable, trustworthy brand.
To compensate for the decline in clicks, more and more relevant content must be created that not only provides general answers that language models have long since internalised, but also offers real added value: language models cannot offer new information, human evaluations and unique perspectives. Those who simply summarise already known general knowledge and publish it as text will no longer have a chance of reaching a wide audience via search engines in the future. Language models can already do this better today.
Analyse AI search engines with SISTRIX
Um diese neuen Herausforderungen messbar zu machen, braucht es verlässliche Daten. Genau hier setzt die SISTRIX AI-Chatbot-Beta an: Ein individuelles Projekt zeigt, in welchen Antworten von ChatGPT, Perplexity oder den Google AI Overviews eine Marke auftaucht, welche Links gesetzt werden und wie sich die Sichtbarkeit im Zeitverlauf entwickelt. Damit wird nachvollziehbar, welche Inhalte tatsächlich in generierten Antworten genutzt werden und wie sich die eigene Position im Wettbewerbsumfeld verändert.
Create a monitoring project
When you create a project and enter a brand, SISTRIX automatically creates a competitor environment and can generate the appropriate prompts. This gives you a standardised starting-point for regularly monitoring your visibility in AI responses.
In addition, SISTRIX immediately calculates a separate Visibility Index for your brand – similar to the index already available for Google and Amazon. This index is based on current data and provides the ideal metric for measuring success in the new environment of AI search engines.
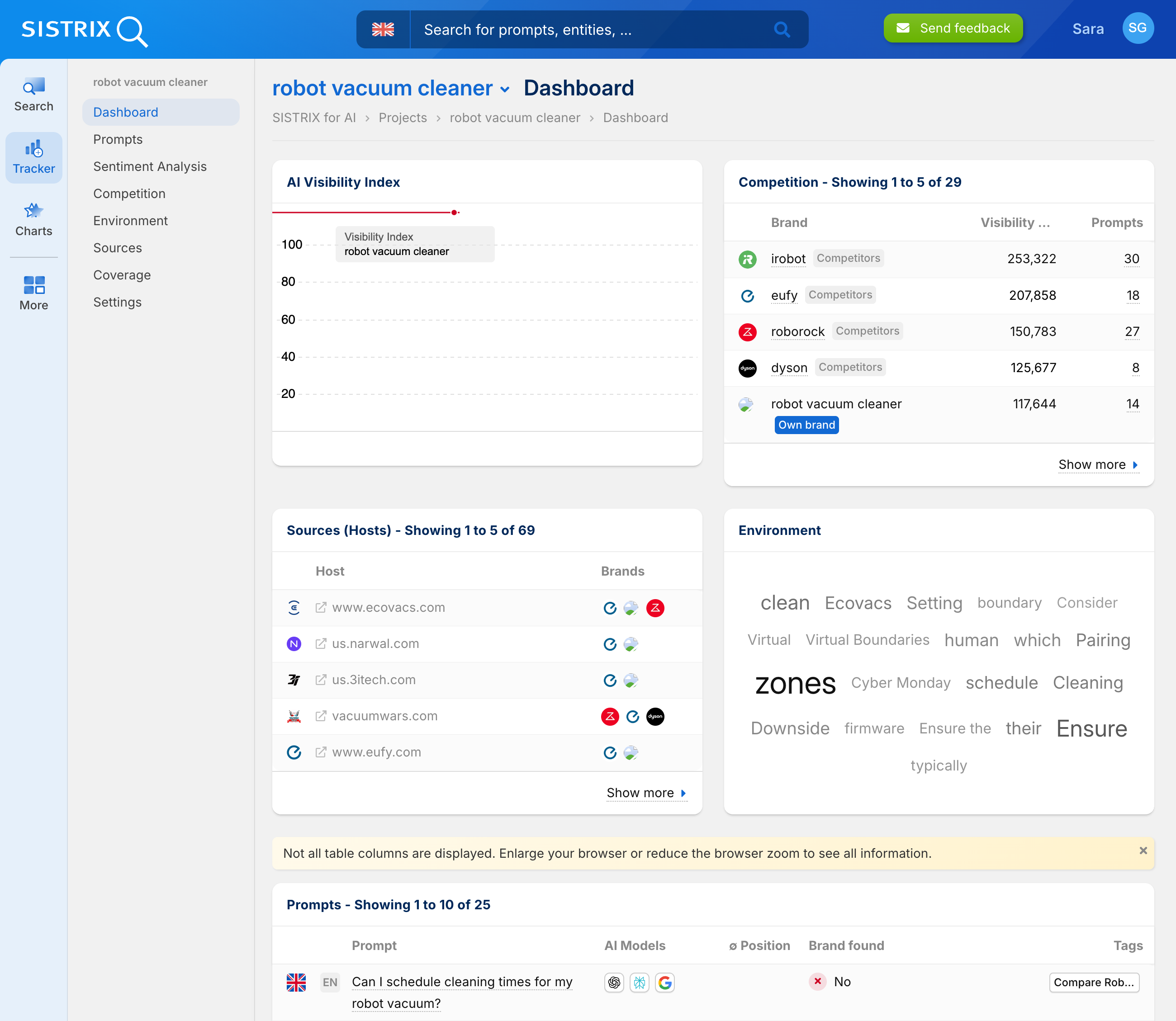
At the same time, further components are prepared:
- Competitors – shows which brands are also visible in your environment
- Sources – lists the content from which the AI systems’ responses originate
- Entity environment – analyses related terms, brands and topics
- Prompts – documents the questions and answers used in detail
This gives you a complete picture of your visibility in AI search engines right after the project starts – with an overview of key figures, sources and competitors.
Prompts in detail
All prompts created can be analysed in detail. The overview immediately shows you which prompts have been recorded, in which AI systems they are being tested, and whether your brand is mentioned in them. Clicking on an individual prompt opens the detailed view: at the top, a timeline is displayed showing which brands were mentioned in which system and how often. This allows you to track the development of visibility over days or weeks.
Below, you will find the specific responses from the systems. These are not only stored for the current time, but also archived retroactively. This makes it possible to compare responses, highlight changes and thus document the success of individual measures. At the same time, it highlights when your brand or competitors are mentioned and linked. This allows you to see exactly what content is included in the responses and how visibility shifts over time.
Keeping an eye on the competition
The competitor analysis automatically shows which brands are mentioned alongside your own in AI responses. The visibility index directly compares the most important competitors with your own brand. This allows you to see at a glance how visibility is distributed in the market. In addition, a complete list of all identified competitors is available including visibility index, mentions in the defined prompts and number of different prompts. This provides a detailed market overview that shows which brands are particularly prominent and where action is needed.
VIDEO
Use SISTRIX to analyse how visible your brand really is in AI search engines. With the AI/Chatbot Beta, you can see which AI responses mention your brand, which sources are used for this, and how visibility changes over time. In addition, the competitor comparison shows you where your competitors stand and which topics they cover. This gives you not only figures, but also a complete picture of your position in the new search environment. Try SISTRIX free for 14 days and analyse the visibility of your website.
AI search engines vs. AI chatbots with web access
AI search engines
From the outset, these systems were developed to replace or enhance traditional web search with AI. They typically combine their own web crawler, an index and a language model that generates a response from the content found.
Perplexity AI is one of the best-known representatives of this category. The service uses its own crawlers to search the internet, analyse the content and store it in its own index. When a search query is entered, relevant sources are identified, the content is analysed and transformed into a complete answer by a language model, supplemented by transparent source references. Perplexity does not see itself as a search engine in the traditional sense, but rather as an answer engine for more in-depth information needs. However, Perplexity’s search results are strikingly similar to those of Google, so it can be assumed that Perplexity and other AI search engines also access Google search results to find suitable answers.
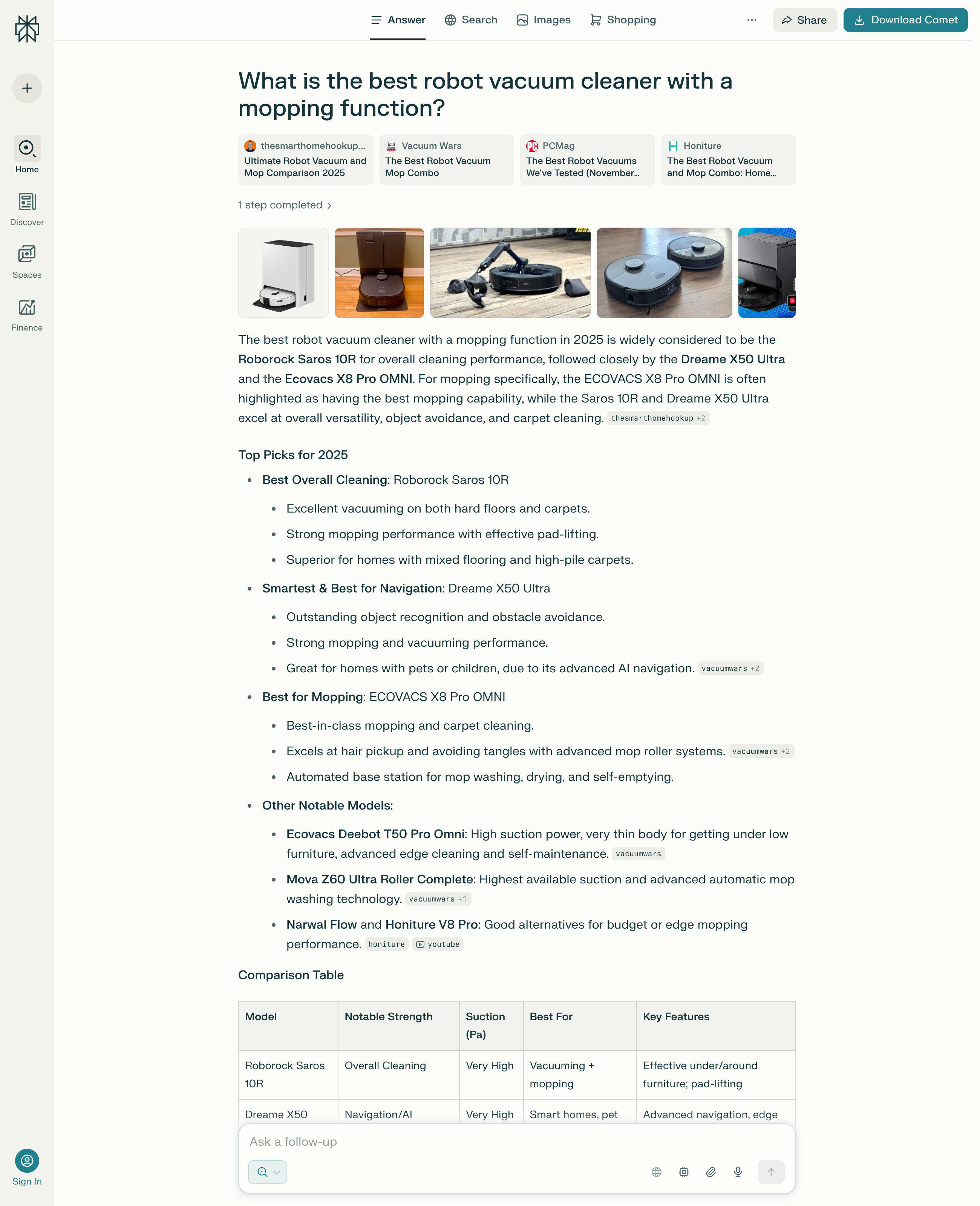
Google AI Overviews (formerly Search Generative Experience) is Google’s approach to combining traditional search with generative AI. It is based on the Google index, combined with AI-generated summaries that are displayed above the normal search results. The answers appear as accompanying commentary to the hit list, not as a replacement, but as contextualisation. However, they often contain such extensive information that clicking on the search results is no longer necessary for many questions. One study shows an average loss of 50% clicks in Google since the introduction of AI Overviews. Google AI Mode could reduce click-through rates even further.
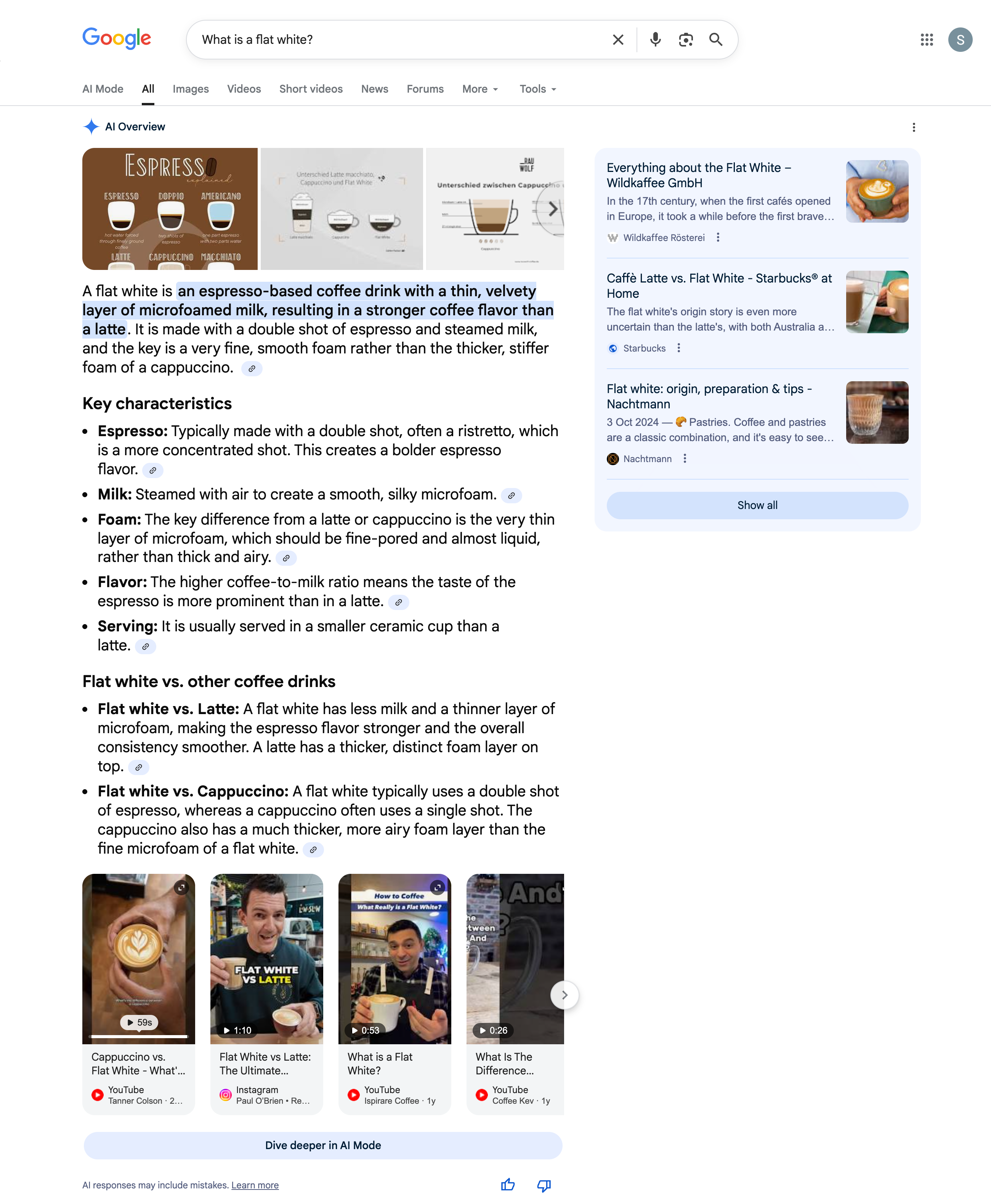
You.com takes a modular approach. Users can choose whether they want to see classic links, AI summaries, or both. Here, too, a proprietary crawler and language model are used. You.com attempts to personalise the search more by customising results and allowing users to control the layout of their results themselves.
What all three systems have in common is that they are not merely ‘talking interfaces,’ but operate their own technical infrastructure for capturing and evaluating web content. They are thus more than just front ends for existing search engines.
AI chatbots with web search
These systems were originally designed as language models for general conversations, but were later given functions for real-time information retrieval via web access. They do not usually have their own crawlers or a complete search index, but use existing search services such as Google or Bing.
ChatGPT with browsing function can search the web when the browsing function is activated. The model sends a search query to an existing search engine – such as Bing or Google – reads a selection of the pages displayed and processes their content to answer the user’s original question. This does not involve permanent crawling, but rather temporary access for the duration of the conversation. Sources are usually cited, but the search logic of the underlying service (e.g. Bing) remains in the background.
BILD
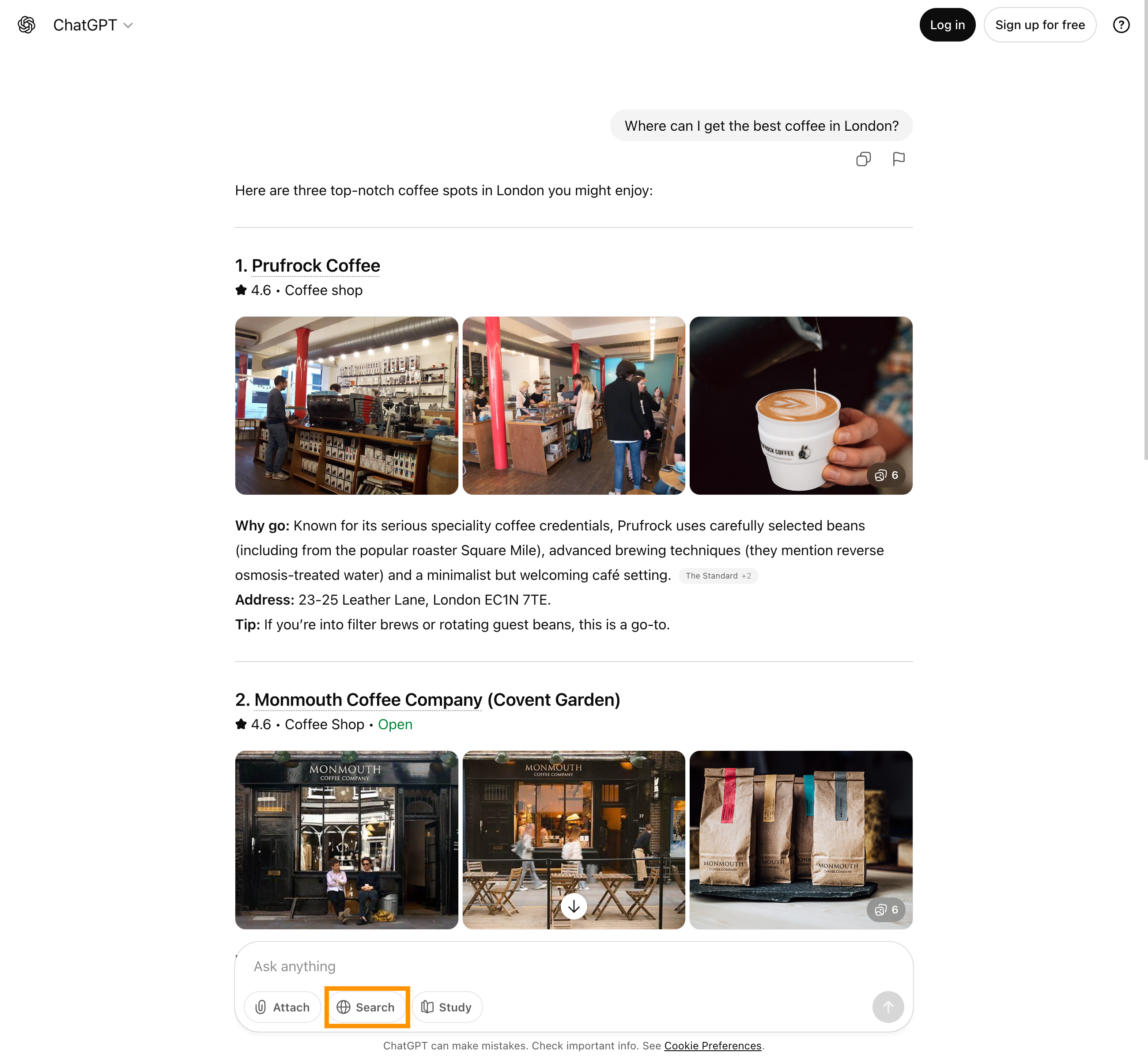
Microsoft Copilot (formerly Bing Chat) is deeply integrated into the Bing ecosystem. Language processing is performed using a GPT model that can access the Bing search index in real time. This enables Copilot to analyse search queries, retrieve relevant content and incorporate it directly into a generated response. Microsoft has technical control over the search and language model, which allows for deep integration into Edge, Windows and Office products, for example.

Google Gemini has web access in certain modes, such as ‘Gemini in Chrome’ or live mode in the web app. The model does not access its own search index, but uses selected website content in real time. However, access is restricted and depends on account type, language and region, meaning that, unlike Perplexity or Bing Copilot, Gemini does not yet constitute a fully-fledged search system with its own index. The strength of Google Gemini is that the model can also process very large amounts of text, making it particularly suitable for professional research in extensive text documents or studies.
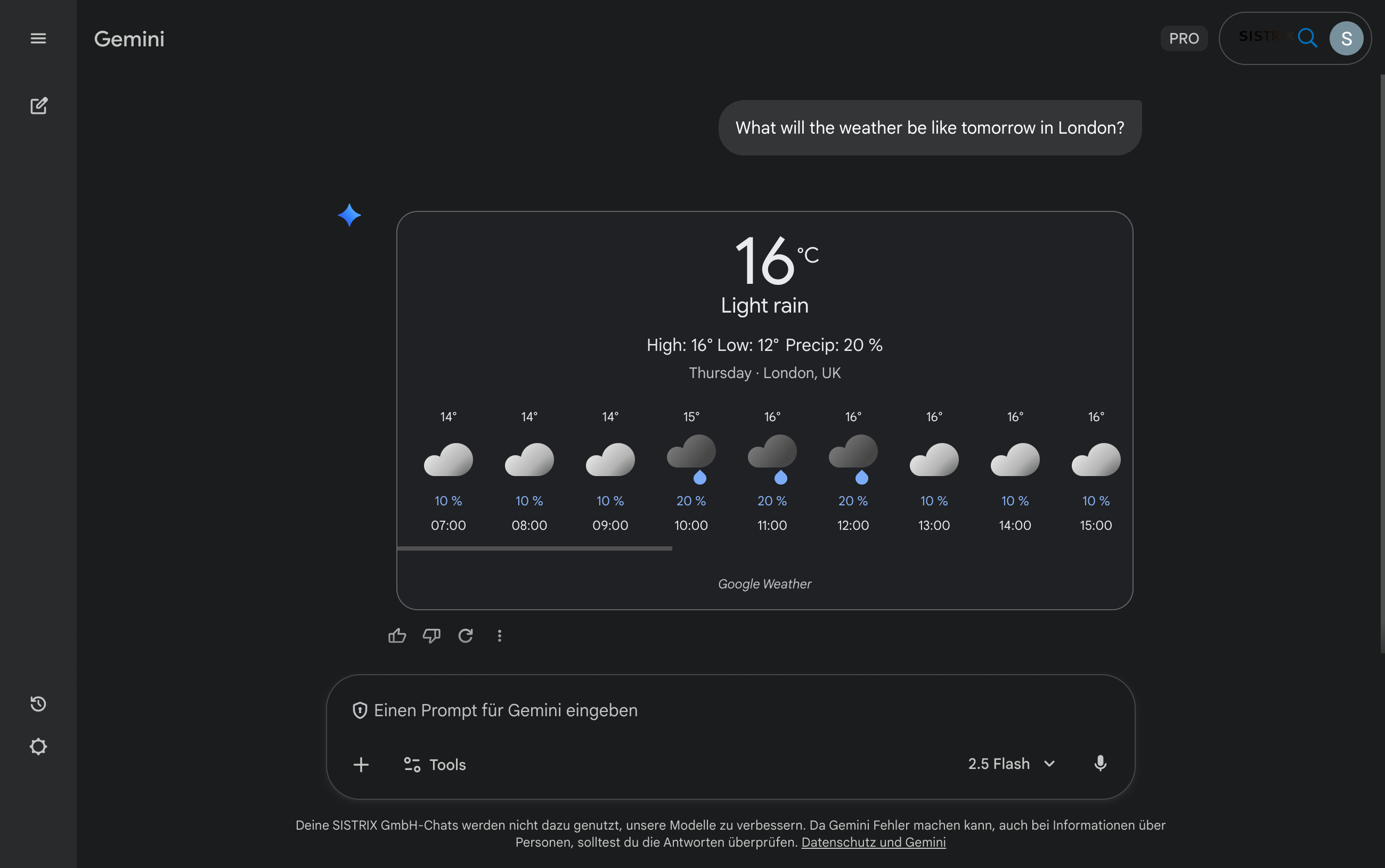
Unlike pure AI search engines, these hybrid systems are more dependent on external search infrastructures. They do not search the entire web on their own, but rather select specific pages that can be found via established search engines. This shows how important search engine rankings will continue to be for mentions in AI responses in the future.
AI chatbots without web search
In addition to AI search engines and chatbots with browsing capabilities, there is a third category: language models that are based purely on their training corpus and do not have access to the web. These systems can create content, answer questions or rephrase texts, but only based on the knowledge they have absorbed up to the point of their training.
Although ChatGPT has an optional web search function, it does not use it in most cases and for most queries. By default, the model draws on its extensive knowledge base, which consists of the training data. Only when the browsing function is actively enabled or ChatGPT itself decides that current data is needed does it access the web.
Claude (Anthropic) specialises in processing longer contexts, analysing texts and summarising them in an understandable way. However, it does not have built-in web access. When Claude answers a question, it relies solely on what was included in the training material or what the user provides in the chat (e.g. through file uploads or text entries).
LLaMA (Meta) and open-source models based on it, such as Mistral or Falcon, also belong to this category when they are operated locally or without connection to additional search services.
Outlook: Will AI search replace traditional search?
The speed with which ChatGPT has established itself since its introduction is unprecedented in the history of digital technologies. According to the latest study, How People Use ChatGPT (2025), 10 per cent of the world’s population now uses the system regularly, just a few years after its release, making it one of the fastest-growing digital products ever. The fast, linguistically accessible response is attractive, especially for mobile use, voice assistants and context-based information needs.
But it will not completely replace traditional search. There will continue to be many situations in which users want to choose for themselves which sources they trust. Traditional link-based search remains relevant, especially for complex topics, diversity of opinion, research or shopping. Even in a business context, AI answers are not so certain and reliable that you can blindly rely on them. It is therefore becoming increasingly important to acquire fact-checking skills. And the classic search engine is particularly suitable for this.
The challenge for website operators and SEO specialists is to serve both worlds: designing content in such a way that it ranks well in traditional search results and also appears as a source in AI-generated responses. In future, this will require one thing above all else: content that stands out from the crowd and offers genuine added value. Simple glossary texts are a thing of the past, and encyclopaedias such as Wikipedia are increasingly being replaced by AI search engines that incorporate their knowledge under the guise of ‘fair use’.
At the same time, however, the question arises: How can the web finance itself in the future if AI systems extract content but no longer pay for it through traffic? Many business models are based on this fair exchange, as well as on the protection of intellectual property rights to content. This question remains largely unanswered – but it will shape the debate on SEO and content production in the coming years.
Test SISTRIX for Free
- Free 14-day test account
- Non-binding. No termination necessary
- Personalised on-boarding with experts