
With llms.txt, website operators can directly control which content should be processed by AI systems such as ChatGPT or Gemini. What the file is capable of, where chances and risks lie and why a testing it might not be the best option for many.
Discover how SISTRIX can be used to improve your search marketing. Use a no-commitment trial with all data and tools: Test SISTRIX for free
The file llms.txt is a suggestion for a new standard relating to the interaction between websites and AI systems. They specifically target so-called Large Language Models (LLMs) such as ChatGPT, Claude or Gemini that analyse and process content from publicly available web sources.
If you look at the technical side of things, it’s a simple text file with a Markdown format that is set up in the root index of a website. It has the goal of directing AI bots to specific content, similar to how a site map does for conventional search engines. The file is supposed to help identify relevant and high-quality content quicker and to make it more usable in an efficient way.
The difference to robots.txt, which regulates access, and sitemap.xml, which displays the full structure of a site, is that llms.txt is connected to the curation of content. Website operators can specify which exact pages are especially relevant for LLMs, such as guidelines, FAQs or thematically central instructional articles.
Visibility in Chatbots: where llms.txt’s limits lie
The idea behind llms.txt is comprehensible. Website operators should be able to control directly, which content language models such as ChatGPT or Gemini are processing. In practice, this effect stayed humble so far. Currently, large suppliers are not actively using the file. Whoever wants to understand where a brand is actually showing up in chatbot responses, needs reliable data instead of just technical indicators.
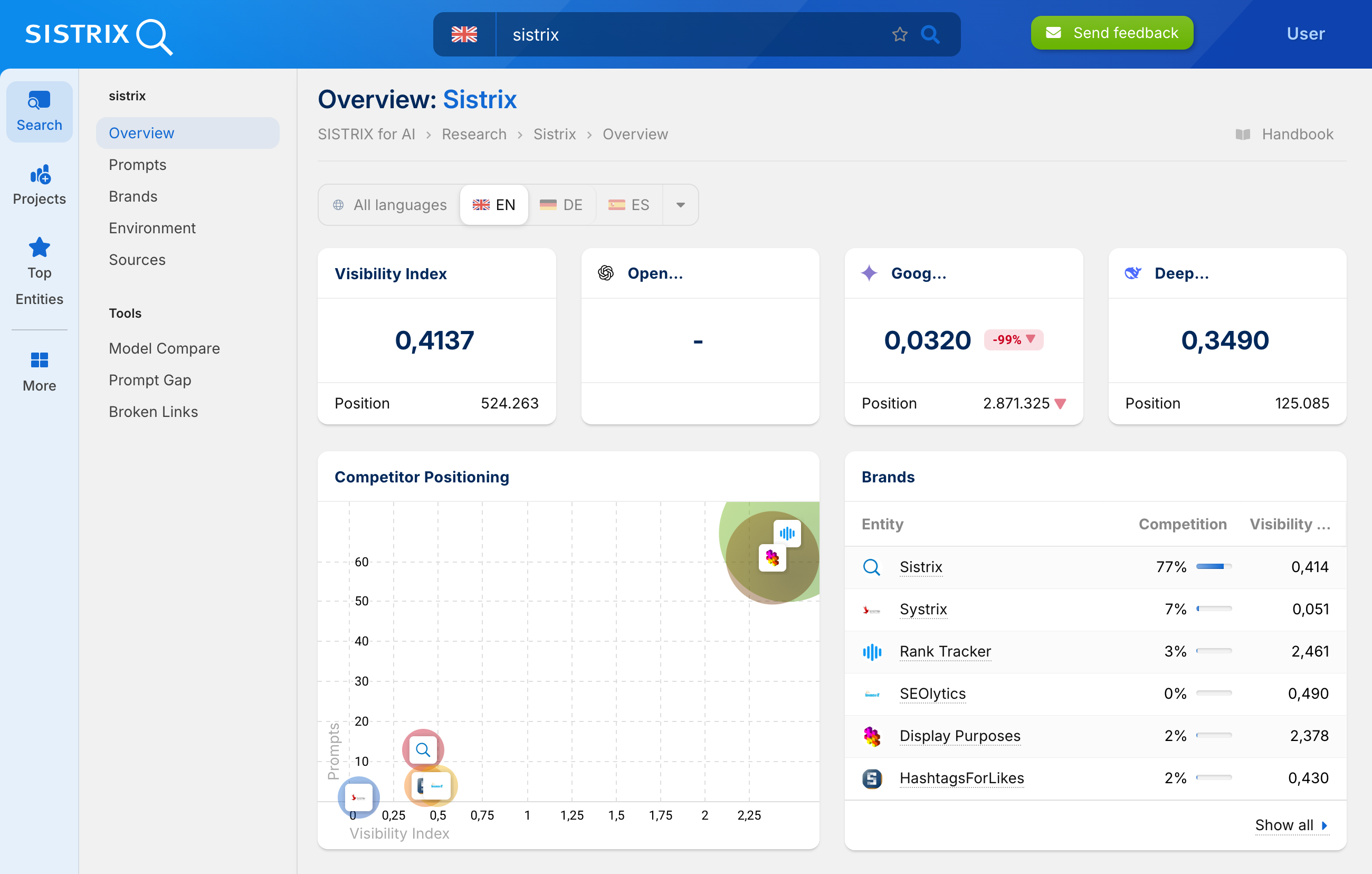
At this intersection is where the new SISTRIX Beta for chatbot analysis begins. Based on ten million meticulously chosen prompts, we analyse the answers in which a domain is mentioned, how often brands appear and which content is actually processed by the models. This way, you can systematically reconstruct the visibility of your brand within AI chatbots.
The analysis is currently available as a beta version and is constantly being expanded. If you want to gain early insights, you can sign up to gain access. To be able to sign up, you need to have an active SISTRIX account. If you just want to try out SISTRIX first, you can sign up for a 14 day test account and start immediately.
Who is behind llms.txt?
The proposal of llms.txt was made by Jeremy Howard, co-founder of the AI research lab Fast.ai and the AI company Answer.ai. It was first published on the 3rd of September 2024. The file was offered as a potential solution on Answer.ai and GitHub in order to provide LLMs more directly with high-quality web content.
The structure orients itself by the Markdown format: clear headlines, a descriptive section and a list of URLs that are supposed to be preferably processed by LLMs. The idea is to create a more transparent and easily maintainable table of contents for AI bots.
Examples for a llms.txt file
# Title
> SEO and data provider
## Exposed to LLMs
[some good examples] (https://www.example.com/seo-examples): Great examples
[whitepaper] (https://www.example.com/whitepaper/seo-tools-2025)
[faqs] (https://www.example.com/faq/seo-faq)
## How to articles
[How to] (https://www.example.com/how-to/): Overview of the how-to articlesPractical relevance for SEO
The topic of llms.txt directly so-called LLMO—meaning the optimisation of content for AI supported response systems. More and more users are receiving their information straight from generated answers from language models, for example the Google AI Overviews or ChatGPT, instead of conventional search result pages. Whoever wishes to gain in visibility there needs to make sure that their content is structured, citable and clearly detectable.
The idea behind llms.txt is to help out with this exact issue. Instead of an LLM needing to fight through complex navigation, unstructured pages or embedded pop-ups, it receives a precise list of curated URLs. In a way, a “list of recommendations” from the website operators themselves.
In theory, because of this LLMs can:
- Quicker access to relevant information
- Handle limited context windows more efficiently
- Extract high-quality content in a targeted way
- Make the website operator more visible in response generation
In addition, there is another technical advantage: whoever can offer separate, slimmed-down Markdown versions of their content to the LLMs can improve server performance, optimise loading times and structure the communication with bots; a kind of API-light for text.
Arguments in favour of the application
Even though llms.txt is still an experimental suggestion, there are good reasons to consider its implementation:
- Short paths towards the best content: By clearly referencing high-quality URLs, LLMs can find relevant content much quicker—without having to work through navigational paths or irrelevant side elements.
- Low technical effort: The file is easy to create, maintain and can be inserted into the CMS or existing SEO structures without too much of a hassle.
- Potential of controlling representation by AI: If you don’t want outdated content to show up in AI responses, you can control what is reference within the file and what isn’t.
- Technical advantages via reduced content: Those having to battle with AI traffic can provide .md files with a reduced markup and without visual layouts and link them in llms.txt. This saves bandwidth and increases comprehensibility.
- Early positioning for new standards: Robots.txt, schema.org and AMP also launched without a larger support network and developed into established standards.
Criticism and counter-arguments
Simultaneously, there are many voices calling for caution, naming good reasons to not implement llms.txt too quickly:
- Low distribution: So far, less than 0.005% of all websites worldwide are using the file. It is definitely not yet a standard.
- Lack of support by bigger providers: Google themselves has established that llms.txt is not being used by any of the larger LLM providers so far. John Mueller compared the file to the old meta keywords tag, an element that is being fully disregarded due to massive exploitation by site operators and SEOs.
- Danger of exploitation: Theoretically, website operators could link content in llms.txt that is not visible for users or search engines; a potential cloaking risk.
- No proven SEO advantage: Currently, there is no proof that this file improves ranking or visibility in any way. Few to none LLM-supported response systems are using it.
- Maintenance effort without a clear benefit: Anyone who owns many sites has to regularly update the llms.txt. Without a visible benefit, this effort is scarcely worth it.
What do Google, OpenAI and others say?
Google currently opposes llms.txt and deems it to be unproductive. OpenAI hasn’t officially given a statement yet, despite indications of crawling via the OAI SearchBot showing up in log files.
However, Yoast has taken on the suggestion and offers in their widespread SEO plugin an automatic generation. A few smaller providers are also experimenting with the format, but it is still miles away from a real ecosystem.
Additionally, Google recommends to set llms.txt to “noindex” for them to show up in the search results. This clearly shows: from Google’s point of view, this file is not a ranking factor but a purely technical add-on without a clear advantage.
So, should you implement llms.txt?
The answer to this question strongly depends on your website. A blanket recommendation is, as always, not (yet) possible. A few scenarios:
- For adventurous providers with technical resources and AI-supported traffic, a test run can be useful. However, you should clearly limit which content is included in the file and monitor the impact via logs or crawling statistics.
- For conventional business websites without a focus on LLMs or a strong focus on organic visibility on Google, there is currently no real benefit. Instead, you should invest in proven measures such as content quality, core web vitals or structured data.
- For platforms with a large editorial offering, llms.txt can be an additional layer to steer the focus on especially citable content—if it is already optimally structured and retrievable.
llms.txt is a technically interesting but in practice widely irrelevant suggestion so far. Its origin coming from a company close to AI shows the large role that strategic and economic interests usually play when it comes to the topic of AI. Anyone engaging with the topic should keep this in mind and have objective and factual discussions about it.
Currently there is no acute need to act. Whoever wants to test it can do so but whoever waits until new standards are built won’t do anything wrong and potentially even saves on unnecessary investments. What’s important: structured, quotable content, clean technology and clear navigational paths are essential, regardless of being for search engines or language models.
Test SISTRIX for Free
- Free 14-day test account
- Non-binding. No termination necessary
- Personalised on-boarding with experts