
Sometimes it may happen that the numbers you get from a Google site:-query, the Google Search Console (GSC) and the SISTRIX Toolbox do not match.
Discover how SISTRIX can be used to improve your search marketing. 14 day free, no-commitment trial with all data and tools: Test SISTRIX for free
You are not able to directly compare the numbers you get from a site:-query on Google and the Google Search Console, as the later are calculated separately by Google. This is why you will get different results which are published at different times.
Comparing the indexed pages: Google site:-query and the SISTRIX data

The number of indexed pages in the SISTRIX Toolbox is an average
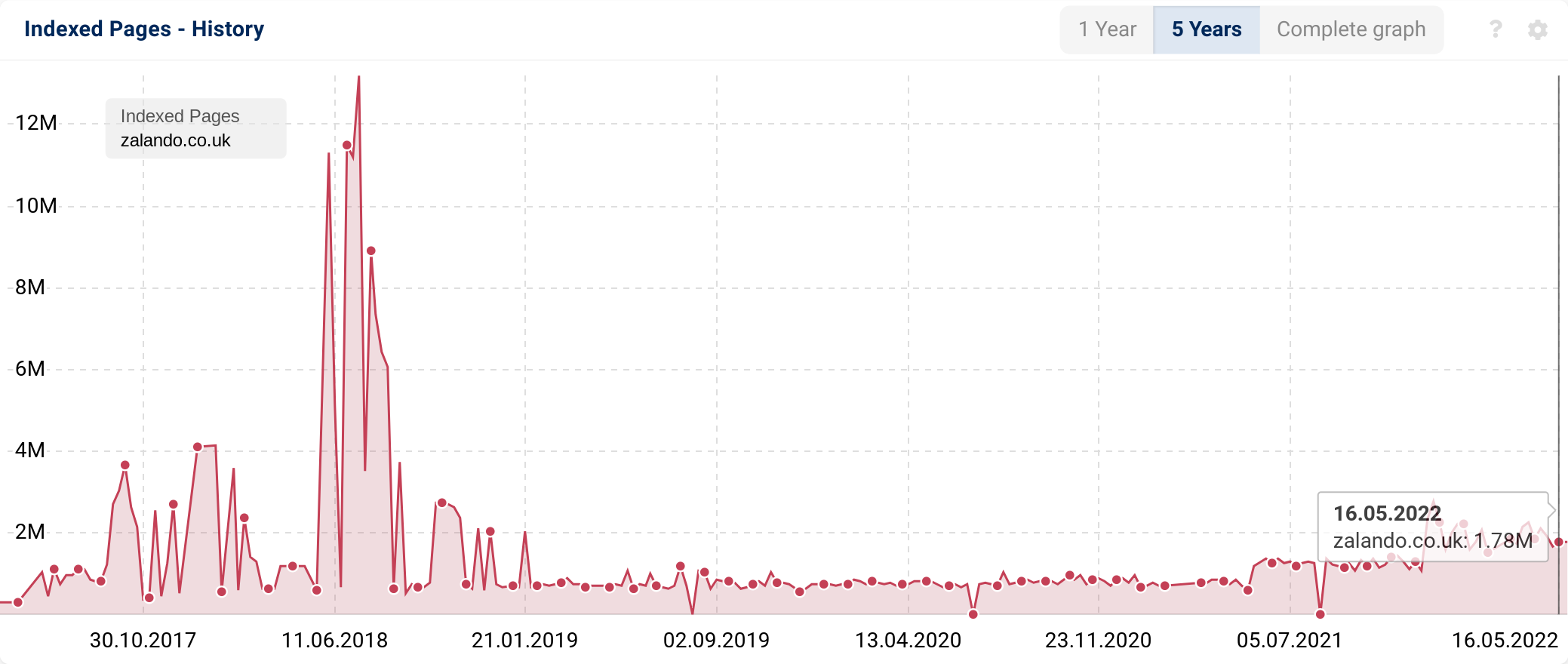
According to statements by Google, the number of indexed pages becomes only a rough estimate at more than 1,000 pages (mind the word “about” in front of the results). In order to eliminate the biggest outliers, we collect the SISTRIX data multiple times per week and then calculate the average value. To do so, we run site:-queries on Google, which ensure that our values come straight from Google, we only calculate an average over the weekly data. If we show the indexed pages have gone up (or down), then these are the numbers that we got from Google, at the time of our site:-query. We also only add a new data point to the history when we notice a change in the average amount.
Values that fluctuate strongly should be examined
If your indexed pages vary noticeably, you should nonetheless take a look at the cause of this. In many cases, duplicate content or content that Google values as less important are the cause. Google will index these pages at first (the number of indexed pages goes up) and then filters out duplicates and less important pages again (the number of indexed pages falls). This also applies to print versions of pages, Sessions IDs, Affiliate-Links and others.
Example using red-simon.com
To give you an example, let us look at the site:-query for the domain red-simon.com in 2013. Towards the back (results page 10 in our example), we can notice the reason for a noticeable increase in the number of indexed pages:

With red-simon.com we can see that there are a lot of dynamic URLs (with numerous parameters) which can be found in the search results (for example red-simon.com/data/cmsv2.asp?mid=41&sid=1&pid=533).
These pieces of content can probably be accessed through a number of different URLs and are therefore duplicates. To some extend these pages were also redirected using a 302 redirect, which Google does not understand. Always use a 301-redirect for your redirects.
It would surely be good for the website to have the dynamic URLs removed and replaced by static URLs. mod_rewrite could be one approach to handle this example.
- More evaluations for strongly fluctuating numbers of indexed pages:
Why does the amount of indexed pages fluctuate so much?
Test SISTRIX for Free
- Free 14-day test account
- Non-binding. No termination necessary
- Personalised on-boarding with experts