
In this tutorial we explain how to use regular expressions so that you can apply their advantages in the SISTRIX Toolbox. For example: filtering URL, snippet or keyword tables.
- What is a regular expression?
- How can we build regular expressions?
- SEO examples with regular expressions
- Filtering keywords with regular expressions
- Include or exclude brand name
- Include or exclude errors in branded terms
- Include or exclude keyword terms ending with specific words
- Include or exclude keyword terms starting with specific words
- Include or exclude keyword terms containing the name of cities in the United Kindgom
- Filtering URLs with regular expressions
- Include or exclude subdomains
- Include or exclude URLs ending or not ending with /
- Include or exclude URLs containing numbers
- Include or exclude URLs in a particular format
- Include or exclude URLs pertaining to incorrect markets
- Summary
What is a regular expression?
A regular expression is used to check or to verify a pattern. Their main application is for filtering elements and finding matches, for example, in the following scenarios.:
- Analytics: you could use Regex to segment traffic.
- Htaccess: you could rewrite URLs in a more efficient way.
- SISTRIX: you could filter our reports containing URLs, snippets or keywords.
Regular expressions –or Regex– can be used in many programming languages, but this tutorial is going to be based on Perl, as it uses the standard on which the already available SISTRIX Regex functionality is based.
How can we build regular expressions?
We are going to do this by using characters, groupings, quantifiers, and classes, as it’s the syntax through which we are going to be able to build expressions.
| Characters | Behaviour | Example |
|---|---|---|
| ? | Looks for the preceding character 1 or 0 times. | https? |
| * | Looks for the preceding character 0 or more times. | 30* |
| + | Looks for the preceding character 1 or more times. | [0-9]+ |
| | | Looks for one element or another. (or) | (jpg|jpeg) |
| ^ | Indicates the start of the pattern | ^https |
| $ | Indicates the end of the pattern | html$ |
| · | Looks for any character (wild card) | 4.. |
| \ | Doesn't interpret a special character (skip characters) | \/ |
| Grouping | Behaviour | Example |
|---|---|---|
| () | Captures specific content | (sistrix) Matches sistrix |
| [] | Captures characters within the brackets | [0-9] Matches any numeric character [a-z] Matches any lower case letter |
| {} | Indicates number of iterations, minimum or maximum | .{1,3} Matches with any character repeated between 1 and 3 times. |
In this tutorial we won’t be using quantifiers, but we think it’s still interesting for you to become familiar with them in case you use them in other environments.
| Quantifiers | Behaviour |
|---|---|
| \w | Looks for a word, digit or _ type of character |
| \d | Looks for a digit character |
| \s | Looks for a whitespace character |
| \b | Matches start or end of a word |
| \W | Looks for a character that isn't a word, digit or _ |
| \D | Looks for a character that isn't a digit |
| \S | Looks for a character that isn't a whitespace. |
SEO examples with regular expressions
To be able to use the suggested examples, you need to go to the ‘Keywords’ section and use Keyword, URL, Title or Description filters.
Filtering keywords with regular expressions
To access this feature you only need to analyse a domain 1 and go to Keywords 2, and then go to the Filter selection 3
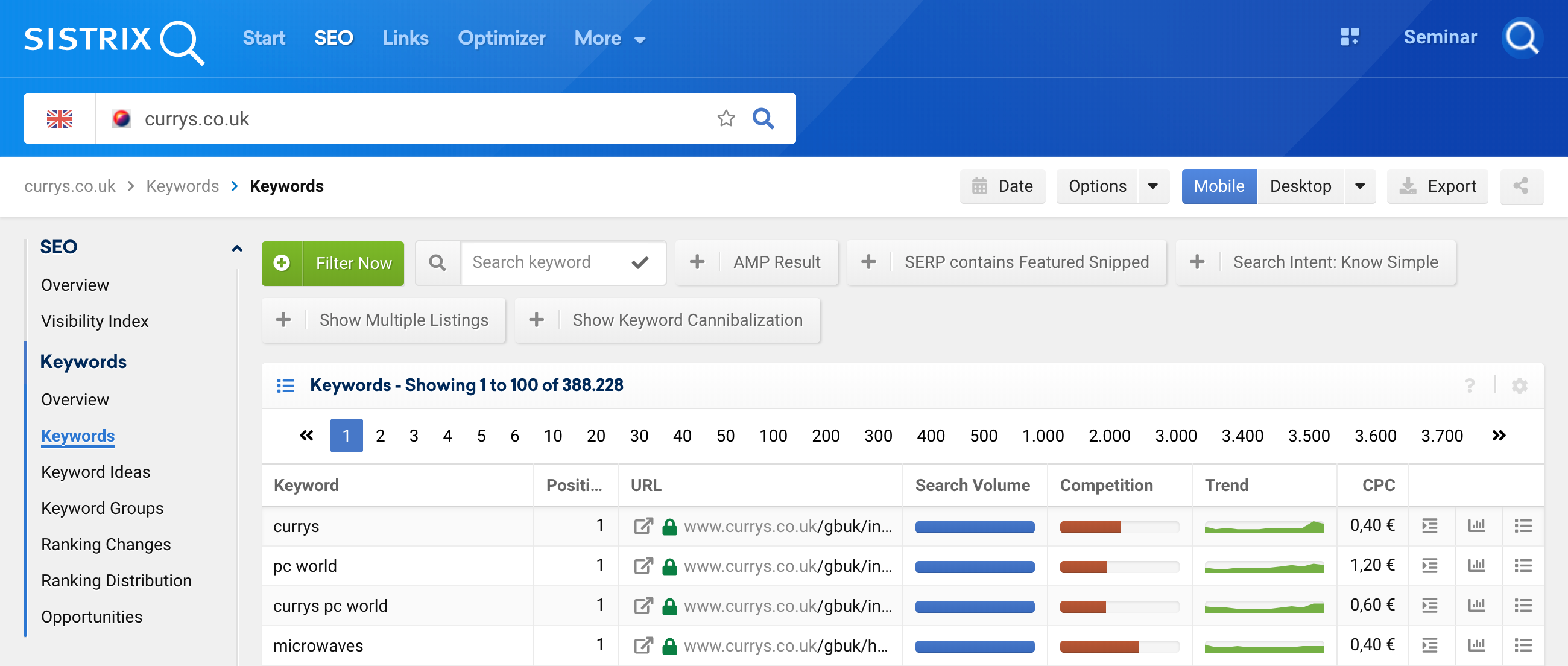
And then, use the keyword filter with Regex 4.
Now we would like to propose several use cases where you can apply these expressions to make the most out of the keyword analysis of your projects, or when you’re analysing your competitors.
Include or exclude brand name
Imagine you have a brand which accepts different spellings or is know by several different brand names. We can create a regular expression to group all keywords that we consider to be branded terms. For example, currys.co.uk has various branded keywords, namely:
curry, currys, pc world
Thus, we will use the following expression:
(curry|currys|pc world).*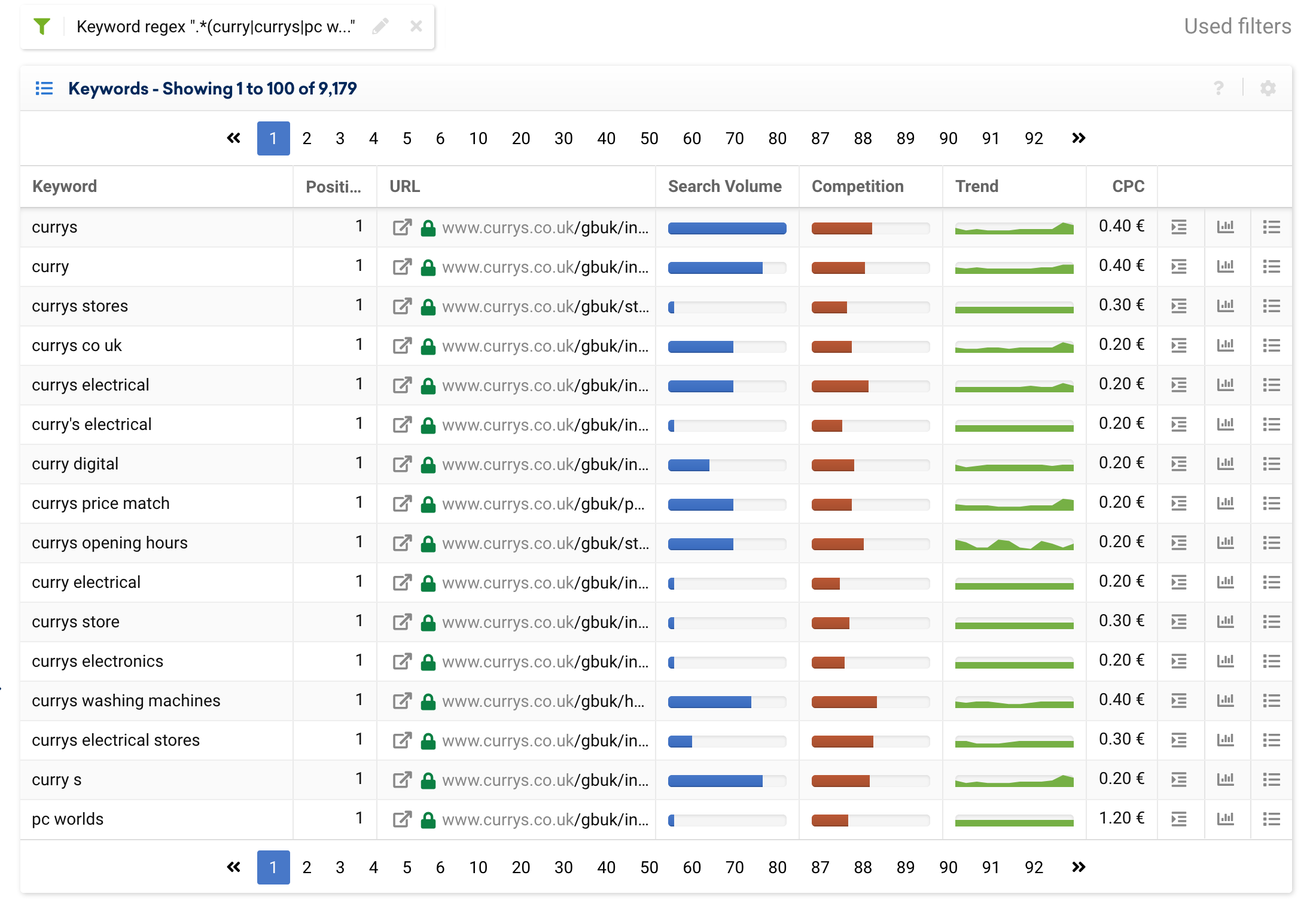
Below you can see the results we would get:
It is also possible to set the filter to exclude branded keywords, using the following expression, and it will display generic keywords only:
^(?!.*(curry|currys|pc world).*?)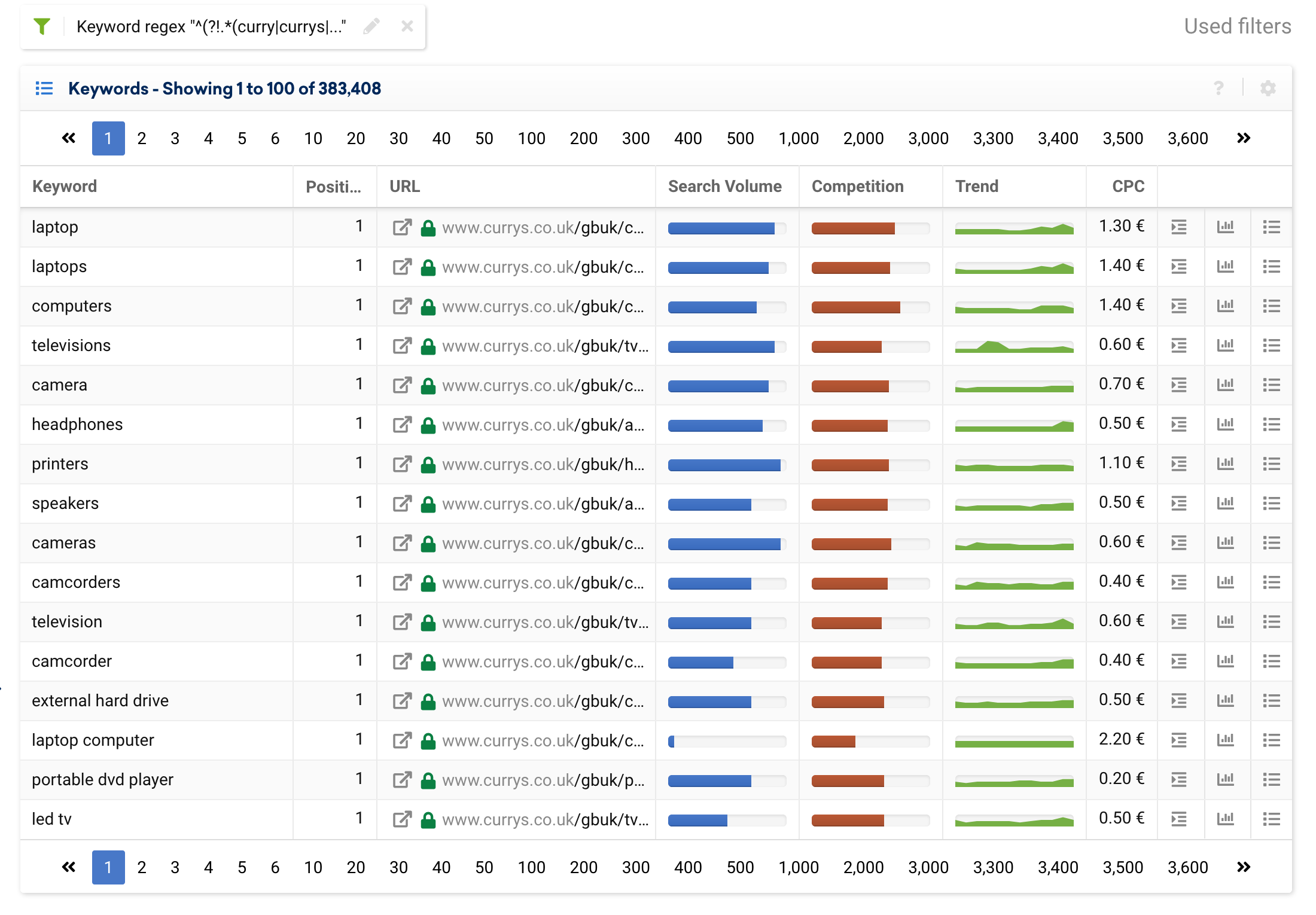
Include or exclude errors in branded terms
There is a chance that we might run into brands, which are often misspelled or written with errors, such as Ryanair.
Here are a few examples of terms users enter to look for this airline:
- ryanair
- rayaner
- ryan ir
- rayan ir
- rayana eir
- raya nair
- rayan ari
- rayar air
We have identified over 35 brand names we can capture using just a single regular expression:
To include all brand variations:
(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?![Keyword Table in the SISTRIX Toolbox for ryanair.com with the regex filter ".(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?" applied.](https://www.sistrix.com/wp-content/uploads/2019/09/ryanair_com-regex.png)
To exclude all brand variations:
^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?).)*$![Keyword Table in the SISTRIX Toolbox for ryanair.com with the regex filter "^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?).)*$" applied.](https://www.sistrix.com/wp-content/uploads/2019/09/ryanair_com-regex-2.png)
Of course we can still apply other filters to this list, like “contains”, “doesn’t contain”, “ends with”, or “starts with”.
Include or exclude keyword terms ending with specific words
To search for a unique keyword, a simple filter will suffice, but if we would like to perform a search with several conditions, for example: all keywords starting with “buy” and ending with “online”, we can use:
^buy.*online$This, applied to an online store like screwfix.com, would return the following results:
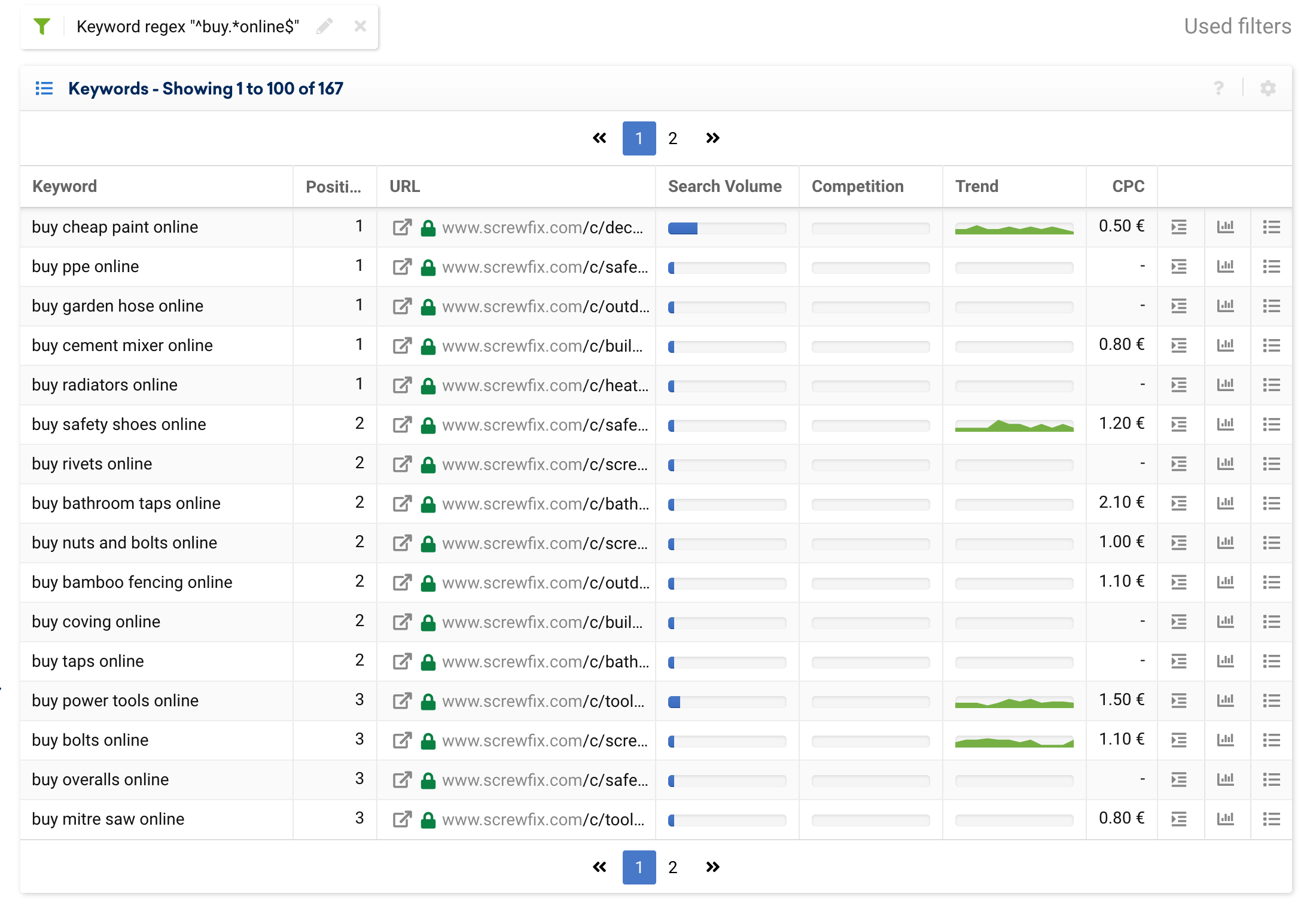
Include or exclude keyword terms starting with specific words
From a comparison tool’s point of view it can be interesting to be able to filter keywords containing various brand names.
For example, we can create a regular expression that will group terms based on the criteria we want, which in this case is, any keyword term starting with any brand name included inside the brackets:
^(sony|panasonic|philips|samsung).*Similarly, we can use it to exclude them:
^(?!(sony|panasonic|philips|samsung).*)Include or exclude keyword terms related to specific attributes
Let’s try this with an example of an attribute commonly encountered in many projects: price.
There are many search queries which allude to the price, such as: “cheap”, “discount”, “outlet”, “coupon”, “offer”, “low cost”, “budget”, etc.
If we want to exclude them from the results, we can use the following expression:
.*(cheap|budget|offer|outlet|price).*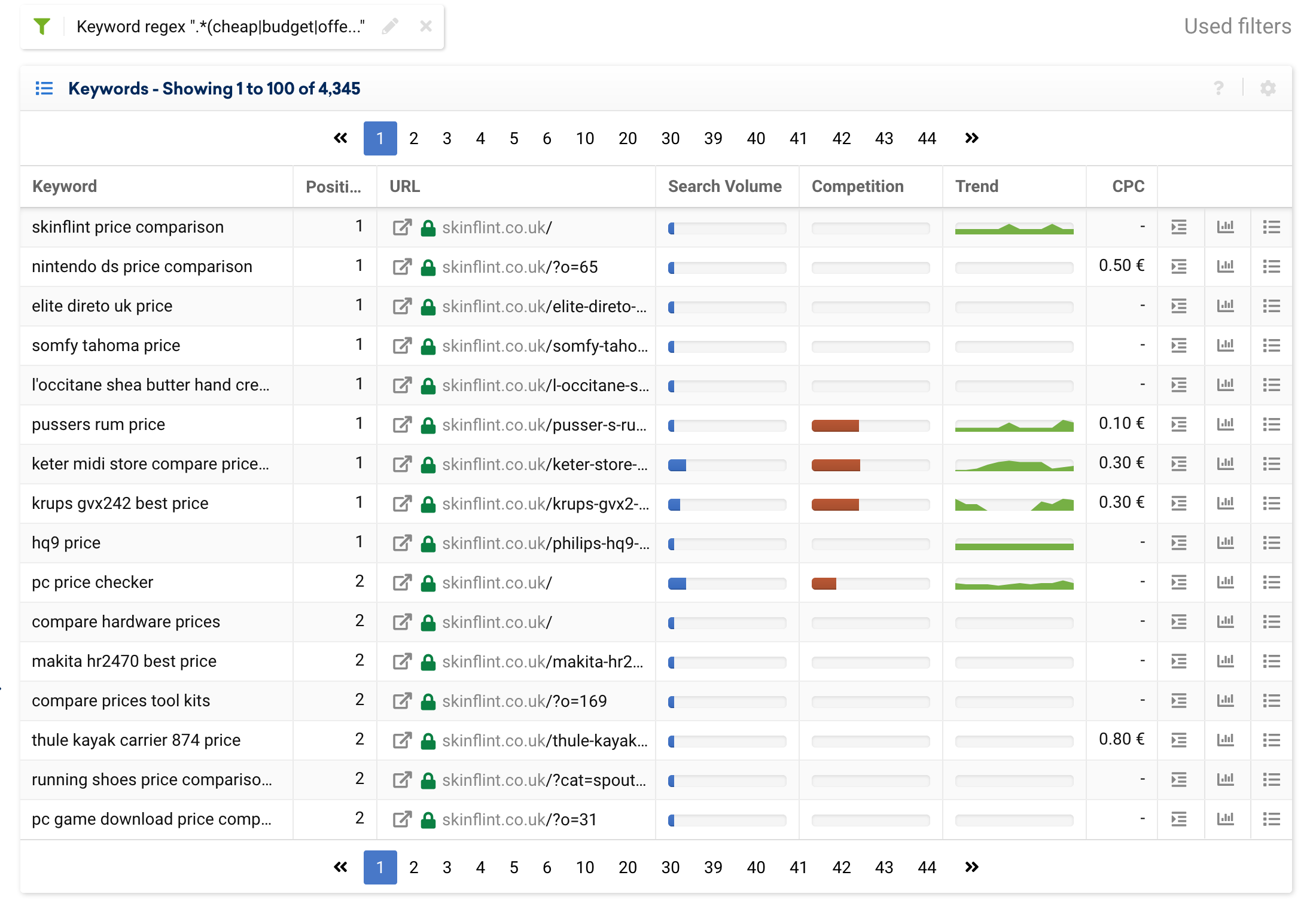
Making use of the table’s dynamic columns, we can organise the data by search volume in descending order, by simply clicking on the column’s header.
In other cases we can also use other attributes like colours, shapes, sizes, target, etc.
Include or exclude keyword terms containing the name of cities in the United Kindgom
Many projects require a local presence tracking. To do this, we can use Regex to group provinces, regions, cities, towns, etc.
In this example we are going to take the list of cities to build a regular expression that will filter keyword terms containing a city.
.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*Any e-commerce business or a comparison tool with a physical presence can use this expression to exclude cities, and even add branded keywords or exclude other parameters.
^(?!(.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*))However, we can also separate them into several expressions, as shown below:
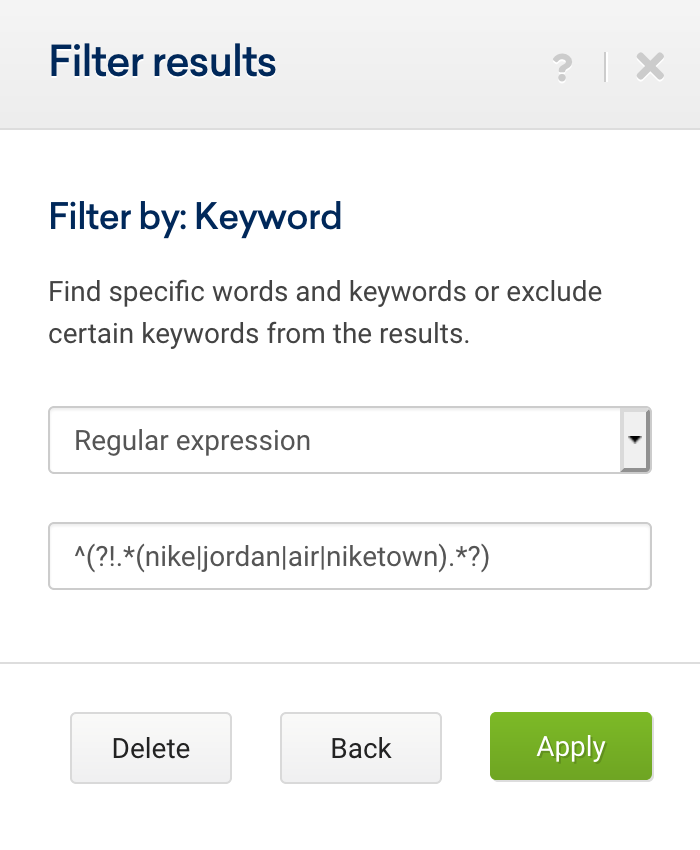
From here on we add the Expert Filter to indicate that these two expressions are of type “and”, instead of type “or”.
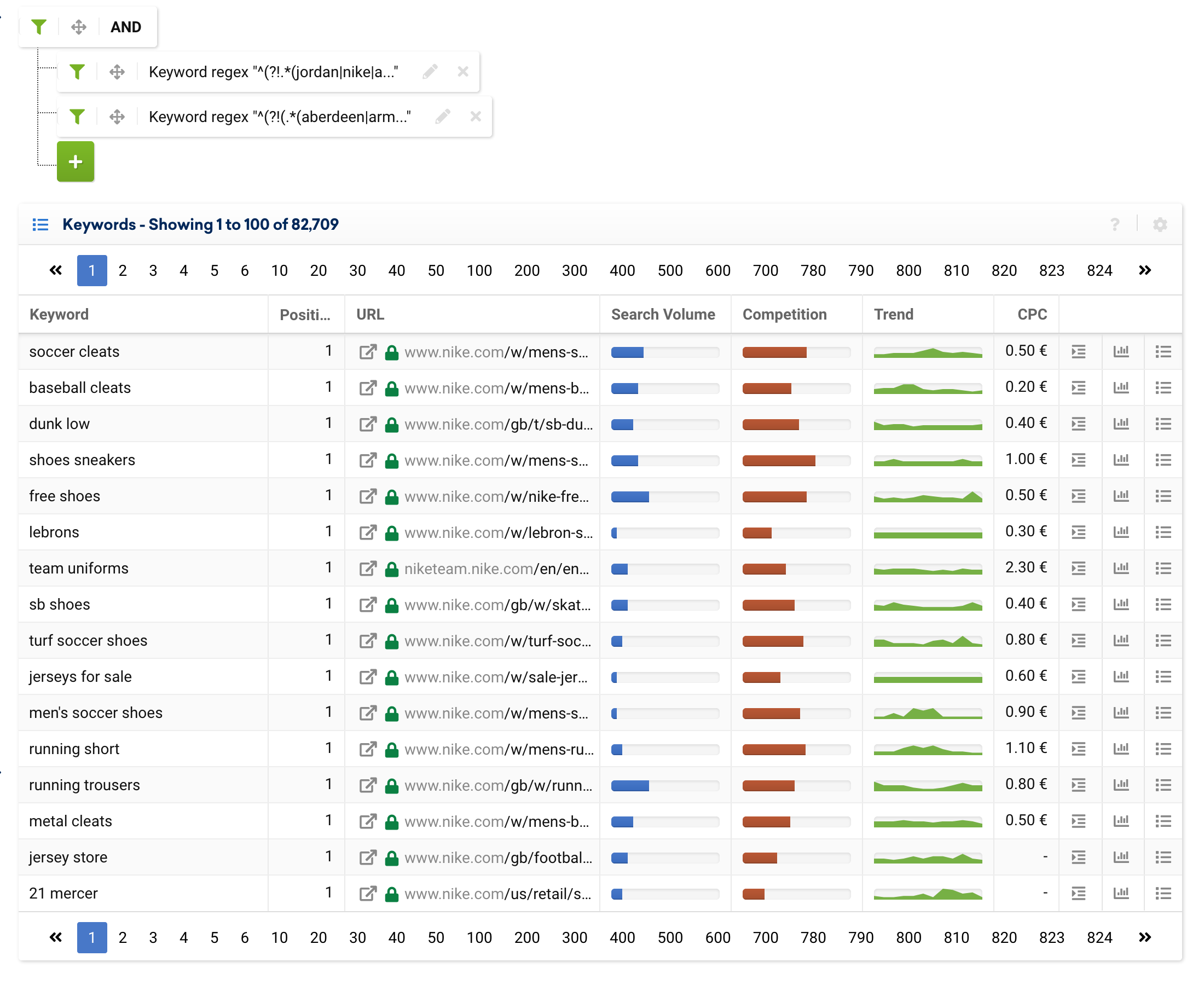
Filtering URLs with regular expressions
The steps you need to follow in order to filter URLs are the same as those we explored for keywords, the only difference is, you would have to select “URLs” and then regular expressions.
Include or exclude subdomains
Now that we’ve learnt how to use regular expressions to filter keywords, let’s find some typical SEO use cases in which we would need to filter URLs.
Here are some basic use cases for analysing an entire domain and grouping URLs by strategic subdomains:
(www|support)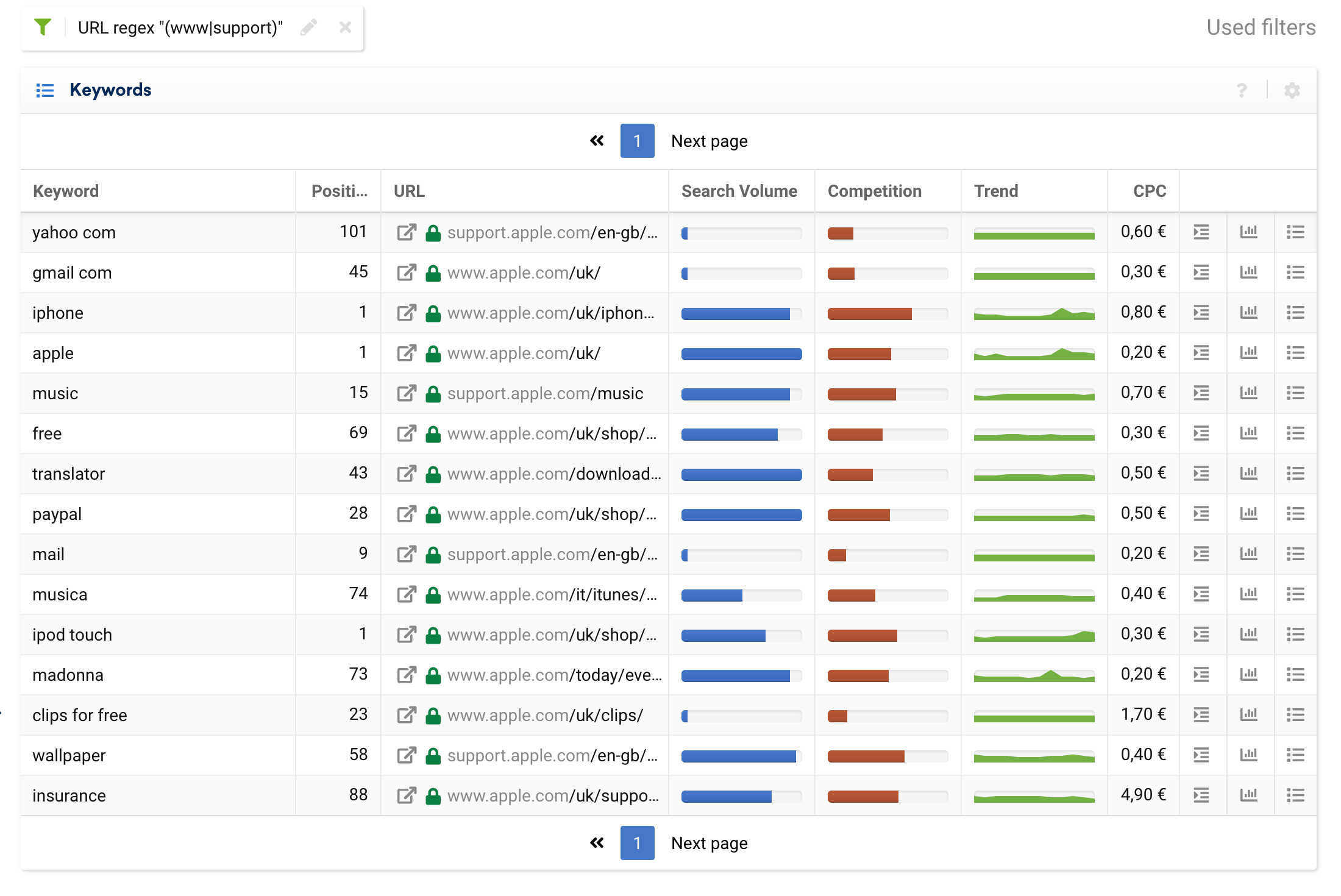
We can use an exclusion filter to, for example, separate purely transactional subdomains, and leave out informational keywords coming from the blogs or FAQs.
^^(?!.*(www|support).*?)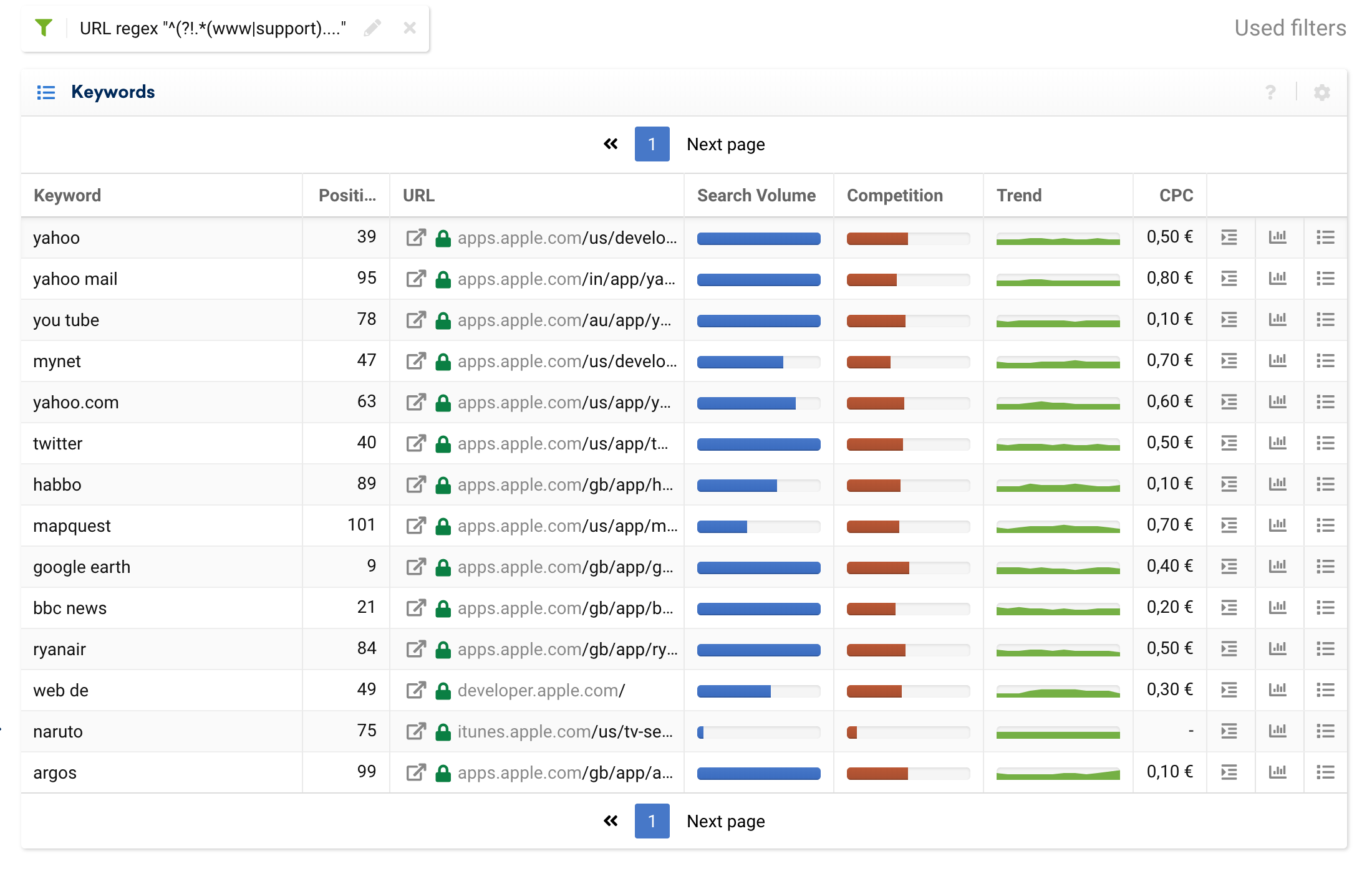
Include or exclude URLs ending or not ending with /
If the home page’s .com domain ends in a slash, the regex can be adapted to match:
^.*.com/$^(?!(.*.com/$))Any URL ending with /
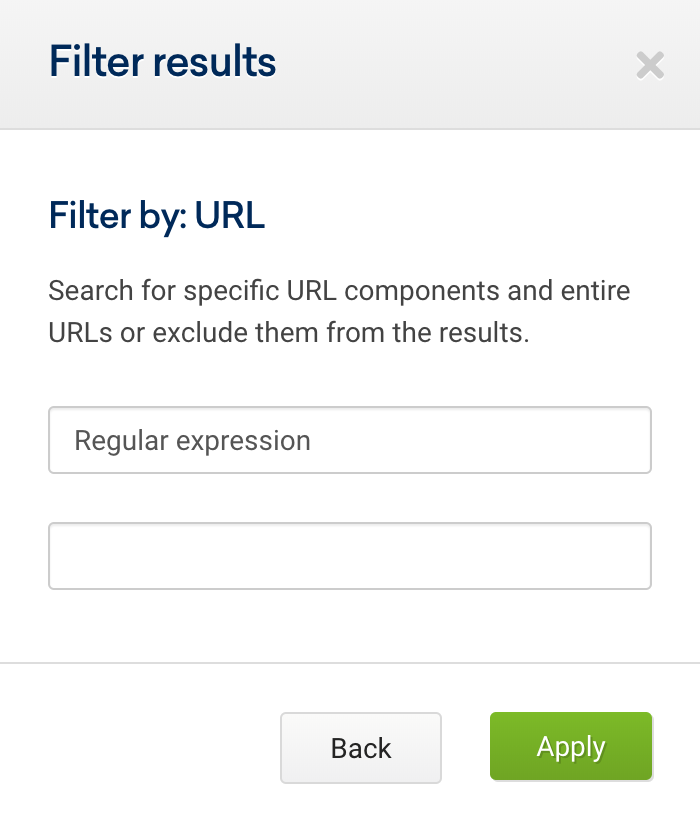
.*/$We can also use this Regex for URLs, to focus exclusively on URLs ending with the slash (/). To do so, enter the domain into the search bar (1), then click on URLs in the navigation (2), add a filter (3) and choose the URL filter as “regular expression” (4):
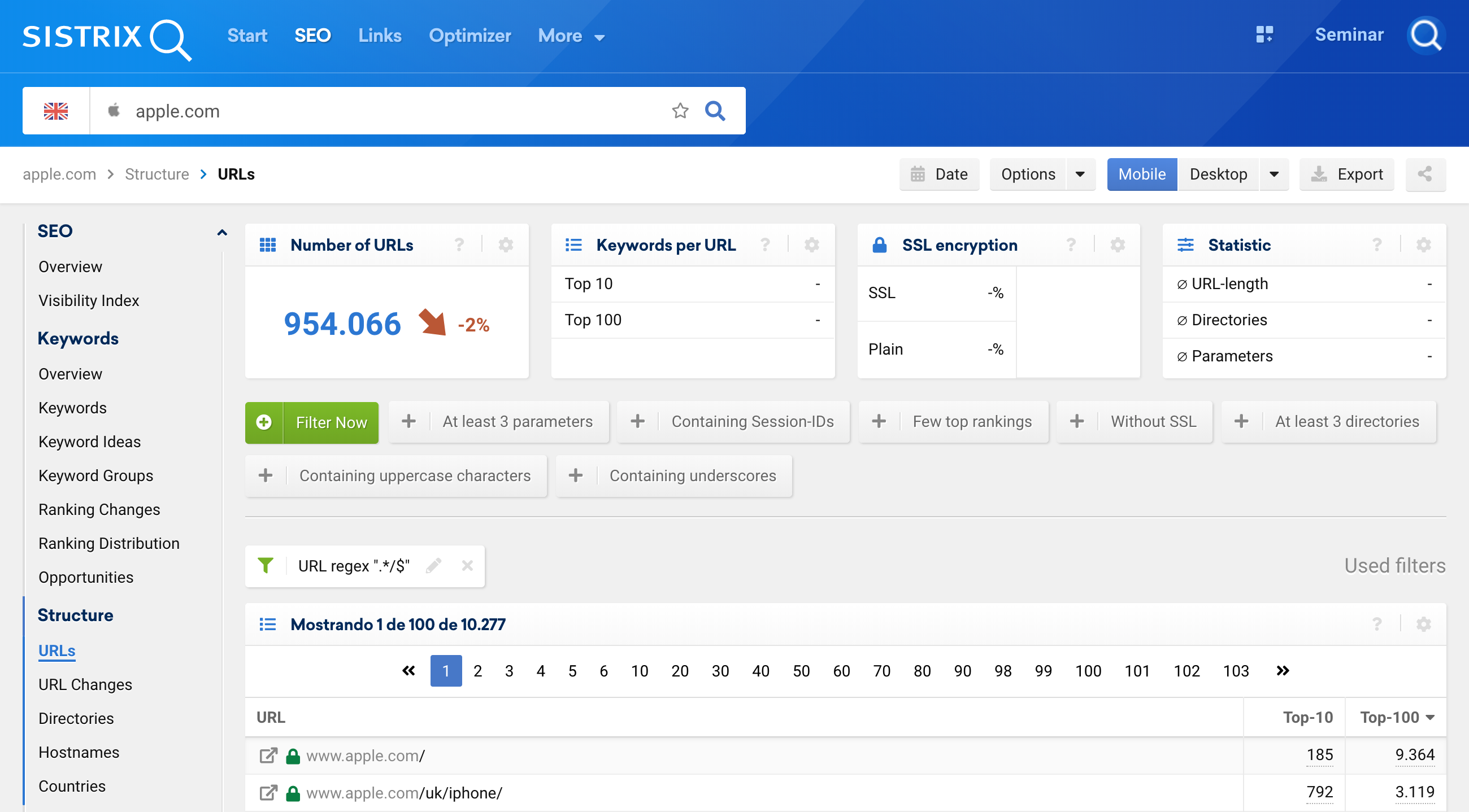
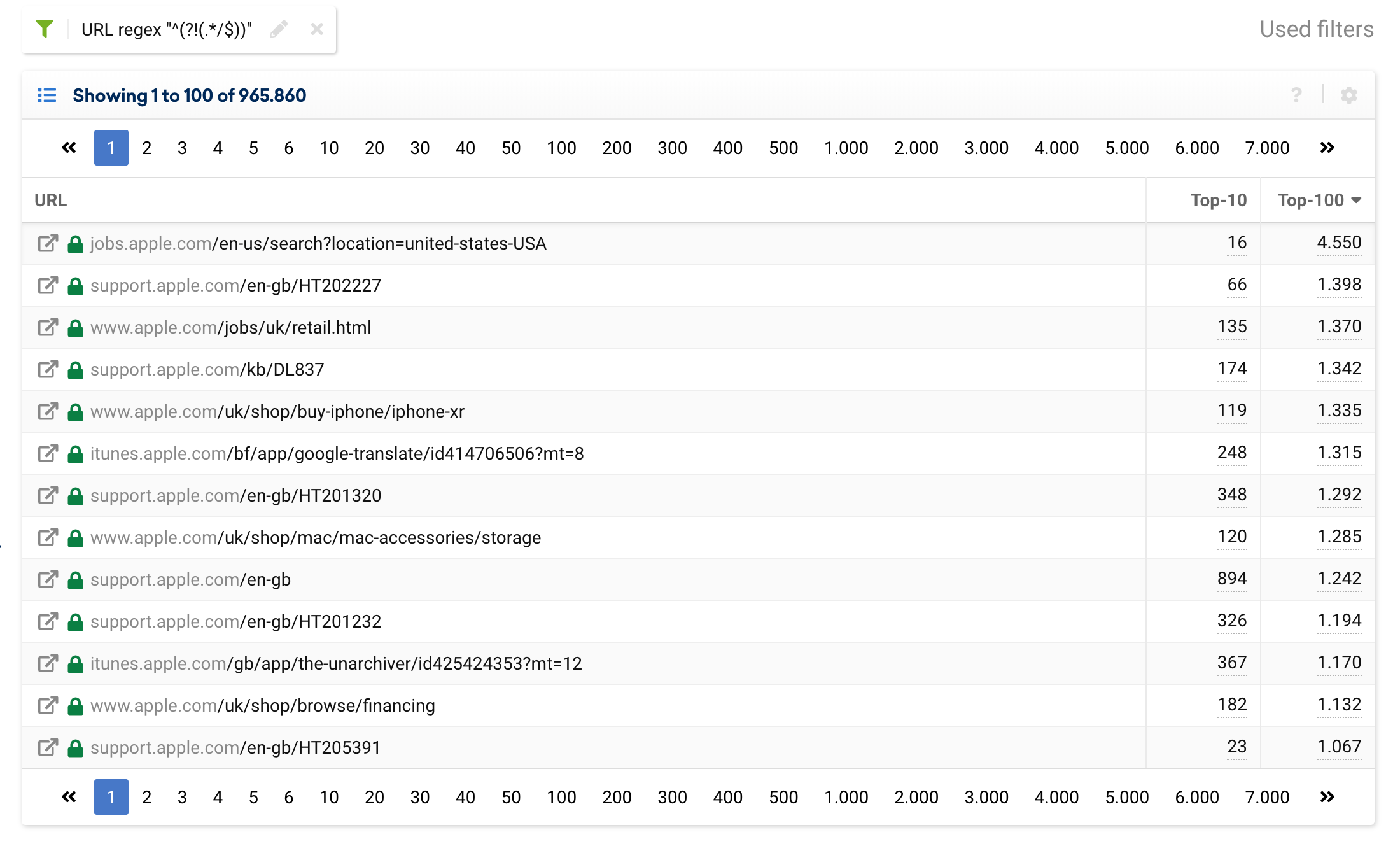
Of course, this also works for URLs not ending with /
^(?!(.*/$))
Include or exclude URLs containing numbers
We can tinker with the URL syntax to identify which ones contain numbers to include or exclude them:
.*-[0-9].*^(?!(.*-[0-9].*))If we want something more specific, and we know there are URLs ending with a particular number, we can also include or exclude them as follows:
.*-[0-9]+$^(?!(.*-[0-9]+$))In this instance our request was to filter chains containing series of 8 consecutive numbers.
.*[0-9]{8}.html$^(?!(.*[0-9]{8}.html$))Include or exclude URLs in a particular format
We can use Regex to filter URLs formats, too. For instance, htm or html URLs, as well as pdf ones.
This is fairly easy, as we can count on “ends with” or “contains” filters to do it.
.*htm.?$.*pdf$To exclude the desired URL formats:
^(?!(.*html.?$).)^(?!(.*pdf.?$).)We can use several formats within the same expression, which will be more valuable, and it will save us the hassle of concatenating several filters, to include:
.*(htm|html)$.*(jpg|jpeg|gif|png)$And we can also combine formats to be excluded:
^(?!(.*(htm|html)$).)^(?!(.*htm.?)$).)^(?!(.*(jpg|jpeg|gif|png)$).)Include or exclude URLs pertaining to incorrect markets
We can monitor URLs that shouldn’t be appearing in the results of a specific market. For example, URLs pertaining to the US, Mexican or German markets that appear in the results of the Spanish one.
Taking the following URL instances as our basis:
Spain’s Spanish /es_es/
UK English /en_gb/
US English /en_us/
Italy’s Italian /it_it/
And so on.
We can use Regex to filter the number of URLs that do not belong to the Spanish market.
^(?!(.*[es]_[a-z].*)|(.*[a-z]_[es].*).)![Keyword Table in the SISTRIX Toolbox for hm.com with the regex filter "^(?!(.*[es]_[a-z].*)|(.*[a-z]_[es].*).)" applied.](https://www.sistrix.com/wp-content/uploads/2019/09/keywords-urlfilter-regex-hm_com.png)
As you can see, the expression allows the home page URL, where the language selector is located.
To further refine this expression and to leave the home page out, we can extend it as shown below:
^(?!(.*.com/$)|(.*[es]_[a-z].*)|(.*[a-z]_[es].*).)![Keyword Table in the SISTRIX Toolbox for hm.com with the regex filter "^(?!(.*.com/$)|(.*[es]_[a-z].*)|(.*[a-z]_[es].*).)" applied.](https://www.sistrix.com/wp-content/uploads/2019/09/keywords-urlfilter-regex-hm_com-2.png)
Summary
With the parameters provided in this post you are now capable of finding your own use cases where regular expressions can come in handy and help you make your SEO analyses more efficient.
You can keep testing and practising with tools like https://www.Regextester.com/, or directly with SISTRIX’s URL, keyword or snippet filters.
Even though we do not provide support for Regex, we will continue to update this tutorial with new usage cases and SEO analyses that may turn out to be useful for you.