
Most of the analyses and features in SISTRIX are already based on the extensive SERP data of the extended database. Now, we’re also using this extended database as the default setting for the history of ranking keywords and ranking URLs.
How many rankings a page has in the Top 10 and Top 100 on Google, as well as how many different URLs are responsible for this, is interesting SEO information, especially over time.
While we previously displayed this data by default based on one million keywords, the new default setting is based on the Extended Data. (For example, today that is 55 million keywords in the UK database.)
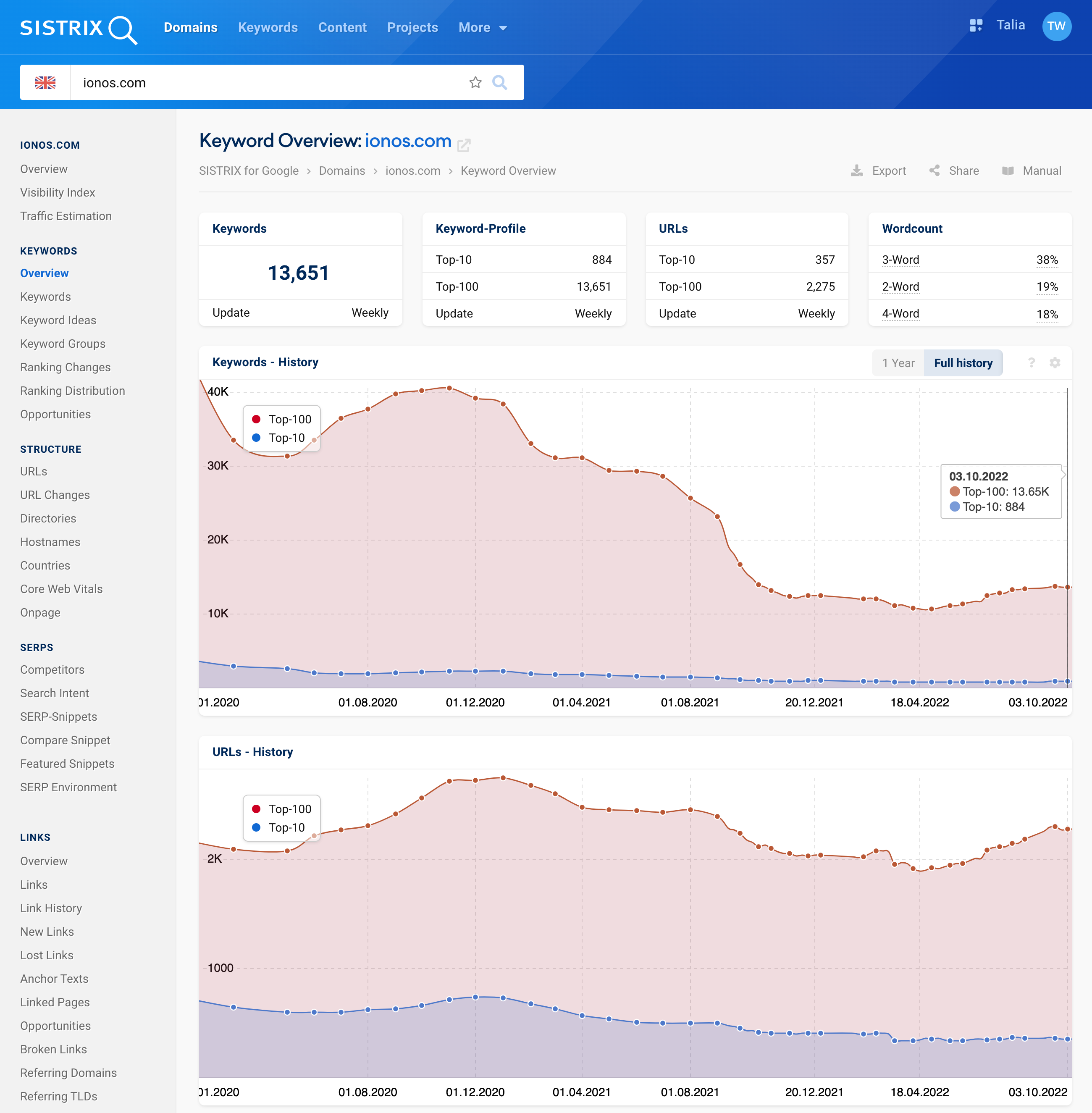
For this, we keep a weekly snapshot of the determined ranking data for each of the last twelve months; for previous points in time, we reduce it to one data point per month.
As usual with SISTRIX, this data can be accessed and analysed not only for entire domains, but also for hostnames (subdomains), paths or individual URLs, even retrospectively over time.
Standard Data for Smartphone and Desktop Still Available
The previously displayed histories based on the Standard Data (one million keywords) for smartphone and desktop SERPs can of course still be used. You can switch between the three data sources at any time in the options menu of the diagram:
When should I use which database?
As is so often the case with search engine optimisation, there is unfortunately no general answer other than “it depends”. Here are the most important advantages and disadvantages of the two database types:
The daily updated data have the advantage of being very current. Here, you immediately see changes through algorithm updates, relaunches and other shifts. They are also statistically comparable over time: there are always one million keywords per country and device.
The disadvantage of the daily updated data is that there are “only” one million keywords. Especially for smaller niche domains, this keyword set does not always cover all special cases, spellings and long-tail keywords. The same applies if you go from the domain to individual directories or even URLs: based on one million keywords, the database can then become somewhat sparse.
This is the advantage of the Extended Data, which is now used as the default for the evaluation: in Germany, for example, this analysis is not based on one million keywords, but on over 100 million. A current list of database sizes for all countries can be found on this page.
The disadvantage of the Extended Data is the update frequency: although all “important” keywords are also updated daily, rarely searched keywords from the long tail are only updated monthly. Therefore, changes in the history of the Extended Data may only become apparent after a few weeks.
We also regularly expand the Extended Database in the supported countries. More keywords also means that the charts go up – without anything having changed in the real status quo. We communicate these extensions of the database and will insert Event-PINs.